什么是线程死锁,如何排查?如何解决?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
概念理解:面试官不仅仅是想知道 "两个线程互相等对方释放锁" 这句话,更是想看你能不能说清楚死锁产生的 四个必要条件。能说出这四个条件,说明你的理解是成体系的,不是碎片化的。
-
排查能力:线上出了死锁你怎么定位?能不能熟练使用
jstack、jconsole、Arthas这些工具?这块区分度很大,实际排查过死锁的候选人回答起来明显更有底气。 -
预防意识:考察你是否掌握了死锁的预防策略,以及在日常编码中是否有意识地去避免死锁。能主动提及锁排序、超时机制这些方案的候选人,面试官会给加分。
核心答案
死锁 是指两个或多个线程互相持有对方需要的锁,又都不肯释放自己手中的锁,导致所有线程永远阻塞的现象。
先来看一个最经典的死锁代码:
public class DeadlockDemo {
private static final Object lockA = new Object();
private static final Object lockB = new Object();
public static void main(String[] args) {
// 线程 1:先拿 lockA,再请求 lockB
new Thread(() -> {
synchronized (lockA) {
System.out.println("Thread-1 持有 lockA,等待 lockB");
try { Thread.sleep(100); } catch (InterruptedException e) {}
synchronized (lockB) {
System.out.println("Thread-1 获得锁");
}
}
}, "Thread-1").start();
// 线程 2:先拿 lockB,再请求 lockA
new Thread(() -> {
synchronized (lockB) {
System.out.println("Thread-2 持有 lockB,等待 lockA");
try { Thread.sleep(100); } catch (InterruptedException e) {}
synchronized (lockA) {
System.out.println("Thread-2 获得锁");
}
}
}, "Thread-2").start();
}
}
运行后程序永远不会结束——Thread-1 拿着 lockA 等 lockB,Thread-2 拿着 lockB 等 lockA,谁也动不了。
深度解析
一、死锁产生的四个必要条件
死锁不是随便就能发生的,必须 同时满足 以下四个条件:
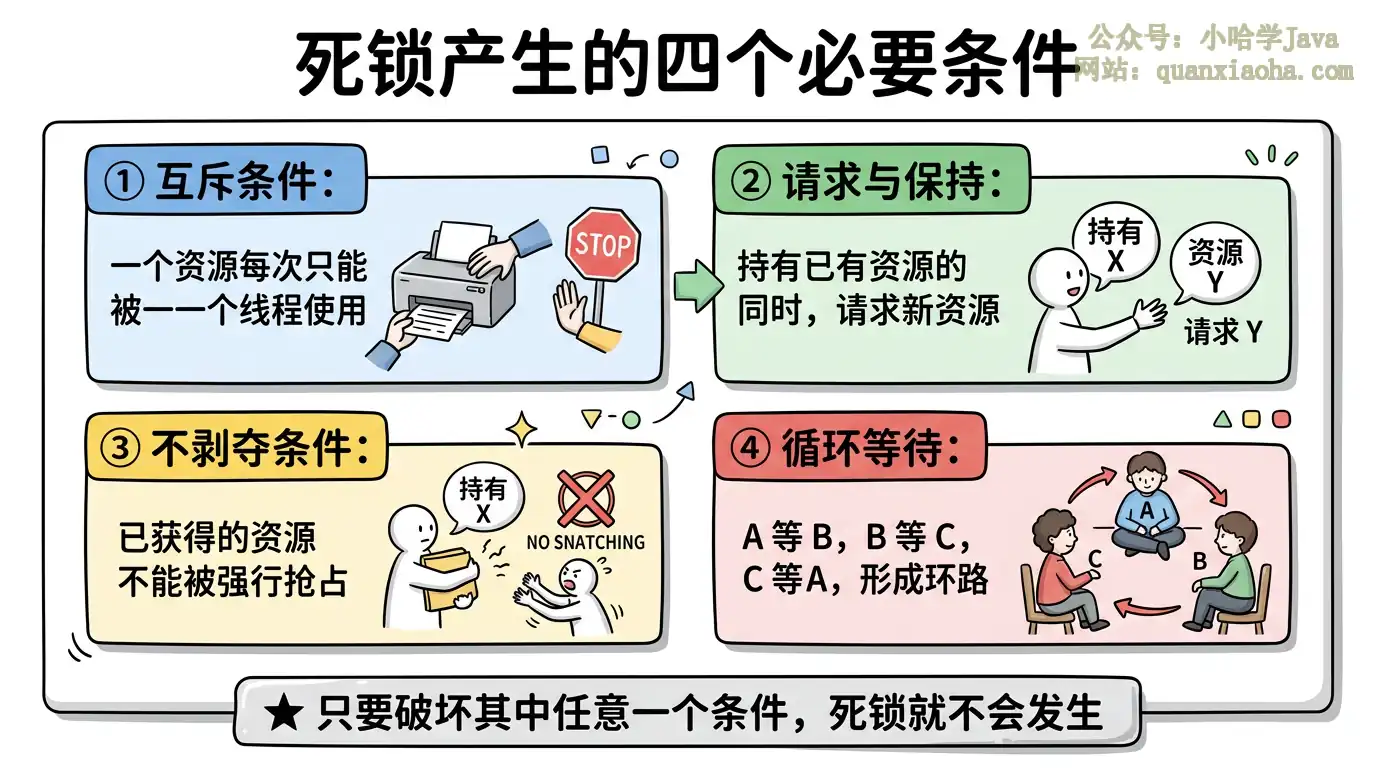
上图展示了死锁产生的四个必要条件。逐个解释:
-
① 互斥条件:锁本身就是互斥的,同一时刻只能被一个线程持有。这个条件是锁的基本特性,基本没法破坏(除非不用锁)。
-
② 请求与保持:线程已经持有至少一把锁,还在请求另一把锁,且不释放已经持有的锁。上面的代码就是典型的 "请求与保持"——Thread-1 拿着 lockA 不放,还去请求 lockB。
-
③ 不剥夺条件:线程已经获得的锁不能被其他线程强制抢占,只能由持有者自己释放。
synchronized就是这样,拿到锁后别人没法让你交出来。 -
④ 循环等待:多个线程之间形成环形等待链——A 等 B 的锁,B 等 A 的锁。这是死锁最直观的表现。
关键点:四个条件必须同时成立才会死锁,只要破坏其中任意一个,死锁就能被打破。实际开发中我们主要破坏 ② 和 ④。
二、如何排查死锁?
线上系统出现死锁,通常的表现是:某些接口响应极慢甚至完全卡死,CPU 使用率不高(因为线程都阻塞了),线程 dump 中能看到大量的 BLOCKED 状态线程。
方法一:jstack 命令(最常用)
# 1. 先找到 Java 进程 PID
jps -l
# 输出:12345 DeadlockDemo
# 2. 用 jstack 打印线程堆栈
jstack 12345
输出中会明确告诉你发现死锁:
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x0000... (object 0x0000..., a java.lang.Object),
which is held by "Thread-2"
"Thread-2":
waiting to lock monitor 0x0000... (object 0x0000..., a java.lang.Object),
which is held by "Thread-1"
Java stack information for the threads listed above:
===================================================
"Thread-1":
at DeadlockDemo.lambda$main$0(DeadlockDemo.java:12)
- waiting to lock <0x0000...> (a java.lang.Object)
- locked <0x0000...> (a java.lang.Object)
"Thread-2":
at DeadlockDemo.lambda$main$1(DeadlockDemo.java:22)
- waiting to lock <0x0000...> (a java.lang.Object)
- locked <0x0000...> (a java.lang.Object)
jstack 会直接帮你找到死锁的线程和具体的代码行号,非常直观。
方法二:jconsole / VisualVM(图形化)
如果你能连到服务器(或者本地开发环境),用 jconsole 或 VisualVM 打开,在 "线程" 面板点击 "检测死锁" 按钮,就能看到哪些线程发生了死锁。图形化界面比命令行更直观,适合本地调试。
方法三:Arthas(线上诊断利器)
# 安装并启动 Arthas
java -jar arthas-boot.jar
# 查看线程死锁
thread -b
thread -b 会直接打印阻塞其他线程的线程信息,包括持有哪些锁、阻塞了谁。阿里开源的 Arthas 在线上问题排查中真的太好用了,强烈推荐掌握。
方法四:代码层面检测
// ThreadMXBean 可以编程式检测死锁
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
long[] deadlockedThreads = threadMXBean.findDeadlockedThreads();
if (deadlockedThreads != null) {
ThreadInfo[] threadInfos = threadMXBean.getThreadInfo(deadlockedThreads);
// 记录日志、告警
}
可以在监控系统中定时检测,发现死锁自动告警。
三、如何解决和预防死锁?
上面说了,破坏四个必要条件中的任意一个就能打破死锁。实际开发中有以下几种常用策略:
策略一:固定加锁顺序(破坏循环等待)
这是最简单也最有效的方式——所有线程都按 相同的顺序 获取锁。
// 修复后的代码:两个线程都先 lockA 再 lockB
public static void main(String[] args) {
// 线程 1:先 lockA,再 lockB
new Thread(() -> {
synchronized (lockA) {
synchronized (lockB) {
// 业务逻辑
}
}
}).start();
// 线程 2:也是先 lockA,再 lockB(顺序一致)
new Thread(() -> {
synchronized (lockA) {
synchronized (lockB) {
// 业务逻辑
}
}
}).start();
}
两个线程都先请求 lockA 再请求 lockB,不会出现 "一个先 A 后 B、另一个先 B 后 A" 的交叉等待,循环等待条件被打破。实际开发中,可以按锁对象的 hashCode 值大小来确定加锁顺序。
策略二:使用 tryLock 超时机制(破坏不剥夺条件)
ReentrantLock lockA = new ReentrantLock();
ReentrantLock lockB = new ReentrantLock();
try {
// 尝试获取 lockA,最多等 3 秒
if (lockA.tryLock(3, TimeUnit.SECONDS)) {
try {
// 获取到 lockA 后,尝试获取 lockB
if (lockB.tryLock(3, TimeUnit.SECONDS)) {
try {
// 两把锁都拿到了,执行业务逻辑
} finally {
lockB.unlock();
}
} else {
// 获取 lockB 超时,主动放弃 lockA
System.out.println("获取 lockB 超时,放弃操作");
}
} finally {
lockA.unlock();
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
tryLock 在指定时间内获取不到锁就返回 false,主动放弃已经持有的锁。这就打破了 "不剥夺条件"——锁虽然没有被外部强制抢占,但线程自己超时放弃了,效果一样。synchronized 做不到这一点,这也是 ReentrantLock 的一大优势。
策略三:减小锁粒度,缩小同步范围
锁的代码块越大,持有锁的时间越长,死锁概率就越高。尽量把不需要同步的操作移到同步块外面:
// 不好:整个方法都加锁,持有锁时间太长
synchronized (lock) {
prepareData(); // 不需要锁
updateShared(); // 需要锁
sendNotify(); // 不需要锁
}
// 好:只锁必要的部分
prepareData();
synchronized (lock) {
updateShared();
}
sendNotify();
策略四:避免嵌套锁
能不用嵌套锁就不用。如果必须在一个锁里请求另一个锁,说明设计可能有问题,考虑重构一下逻辑,把嵌套锁拆成独立的锁操作。
四、四种策略对比
| 策略 | 破坏哪个条件 | 实现难度 | 推荐程度 |
|---|---|---|---|
| 固定加锁顺序 | 循环等待 | 简单 | ✅ 首选 |
tryLock 超时 |
不剥夺条件 | 中等 | ✅ 推荐 |
| 减小锁粒度 | 请求与保持 | 简单 | ✅ 好习惯 |
| 避免嵌套锁 | 请求与保持 | 需设计 | ✅ 最佳实践 |
生产环境最常用的就是 固定加锁顺序 + tryLock 超时 的组合拳,基本上能把死锁风险降到很低。
面试高频追问
-
死锁和活锁有什么区别?
- 死锁是线程阻塞不动了;活锁是线程没阻塞但在不停地重试失败(比如两个线程互相让步,都拿不到锁),本质上是 "忙但没进展"。
-
数据库也会有死锁吗?怎么处理?
- 会。数据库的死锁检测更成熟——MySQL InnoDB 会自动检测死锁并回滚其中一个事务。应用层也可以通过
tryLock超时来避免。
- 会。数据库的死锁检测更成熟——MySQL InnoDB 会自动检测死锁并回滚其中一个事务。应用层也可以通过
-
synchronized能检测死锁吗?synchronized本身不能,但可以通过jstack、ThreadMXBean等外部工具来检测。ReentrantLock的tryLock则可以从编码层面主动避免死锁。
常见面试变体
- "写一个死锁的代码示例"
- "线上出了死锁你怎么排查?"
- "如何预防死锁?"
- "
synchronized和ReentrantLock哪个更容易出现死锁?"
记忆口诀
死锁四条件:互斥、请求保持、不剥夺、循环等待。破坏任意一个,死锁不成立。
预防三板斧:锁排序(固定顺序)、锁超时(tryLock)、锁最小化(缩小范围)。
总结
面试答死锁,三层递进:先说清楚什么是死锁和四个必要条件,再讲排查手段(jstack、Arthas),最后重点展开预防策略(固定加锁顺序 + tryLock 超时)。如果能在回答中穿插一段自己线上排查死锁的经历,面试官基本就稳了。