ThreadLocalMap 和 HashMap 的区别?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
源码深度:面试官不仅仅是想让你列几个不同点,更是想知道你是否真正读过 ThreadLocal 的源码,了解它内部为什么没有直接复用
HashMap。 -
数据结构功底:考察你对哈希冲突解决方式的理解——链地址法(
HashMap)和开放定址法(ThreadLocalMap)的对比,以及各自的适用场景。 -
设计权衡意识:为什么
ThreadLocalMap要这样设计?是不是随便选的?考察你是否理解工程中的取舍。
核心答案
先上一张对比表,一目了然:
| 对比维度 | ThreadLocalMap |
HashMap |
|---|---|---|
| 哈希冲突解决 | 开放定址法(线性探测) | 链地址法(数组 + 链表 / 红黑树) |
| 数据结构 | 纯 Entry[] 数组 |
Node[] 数组 + 链表 + 红黑树(JDK 8+) |
| Key 的类型 | 固定为 ThreadLocal<?>(弱引用) |
任意 Object |
| Key 是否可变性 | 不可变(ThreadLocal 对象确定后不变) | 可变(随时 put 不同的 key) |
| 容量 | 必须 2 的幂 | 必须 2 的幂 |
| 扩容阈值 | 2/3(负载因子约为 0.667) |
0.75(默认负载因子) |
| Map 接口 | 不实现 Map 接口 |
实现 Map<K, V> 接口 |
| Null Key | 不允许 | 允许(null key 放在桶 0) |
| 使用场景 | ThreadLocal 内部专用,单线程访问 | 通用键值存储,多线程共享 |
| 过期条目清理 | 主动式(启发式清理 + 全量清理) | 无此机制 |
一句话总结:ThreadLocalMap 是一个为 ThreadLocal 定制的、极度简化的、单线程专用的 Map 实现,用开放定址法解决冲突,用弱引用 key 来辅助 GC 回收。
深度解析
一、哈希冲突解决方式——核心差异
这是两者最根本的区别。
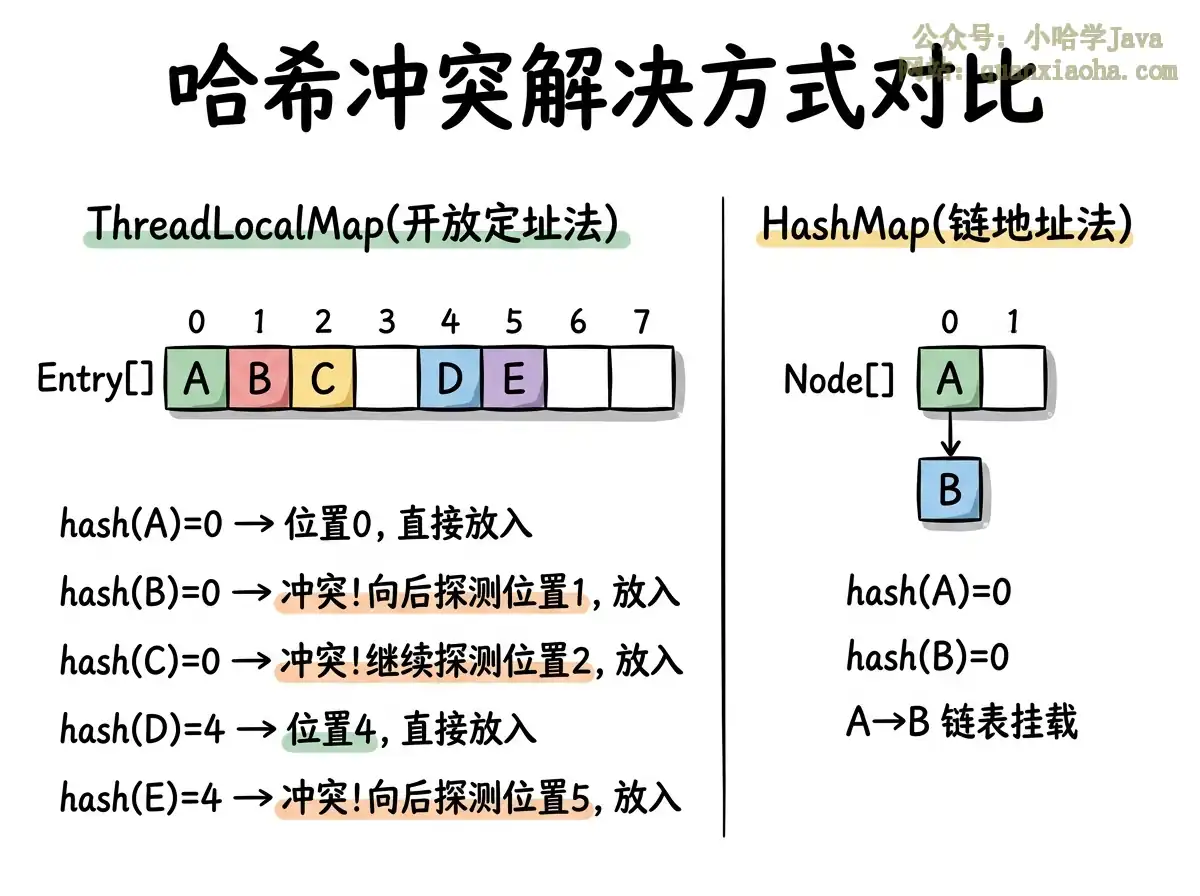
上图对比了两种哈希冲突解决策略的实现方式,核心区别在于:
-
开放定址法(
ThreadLocalMap):当哈希冲突时,不挂链表,而是往后找下一个空位放进去。这种方式的优势是数据全部在数组里,缓存局部性好,访问速度快。缺点是一旦冲突多了,性能下降明显(要一个个往后探测)。所以ThreadLocalMap把负载因子设为2/3而非0.75,就是为了减少冲突概率。 -
链地址法(
HashMap):冲突时在同一个桶位上挂一个链表(JDK 8 链表长度超过 8 还会转红黑树)。优势是对负载因子不敏感,即使比较满也能保持较好的性能。缺点是链表节点内存不连续,缓存不友好。
为什么 ThreadLocalMap 选了开放定址法? 因为 ThreadLocal 的使用特点决定了:每个线程通常只有少量 ThreadLocal 变量,数据量很小。这种场景下开放定址法更简单、更高效、内存开销更小(不需要额外的链表节点对象)。
二、Key 的设计——弱引用是关键
ThreadLocalMap 的 Entry 源码长这样:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k); // key 是弱引用!
value = v; // value 是强引用
}
}
而 HashMap 的 Node 源码是这样的:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key; // key 是强引用
V value;
Node<K,V> next; // 链表后继指针
// ...
}
这个差异非常关键:
-
ThreadLocalMap的 key 是弱引用:当外部的ThreadLocal引用被置为null后,GC 会回收这个 ThreadLocal 对象,此时 Entry 的 key 变成null。这就是所谓的 "脏 Entry"(stale entry),ThreadLocalMap会在get()、set()、remove()时顺带清理这些脏 Entry。 -
HashMap的 key 是强引用:key 只要还在 Map 里,就不会被 GC。
设计成弱引用的目的是:万一你忘记调用 remove(),至少 ThreadLocal 对象本身能被回收,不至于泄漏整个 ThreadLocal 对象。但 value 依然是强引用,所以还是会有 value 的泄漏,这也是为什么必须养成 remove() 的习惯。
三、为什么 ThreadLocalMap 不直接用 HashMap?
很多人会有这个疑问——JDK 里不是已经有现成的 HashMap 了吗?为什么不直接用?
原因有三个:
-
功能过度:
HashMap支持任意 key、支持nullkey、支持遍历、支持size()等一大堆功能,ThreadLocal 根本不需要。自己造一个精简版,代码量少、维护简单。 -
内存开销:
HashMap的每个Node多了hash字段和next指针,对于 ThreadLocal 这种 "每个线程可能就存几个变量" 的场景,这些额外开销完全没有必要。 -
弱引用需求:
HashMap不支持弱引用 key,如果要用就得自己处理,还不如从头定制一个。
四、过期 Entry 的清理机制
这是 ThreadLocalMap 独有的机制,HashMap 完全没有这个概念。

上图展示了 ThreadLocalMap 的两层清理机制,具体来说:
-
启发式清理(
expungeStaleEntry):从某个位置开始,向后扫描一段连续的区域,遇到null槽位就停止。清理过程中发现的脏 Entry 会被清除,同时把后面有效的 Entry 重新 hash(rehash)到更接近其理想位置的地方。这种清理是轻量级的,每次操作触发,开销小。 -
全量清理(
cleanSomeSlots):对整个 table 做扫描,清除所有脏 Entry。这个操作比较重,不会每次都触发,而是在set()时根据启发式判断是否需要执行(比如探测次数超过阈值时)。
这套机制的设计初衷是:即使你没有手动 remove(),ThreadLocalMap 也会在日常操作中帮你 "顺手" 清理掉一些泄漏的 Entry。但这只是 兜底机制,不是让你不用 remove() 的理由。
面试高频追问
-
追问一:ThreadLocalMap 为什么用开放定址法而不是链地址法?
ThreadLocal 的典型使用场景是每个线程只存少量变量(通常几个到十几个),数据量很小。开放定址法在数据量小时缓存局部性更好、内存开销更小(不需要额外的链表节点)。而
HashMap面对的是通用场景,数据量不可控,链地址法在高负载时性能更稳定。 -
追问二:ThreadLocalMap 的负载因子为什么是 2/3 而不是 HashMap 的 0.75?
开放定址法对冲突更敏感——一旦冲突,就要线性往后探测,性能下降比链地址法快得多。所以用更低的负载因子(
2/3 ≈ 0.667 < 0.75)来降低冲突概率,牺牲一点空间换性能。 -
追问三:ThreadLocal 的 key 用弱引用就能避免内存泄漏了吗?
不能完全避免。弱引用只保证 ThreadLocal 对象本身能被回收(key 变成
null),但 value 依然是强引用,不会被 GC。如果线程长期存活(线程池),这些nullkey 对应的 value 就泄漏了。ThreadLocalMap 的清理机制只是兜底,最可靠的方式还是用完调用remove()。
常见面试变体
- "ThreadLocal 的底层数据结构是什么?"
- "ThreadLocalMap 是怎么解决哈希冲突的?"
- "为什么 ThreadLocal 不直接用 HashMap?"
- "ThreadLocalMap 的 key 为什么要用弱引用?"
记忆口诀
ThreadLocalMap 三句话:开放定址解冲突、弱引用 key 防 ThreadLocal 泄漏、启发式清理做兜底。对比记忆:HashMap 是 "链地址 + 红黑树 + 强引用"。
总结
ThreadLocalMap 是一个为 ThreadLocal 定制的极简 Map,核心特征就三个:开放定址法(适合少量数据的场景)、弱引用 key(防止 ThreadLocal 对象自身泄漏)、内置清理机制(兜底处理脏 Entry)。理解了 "为什么不用 HashMap" 这个问题,面试官就知道你不仅用过 ThreadLocal,还读过源码。