介绍一下 Tomcat 的 IO 模型?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
IO 基础功底:面试官不仅仅是想知道 Tomcat 支持哪些 IO 模型,更是想看你对 BIO、NIO、AIO 这些底层概念是不是真的理解了,还是只会背个名字。很多人答 "Tomcat 用的是 NIO",但问他 NIO 具体怎么做到非阻塞的,就卡壳了。
-
Tomcat 架构认知:是否清楚 Tomcat 从 6 到 10 这几个大版本中 IO 模型的演进路线,为什么 BIO 被淘汰、APR 是怎么提升性能的。
-
生产实践:能不能根据实际业务场景选择合适的 IO 模型和 Connector 配置,而不是 "默认就好"。
核心答案
Tomcat 支持 3 种 IO 模型,分别对应三种 ProtocolHandler 实现:
| IO 模型 | ProtocolHandler | 核心原理 | 性能表现 |
|---|---|---|---|
| BIO | Http11Protocol |
阻塞式 IO,一个连接一个线程 | 低(已废弃) |
| NIO | Http11NioProtocol |
基于 Java NIO,多路复用 | 高 |
| APR | Http11AprProtocol |
基于 Apache 可移植运行时库,调用操作系统原生 API | 最高 |
从 Tomcat 8.5 开始,BIO 已被正式移除,NIO 成为默认选项。Tomcat 9+ 还支持 NIO.2(Http11Nio2Protocol),底层用的是 JDK 7 引入的异步 IO(AIO)。
生产环境的话,能装 APR 就装 APR,装不了就用 NIO,基本也够用了。
深度解析
一、BIO——一个连接一个线程,说拜拜了
BIO 是最原始的模型。工作方式非常简单粗暴:每个进来的 TCP 连接,Tomcat 都会分配一个独立线程来处理,线程在读写数据时是阻塞的。
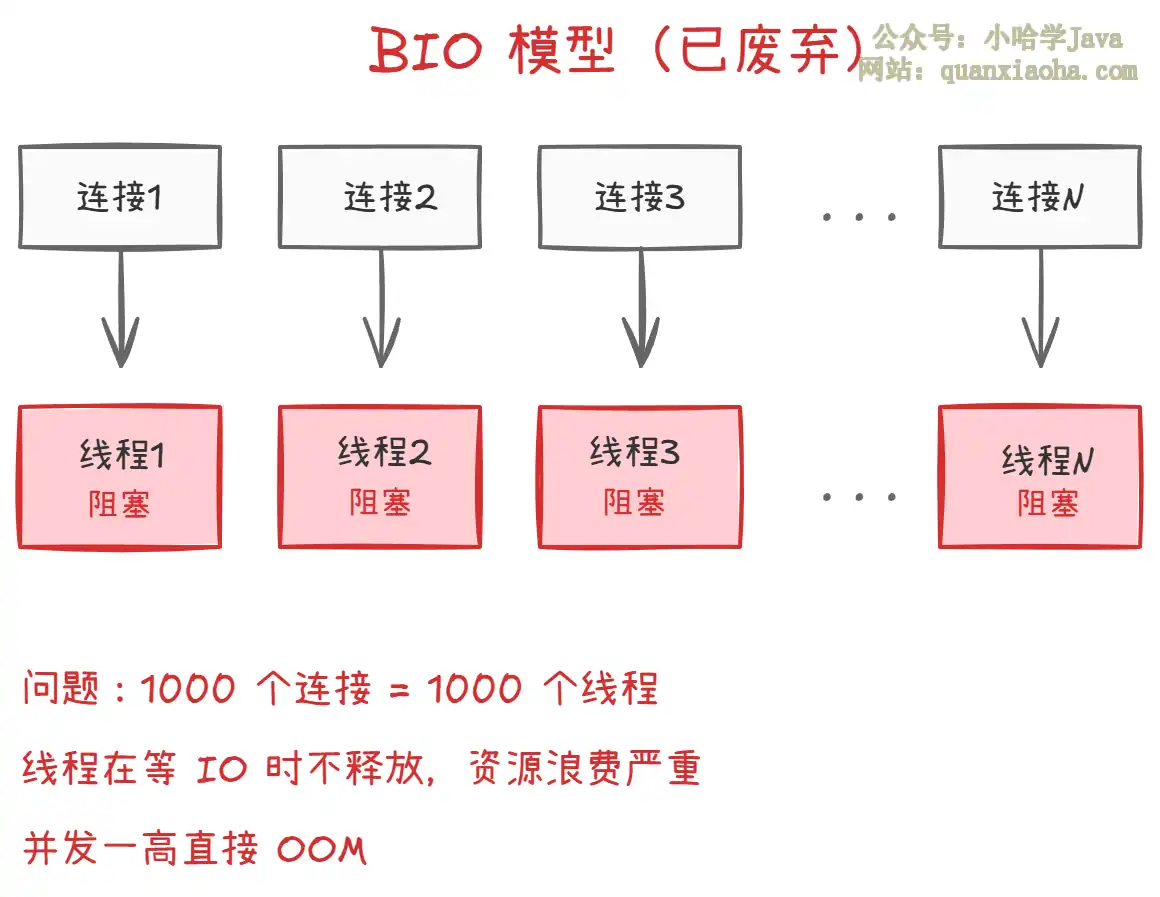
上图展示了 BIO 模型的工作方式:
-
一个连接对应一个线程:每当有新的 TCP 连接进来,Tomcat 的 Acceptor 线程接受连接后,会把该连接交给一个独立的工作线程(从线程池取或新建)。这个工作线程负责完成 HTTP 请求的读取、Servlet 调用、响应写回整个过程。
-
全程阻塞:工作线程在读请求体、写响应的时候都是阻塞的。如果客户端网络慢、发送数据慢,线程就一直等着,啥也干不了。
-
致命问题:假设你有 1000 个并发连接(很多可能只是 "挂着" 但没发数据),就需要 1000 个线程。每个线程栈默认 1MB,光线程栈就吃掉 1GB 内存。而且线程上下文切换的开销也非常大。
这就是为什么 Tomcat 8.5 把 BIO 干掉了——高并发场景下实在扛不住。
二、NIO——多路复用,Tomcat 的默认选择
NIO 是目前 Tomcat 的默认 IO 模型,也是面试官最想听你展开讲的部分。
核心思想:不再一个连接一个线程,而是用一个线程通过 Selector 轮询多个连接,哪个连接有数据可读了再去处理。
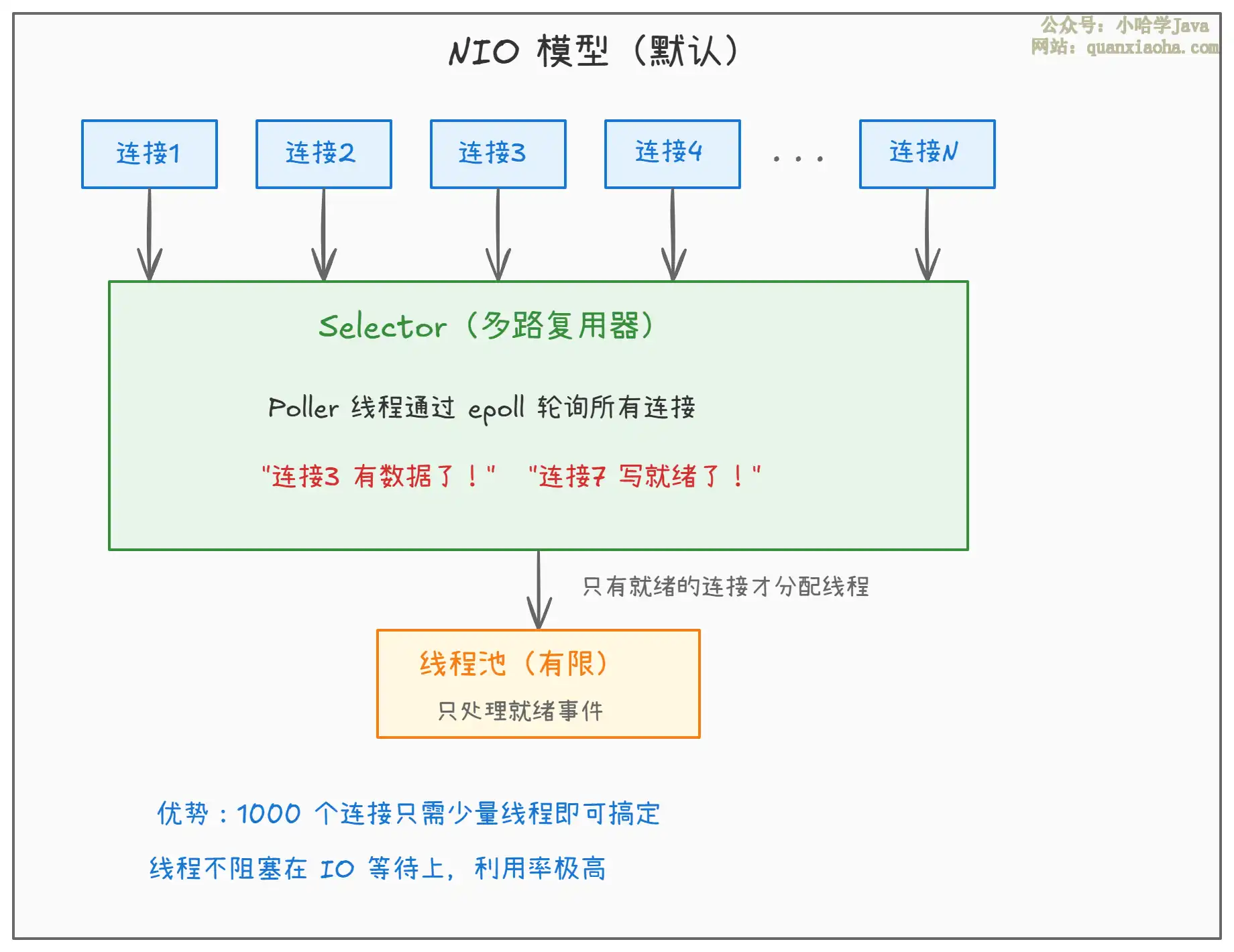
上图展示了 NIO 的核心架构:
-
Selector 多路复用:Tomcat 里把这个角色叫做
Poller。一个Poller线程可以同时监控上千个连接的状态(读就绪、写就绪、新连接等),底层在 Linux 上用的是epoll系统调用。只有当某个连接真正有数据可读或可写时,Poller才会把这个连接交给线程池去处理。 -
线程不浪费:1000 个连接中可能只有 50 个同时有数据要处理,那线程池只需要 50 个线程就够了。剩下 950 个 "闲着" 的连接不占任何线程资源,只是注册在 Selector 上而已。
-
非阻塞读写:通过
Channel+Buffer的方式读写数据,不会因为客户端慢而阻塞线程。
这块确实绕,我当年也理解了好几遍。核心就记住一句话:BIO 是 "你慢我也等你",NIO 是 "谁好了我处理谁"。
三、Tomcat NIO 的线程模型
光知道 NIO 用了 Selector 还不够,Tomcat 实际的线程模型比上面画的更精细一些:
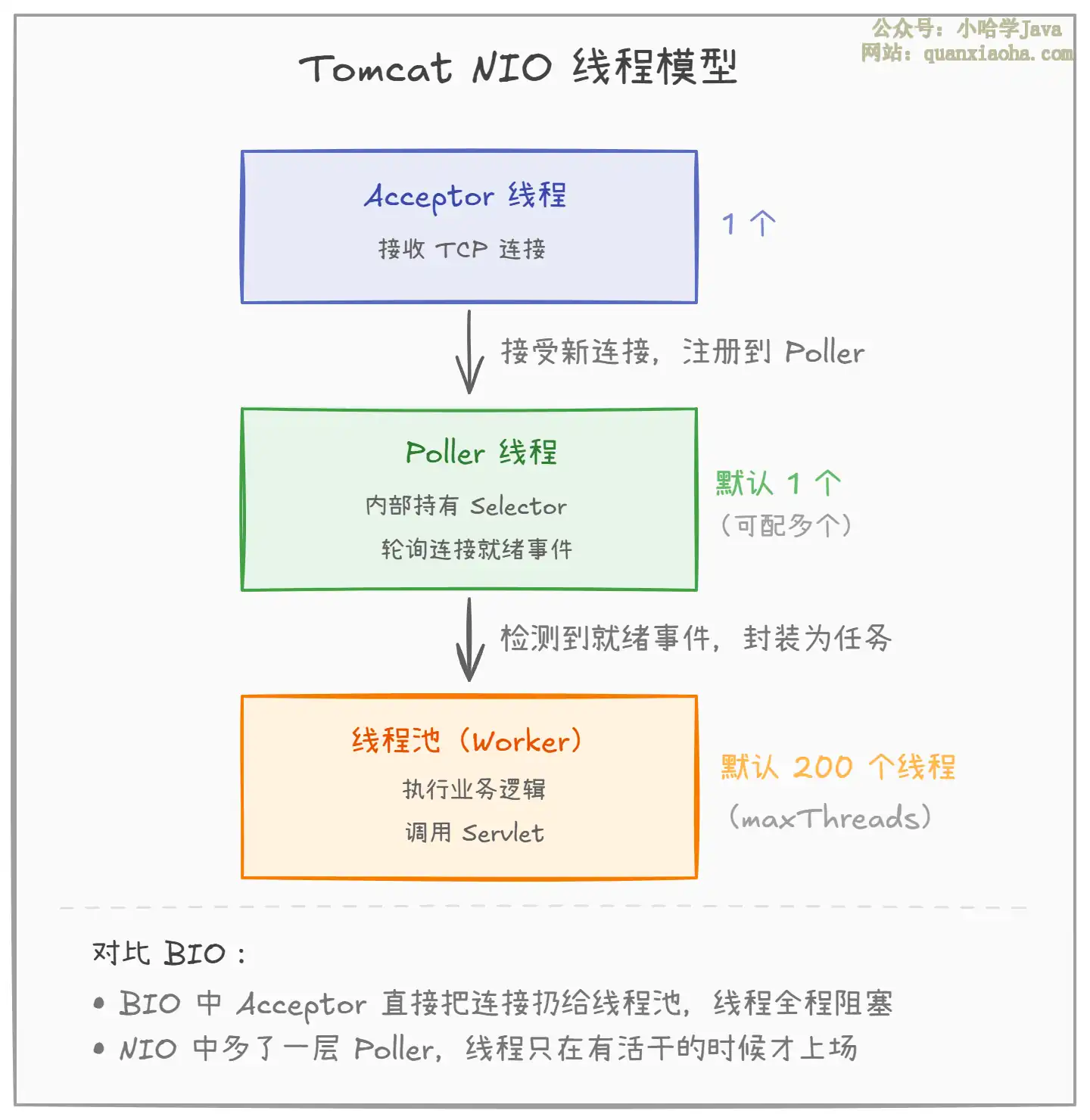
Tomcat NIO 模型整体分三个角色:
-
Acceptor 线程:负责接收新来的 TCP 连接(
ServerSocketChannel.accept()),接收后把连接注册到Poller的事件队列中。只有一个线程干这事,足够了,因为accept操作非常快。 -
Poller 线程:内部持有一个
Selector,通过epoll_wait轮询注册在上面的所有连接。当某个连接有数据可读时,Poller把这个连接封装成一个任务(SocketProcessor),扔给线程池执行。默认 1 个Poller,多核机器可以配置多个。 -
Worker 线程池:就是
maxThreads控制的那个线程池,负责真正执行 Servlet 业务逻辑。一个请求进来后,在这个线程里走完 Filter 链 → Servlet → 响应回写的整个流程。
和 BIO 的本质区别:BIO 里一个连接从建立到断开,一直占着一个线程;NIO 里线程只在有数据需要处理时才上场,处理完就把连接还回给 Poller 继续监听。
四、APR——调用操作系统原生 API,性能天花板
APR(Apache Portable Runtime)本质上就是让 Tomcat 通过 JNI 调用 C 语言写的本地库,绕过 Java 这一层,直接用操作系统的最高性能 IO 接口。
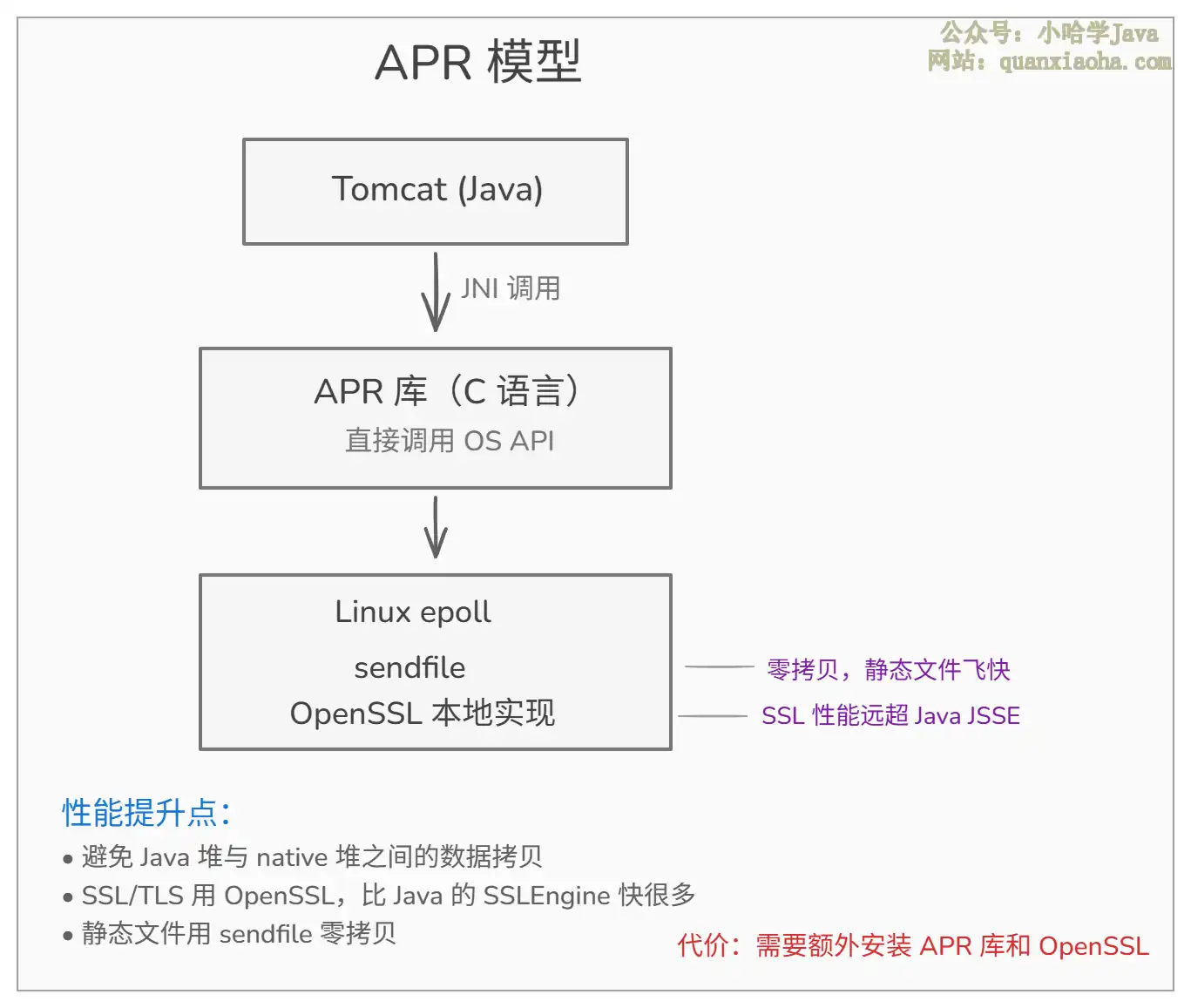
APR 的核心优势在于:
-
减少数据拷贝:Java NIO 在读写时数据要在 JVM 堆和操作系统内核缓冲区之间来回拷贝,APR 直接在 native 层操作,省掉了这部分开销。
-
SSL 性能提升:用 OpenSSL 的 C 实现替代 Java 的
SSLEngine,HTTPS 场景下性能提升非常明显。这对线上环境很重要,毕竟现在全站 HTTPS 是标配。 -
sendfile 零拷贝:处理静态资源时可以直接用操作系统的
sendfile系统调用,数据从磁盘直接到网卡,不经过用户态。
代价就是要额外安装 libtcnative 库,部署运维稍微麻烦一点。
五、三种模型怎么选?
| 场景 | 推荐 | 理由 |
|---|---|---|
| 一般 Web 应用 | NIO | 默认配置,开箱即用,性能已经很好 |
| 高并发 + HTTPS | APR | SSL 性能优势明显,减少 CPU 开销 |
| 大量静态资源 | APR | sendfile 零拷贝,静态文件吞吐量高 |
| Docker/K8s 容器 | NIO | 容器内装 APR 库麻烦,NIO 性能足够 |
| 开发/测试环境 | NIO | 没必要折腾 APR,NIO 够用 |
实际生产中,90% 的场景 NIO 就够了。只有当你碰到 SSL 性能瓶颈或者对静态资源吞吐量有极端要求时,才值得花精力去装 APR。
六、NIO.2(AIO)是怎么回事?
Tomcat 9+ 还支持 Http11Nio2Protocol,底层用的是 JDK 7 引入的 AsynchronousSocketChannel,也就是真正的异步 IO(AIO)。
听上去很美好对吧?但实际性能并没有比 NIO 好多少。原因是 Linux 下的 AIO 底层仍然是用 epoll 模拟的(真正的 AIO 只有 Windows 的 IOCP 才有),所以并没有本质的提升。目前 Tomcat 官方也没有把 NIO.2 作为默认选择,NIO 依然是主流。
面试高频追问
-
追问一:Tomcat NIO 中
Poller线程的作用是什么?和Selector是什么关系?Poller本质上就是一个线程 + 一个Selector。它不断调用selector.select()来检测哪些连接有数据可读,然后把这些 "就绪" 的连接交给 Worker 线程池处理。可以理解为一个 "侦察兵",负责发现哪些连接需要处理,但不负责具体处理。 -
追问二:为什么 Tomcat 8.5 要移除 BIO?
因为 BIO 在高并发下的表现太差了。C10K 问题(1 万个并发连接)在 BIO 下需要 1 万个线程,内存和上下文切换开销完全不可接受。而 NIO 用少量线程 + 多路复用就能轻松应对,BIO 被淘汰是必然的。
-
追问三:NIO 的
epoll是什么?为什么性能好?epoll是 Linux 内核提供的一种高效 IO 多路复用机制。相比老式的select/poll每次都要遍历所有连接,epoll只返回 "有事件发生的连接",时间复杂度从 O(n) 降到了 O(活跃连接数)。而且epoll用红黑树管理连接,支持百万级连接。
常见面试变体
- "Tomcat 默认用的什么 IO 模型?为什么?"
- "BIO 和 NIO 的本质区别是什么?Tomcat 是怎么用 NIO 的?"
- "Tomcat 的
maxThreads参数在 BIO 和 NIO 下有什么不同含义?"
记忆口诀
BIO 一连一线程,NIO 一线程管多连,APR 越过 JVM 调原生。
三种模型一句话概括:BIO 是 "人等活",NIO 是 "活找人",APR 是 "不走中间商"。
总结
Tomcat 支持 BIO(已废弃)、NIO(默认)、APR(最高性能)三种 IO 模型。核心区别在于 BIO 是阻塞的一连接一线程,NIO 通过 Selector 多路复用实现少量线程处理大量连接,APR 通过 JNI 调用操作系统原生接口进一步减少 Java 层的开销。生产环境 NIO 是主流选择,高并发 HTTPS 场景可以考虑 APR。面试时把 "BIO 为什么被淘汰" 和 "NIO 的 Selector 多路复用原理" 讲清楚,这道题就稳了。