Java 线程池有几种创建方式?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道你会不会创建线程池,更是想知道你是否清楚 Java 并发包中线程池的分类和适用场景,能否根据业务特点选择合适的类型。
-
生产实践意识:考察你是否了解
Executors工厂方法的潜在风险(无界队列导致 OOM、无限线程导致系统崩溃),以及为什么阿里开发手册明令禁止在生产环境使用。 -
原理理解深度:如果你只会调用 API 创建,但不理解线程池的执行流程(核心线程 → 队列 → 非核心线程 → 拒绝)和 7 个核心参数的含义,说明只是 “会用” 而非 “懂原理” 。
核心答案
Java 中创建线程池主要有 4 种方式:
| 创建方式 | 核心类 | 适用场景 | 推荐指数 |
|---|---|---|---|
Executors 工厂方法 |
Executors |
快速原型、测试 | ⚠️ 禁止生产使用 |
| 手动构造 | ThreadPoolExecutor |
通用业务场景 | ✅ 强烈推荐 |
| 定时任务 | ScheduledThreadPoolExecutor |
延迟/周期执行 | ✅ 推荐 |
| 分治计算 | ForkJoinPool |
递归分解、并行计算 | ✅ 特定场景 |
一句话总结:生产环境必须使用 ThreadPoolExecutor 手动构造,避免 Executors 的隐患。
深度解析
一、线程池执行流程
在介绍创建方式之前,必须先理解线程池的执行流程,否则参数配置就是 “盲人摸象” 。
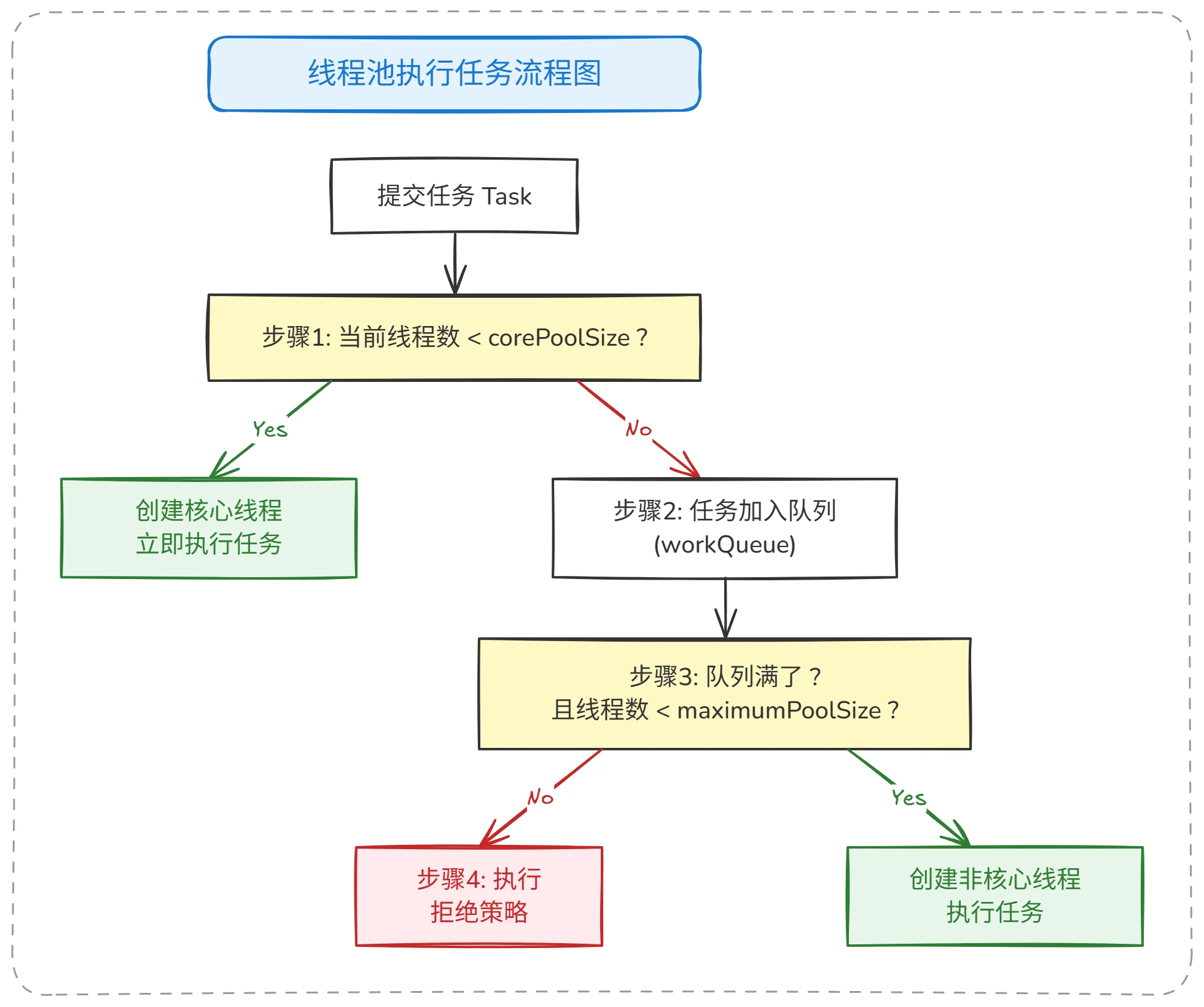
图示讲解:
上图展示了线程池执行任务的完整流程,整体分为 4 个阶段:
-
步骤 1 - 判断核心线程:当有新任务提交时,首先判断当前线程数是否小于核心线程数(
corePoolSize)。如果是,则直接创建新的核心线程来执行任务,不需要排队。这个阶段是 “有人就干活” 。 -
步骤 2 - 加入队列:如果当前线程数已经达到核心线程数,新任务会尝试加入工作队列(
workQueue)。队列起到了 “缓冲” 的作用,让任务先排队等待。 -
步骤 3 - 创建非核心线程:如果队列也满了,且当前线程数小于最大线程数(
maximumPoolSize),则会创建非核心线程来执行任务。这是 “人手不够就招临时工” 的阶段。 -
步骤 4 - 执行拒绝策略:如果队列满了,线程数也达到最大值,就会执行拒绝策略。这是 “实在处理不了就拒绝” 的阶段。
关键点:线程池 不是 “先把线程创建满,再排队” ,而是按照 核心线程 → 队列 → 非核心线程 → 拒绝 的顺序处理任务。这个顺序很重要,它决定了队列的容量会直接影响何时创建非核心线程。
二、方式 1:Executors 工厂方法(⚠️ 生产环境禁止使用)
Executors 类提供了 4 种快捷创建方式,看起来很方便,但都存在严重隐患:
// ❌ 固定大小线程池
ExecutorService fixedPool = Executors.newFixedThreadPool(10);
// ❌ 缓存线程池
ExecutorService cachedPool = Executors.newCachedThreadPool();
// ❌ 单线程池
ExecutorService singlePool = Executors.newSingleThreadExecutor();
// 定时任务线程池
ScheduledExecutorService scheduledPool = Executors.newScheduledThreadPool(5);
问题出在哪里?

图示讲解:
上图展示了 Executors 两种主要工厂方法的内部实现问题:
-
newFixedThreadPool 和 newSingleThreadExecutor 的问题在于使用了
LinkedBlockingQueue,这是一个 无界队列(容量为Integer.MAX_VALUE)。当任务提交速度超过处理速度时,队列会无限增长,最终导致内存溢出(OOM)。 -
newCachedThreadPool 的问题在于最大线程数设置为
Integer.MAX_VALUE,相当于 不限制线程数。配合容量为 0 的SynchronousQueue,每个任务都会创建新线程。在高并发场景下,可能瞬间创建数万个线程,导致 CPU 飙升、系统崩溃。
阿里 Java 开发手册明确规定:线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,规避资源耗尽的风险。
三、方式 2:ThreadPoolExecutor 手动构造(✅ 强烈推荐)
这是生产环境的正确姿势,7 个参数完全由你掌控:
ThreadPoolExecutor executor = new ThreadPoolExecutor(
// ① corePoolSize:核心线程数(常驻线程,即使空闲也不会被回收)
5,
// ② maximumPoolSize:最大线程数 = 核心线程 + 非核心线程
10,
// ③ keepAliveTime:非核心线程空闲后的存活时间
60L,
// ④ unit:存活时间单位
TimeUnit.SECONDS,
// ⑤ workQueue:任务队列(⚠️ 必须有界!)
new ArrayBlockingQueue<>(100),
// ⑥ threadFactory:线程工厂(自定义线程名,方便排查问题)
r -> {
Thread t = new Thread(r, “my-pool-“ + new AtomicInteger(1).getAndIncrement());
t.setDaemon(false); // 用户线程,防止 JVM 提前退出
return t;
},
// ⑦ handler:拒绝策略
new ThreadPoolExecutor.CallerRunsPolicy()
);
7 个核心参数详解:
| 参数 | 含义 | 配置建议 |
|---|---|---|
corePoolSize |
核心线程数(常驻,不回收) | CPU 密集型:N + 1;IO 密集型:2N 或更高 |
maximumPoolSize |
最大线程数(核心 + 非核心) | 不宜过大,一般为核心线程的 1.5~2 倍 |
keepAliveTime |
非核心线程空闲存活时间 | 一般 60 秒足够,太短会频繁创建销毁 |
unit |
时间单位 | TimeUnit.SECONDS |
workQueue |
任务队列 | ⚠️ 必须有界! 推荐 ArrayBlockingQueue |
threadFactory |
线程工厂 | 务必自定义线程名,方便问题排查和监控 |
handler |
拒绝策略(队列满时触发) | 根据业务敏感度选择 |
注:N =
Runtime.getRuntime().availableProcessors()(CPU 核数)
线程数配置的经验公式:
- CPU 密集型(加密、计算、图像处理):线程数 = CPU 核数 + 1
- IO 密集型(网络请求、数据库查询、文件读写):线程数 = CPU 核数 × 2 或更高
- 混合型:根据 IO 等待时间占比调整,公式:
线程数 = N × (1 + 等待时间/计算时间)
四、四种拒绝策略对比
// 1️⃣ AbortPolicy(默认)—— 抛出 RejectedExecutionException
// 适合:关键业务,宁可失败也不能静默丢弃
new ThreadPoolExecutor.AbortPolicy();
// 2️⃣ CallerRunsPolicy —— 由提交任务的线程自己执行
// 适合:削峰填谷,降低提交速度,生产环境推荐
new ThreadPoolExecutor.CallerRunsPolicy();
// 3️⃣ DiscardPolicy —— 静默丢弃,不抛异常
// 适合:非核心业务,日志采集等可丢弃场景
new ThreadPoolExecutor.DiscardPolicy();
// 4️⃣ DiscardOldestPolicy —— 丢弃队列中最老的任务,再尝试提交
// 适合:实时性要求高的场景,老任务可以丢弃
new ThreadPoolExecutor.DiscardOldestPolicy();
| 拒绝策略 | 行为 | 适用场景 |
|---|---|---|
AbortPolicy |
抛异常,快速失败 | 关键业务,需要感知失败 |
CallerRunsPolicy |
调用者线程执行 | 削峰填谷,生产环境推荐 |
DiscardPolicy |
静默丢弃 | 非核心业务,可容忍丢失 |
DiscardOldestPolicy |
丢弃最老任务 | 实时性要求高 |
五、方式 3:ScheduledThreadPoolExecutor(定时任务专用)
适合需要 延迟执行 或 周期性执行 的场景:
// 创建定时任务线程池
ScheduledExecutorService scheduler = new ScheduledThreadPoolExecutor(2);
// ① 延迟执行:3 秒后执行一次
scheduler.schedule(() -> {
System.out.println(“3 秒后执行一次“);
}, 3, TimeUnit.SECONDS);
// ② 固定频率执行(不管上次是否完成)
scheduler.scheduleAtFixedRate(() -> {
System.out.println(“每 5 秒执行一次“);
}, 1, 5, TimeUnit.SECONDS);
// ③ 固定延迟执行(上次执行完后再等待)
scheduler.scheduleWithFixedDelay(() -> {
System.out.println(“执行完后等 5 秒再执行“);
}, 1, 5, TimeUnit.SECONDS);
六、方式 4:ForkJoinPool(分治计算专用)
JDK 7 引入,专门用于 递归分解 的计算密集型任务,采用 工作窃取 算法:
// 示例:大数组求和
ForkJoinPool pool = new ForkJoinPool(4);
long result = pool.invoke(new SumTask(array, 0, array.length));
适用场景:大数组求和、并行排序、树的遍历、矩阵运算等可以递归分解的计算密集型任务。
注意:JDK 8 的 parallelStream() 底层默认使用 ForkJoinPool.commonPool()。
面试高频追问
-
线程池的核心线程数和最大线程数如何配置?
CPU 密集型任务配置 N + 1(N 为 CPU 核数),IO 密集型任务配置 2N 或更高。实际需要结合压测调整。
-
线程池的队列满了怎么办?
会触发拒绝策略。生产环境推荐
CallerRunsPolicy,既能削峰,又不会静默丢弃任务。 -
如何优雅关闭线程池?
使用
shutdown()停止接收新任务 +awaitTermination()等待任务完成。如果超时还没完成,再调用shutdownNow()。 -
核心线程会被回收吗?
默认不会。但可以通过
allowCoreThreadTimeOut(true)设置允许回收。
常见面试变体
- “为什么阿里禁止使用 Executors 创建线程池?”
- “ThreadPoolExecutor 的 7 个参数分别是什么意思?”
- “线程池的拒绝策略有哪些?如何选择?”
- “如何合理配置线程池参数?”
- “线程池的 execute() 和 submit() 有什么区别?”
记忆口诀
执行顺序:核心 → 队列 → 非核心 → 拒绝
通俗理解:先用正式员工(核心线程),忙不过来就排队(队列),队列满了招临时工(非核心线程),实在不行就拒绝(拒绝策略)。
参数记忆:5 个基本参数 + 2 个扩展参数 = 7 个参数
- 基本:核心数、最大数、存活时间、时间单位、队列
- 扩展:线程工厂、拒绝策略
总结
生产环境必须使用 ThreadPoolExecutor 手动构造,避免 Executors 的无界队列和无限线程风险。核心是理解 “核心线程 → 队列 → 非核心线程 → 拒绝” 的执行流程,根据 CPU 密集型(N+1)或 IO 密集型(2N)合理配置线程数,选择有界队列和合适的拒绝策略。