什么是 MySQL 回表查询?如何避免?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
索引原理理解:面试官不仅仅是想知道 "回表" 这个概念,更是想考察你是否理解 InnoDB 的聚簇索引和二级索引的区别,以及 B+ 树的存储结构。
-
性能优化意识:回表会带来额外的 I/O 开销,考察你是否具备 "减少回表次数" 的优化思维,能否在实际开发中设计出高效的索引。
-
覆盖索引应用:考察你是否掌握 "覆盖索引" 这一核心优化手段,以及如何通过
EXPLAIN命令判断是否发生了回表。
核心答案
回表查询:当通过二级索引(非主键索引)查询数据时,如果 SELECT 的字段不完全包含在索引中,MySQL 需要先从二级索引树查到主键 ID,再回到聚簇索引树根据 ID 查找完整记录,这个过程叫 "回表"。
核心对比:
| 查询类型 | 索引类型 | 是否回表 | 性能 |
|---|---|---|---|
| 主键查询 | 聚簇索引 | ❌ 不需要 | ⭐⭐⭐⭐⭐ 最快 |
| 覆盖索引查询 | 二级索引(字段全覆盖) | ❌ 不需要 | ⭐⭐⭐⭐ 快 |
| 普通二级索引查询 | 二级索引(字段未覆盖) | ✅ 需要回表 | ⭐⭐⭐ 较慢 |
一句话总结:回表的本质是 "二级索引 → 聚簇索引" 的二次查找,通过 覆盖索引 可以避免。
深度解析
一、InnoDB 索引结构:理解回表的前提
要理解回表,首先要理解 InnoDB 的两种索引结构:
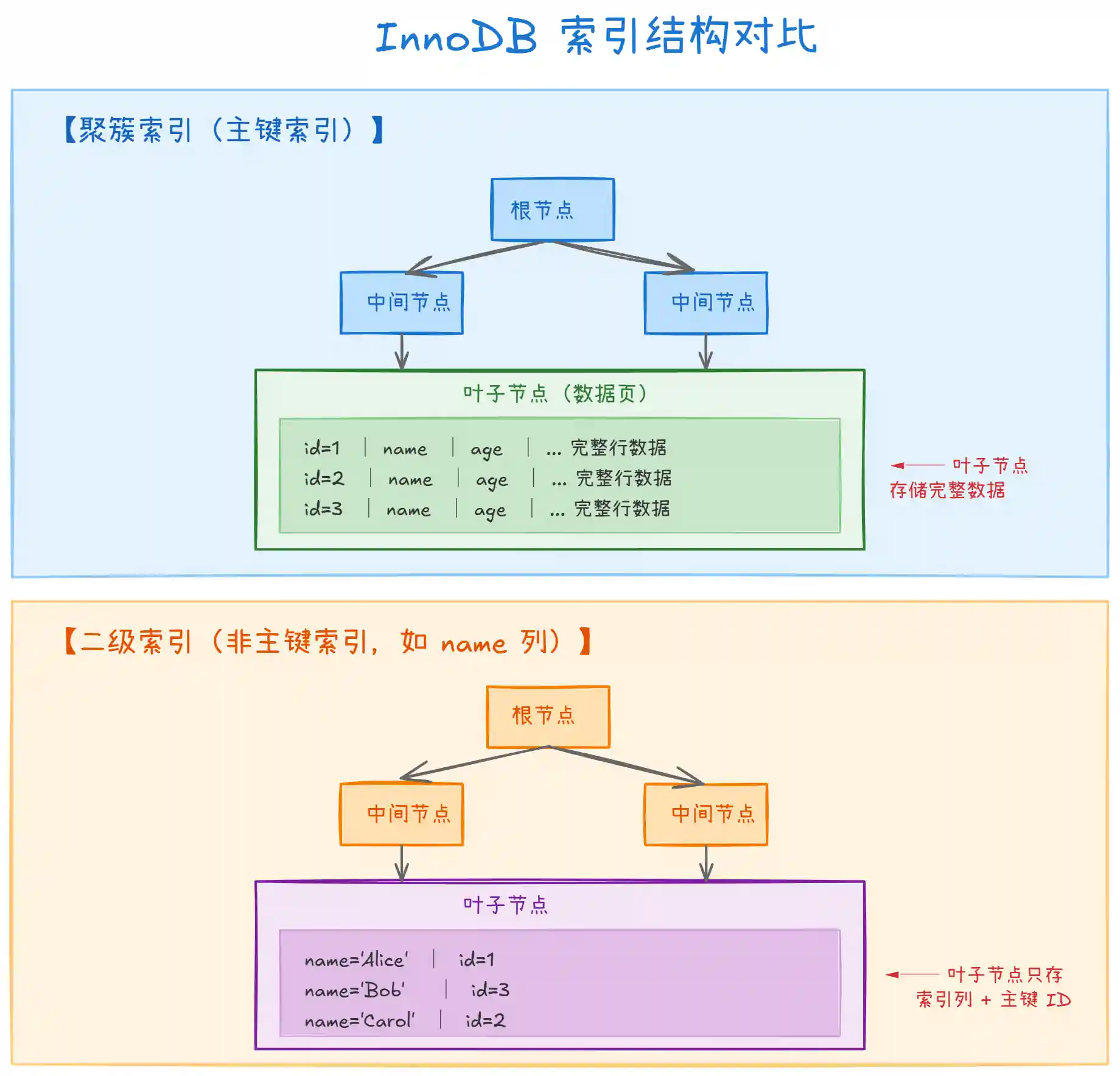
上图对比了聚簇索引和二级索引的结构差异。关键区别在于:
- 聚簇索引(主键索引):叶子节点存储的是 完整的行数据,通过主键可以直接获取所有字段
- 二级索引(非主键索引):叶子节点只存储 索引列的值 + 主键 ID,不包含其他字段
这就是为什么二级索引查询可能需要 "回表" —— 因为它没有完整的行数据!
二、回表过程演示
假设有一张用户表:
CREATE TABLE user (
id INT PRIMARY KEY, -- 主键
name VARCHAR(50), -- 姓名
age INT, -- 年龄
INDEX idx_name (name) -- name 列的二级索引
);
-- 插入测试数据
INSERT INTO user VALUES (1, 'Alice', 25);
INSERT INTO user VALUES (2, 'Bob', 30);
INSERT INTO user VALUES (3, 'Carol', 28);
场景:通过 name 查询完整数据
SELECT * FROM user WHERE name = 'Bob';
这个查询会发生回表,执行过程如下:
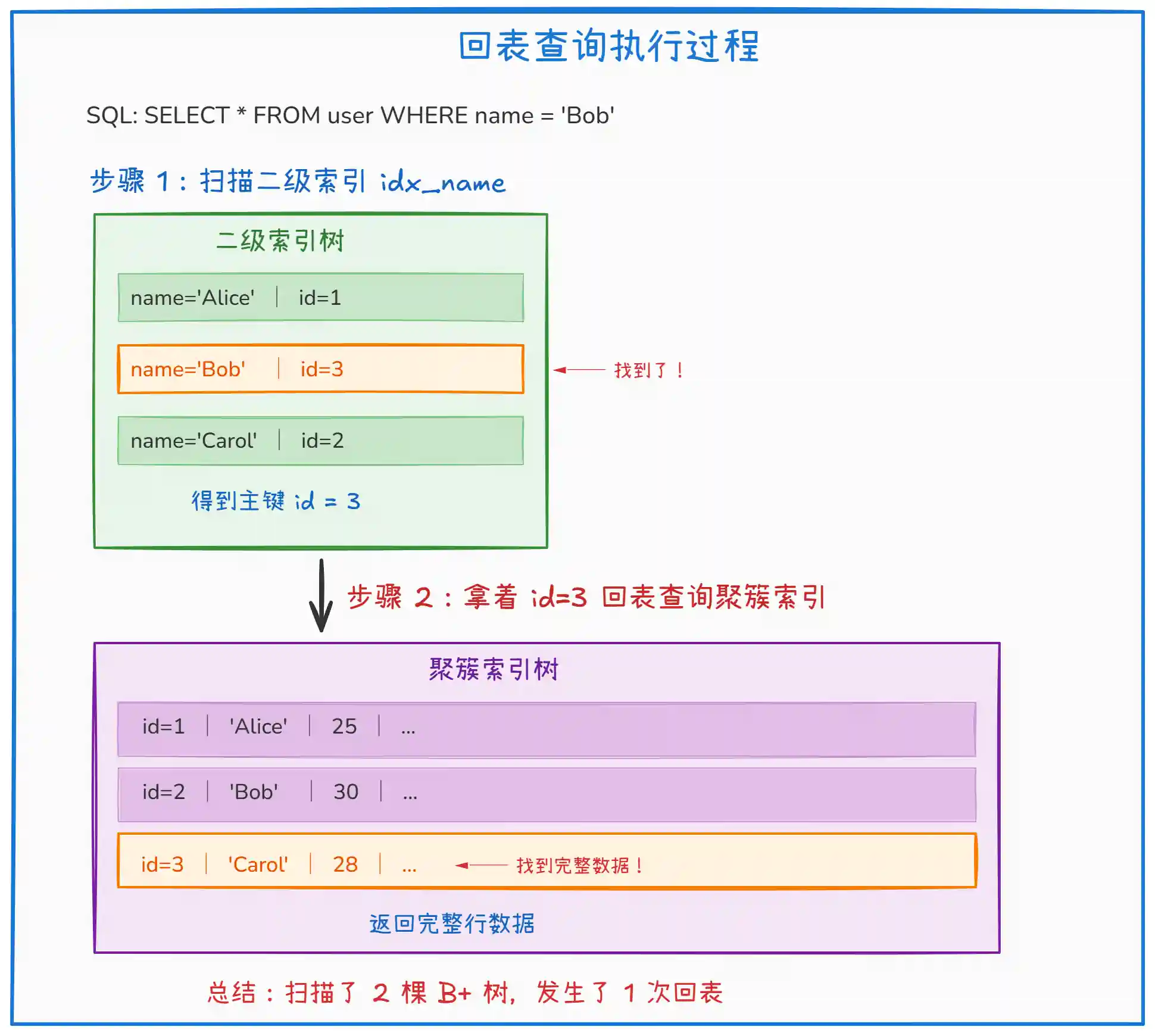
上图展示了回表的完整过程。核心步骤说明:
- 步骤一:在二级索引
idx_name中查找name = 'Bob',找到对应的主键id = 3 - 步骤二:拿着主键
id = 3,回到聚簇索引树中查找完整的行数据 - 回表代价:需要扫描两棵 B+ 树,产生额外的 I/O 开销
三、如何避免回表?—— 覆盖索引
覆盖索引(Covering Index):如果查询的所有字段都包含在索引中,MySQL 就不需要回表,直接从索引树获取数据即可。
优化前(会回表):
-- 查询 name 和 age,但 idx_name 索引只有 name,没有 age
-- 所以需要回表获取 age 字段
SELECT name, age FROM user WHERE name = 'Bob';
优化后(不回表):
-- 创建联合索引,包含 name 和 age
CREATE INDEX idx_name_age ON user(name, age);
-- 再次查询,name 和 age 都在索引中,不需要回表!
SELECT name, age FROM user WHERE name = 'Bob';
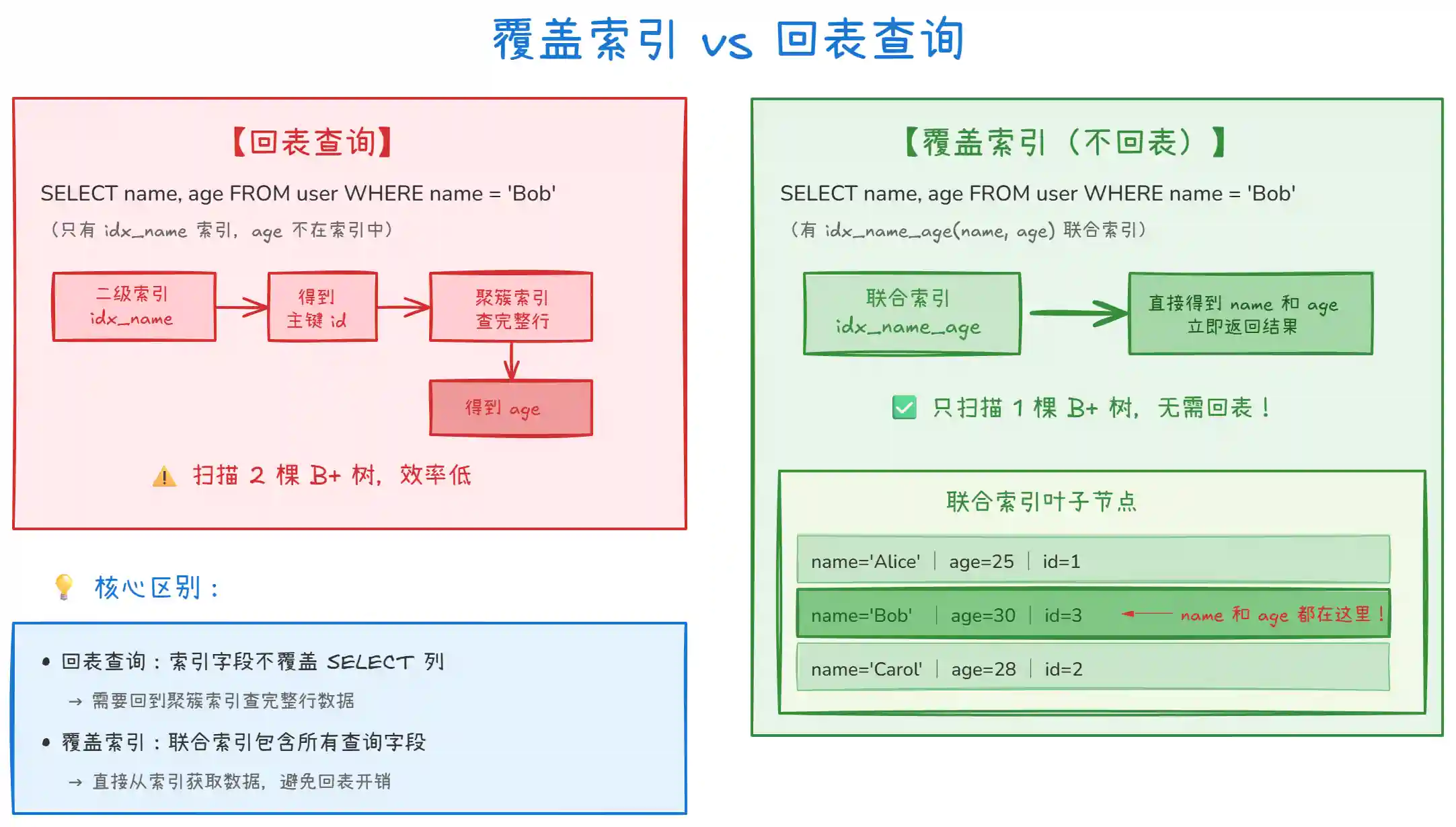
上图对比了回表查询和覆盖索引的执行差异。覆盖索引的核心优势:
- 减少 I/O:只扫描一棵 B+ 树,避免回表的额外 I/O
- 提升性能:特别是高并发场景,减少 I/O 意味着更高的 QPS
- 索引下推:MySQL 5.6 之后,覆盖索引还能配合 ICP 进一步优化
四、如何判断是否发生回表?
使用 EXPLAIN 命令查看执行计划,关注 Extra 字段:
-- 会回表的查询
EXPLAIN SELECT * FROM user WHERE name = 'Bob';
| 字段 | 值 | 含义 |
|---|---|---|
| type | ref | 使用了二级索引 |
| key | idx_name | 使用的索引名 |
| Extra | NULL | ❌ 没有使用覆盖索引,需要回表 |
-- 覆盖索引查询(不回表)
EXPLAIN SELECT name, age FROM user WHERE name = 'Bob';
| 字段 | 值 | 含义 |
|---|---|---|
| type | ref | 使用了二级索引 |
| key | idx_name_age | 使用的联合索引 |
| Extra | Using index | ✅ 使用了覆盖索引,不回表! |
关键指标:Extra 字段出现 Using index 表示使用了覆盖索引,不会回表。
五、覆盖索引的最佳实践
1. 高频查询字段建联合索引
-- 业务高频查询:SELECT name, age FROM user WHERE name = ?
CREATE INDEX idx_name_age ON user(name, age);
2. 遵循最左前缀原则
-- 联合索引 (name, age, phone)
CREATE INDEX idx_name_age_phone ON user(name, age, phone);
-- ✅ 走覆盖索引
SELECT name, age FROM user WHERE name = 'Bob'; -- 用到 name
SELECT name, age, phone FROM user WHERE name = 'Bob'; -- 用到 name, age, phone
SELECT name, age FROM user WHERE name = 'Bob' AND age = 30; -- 用到 name, age
-- ❌ 不走覆盖索引(违反最左前缀)
SELECT name, age FROM user WHERE age = 30; -- 没有 name 条件
3. 避免 SELECT
-- ❌ 可能导致回表
SELECT * FROM user WHERE name = 'Bob';
-- ✅ 只查需要的字段,利用覆盖索引
SELECT name, age FROM user WHERE name = 'Bob';
面试高频追问
-
追问一:主键查询和二级索引查询有什么区别?
- 答:主键查询直接走聚簇索引,叶子节点存完整数据,不需要回表;二级索引查询如果字段不覆盖,需要先查主键 ID 再回表查完整数据。
-
追问二:为什么不建议用
SELECT *?- 答:
SELECT *会查询所有字段,如果走二级索引,大概率字段不全覆盖,必须回表;而明确指定字段可以设计覆盖索引,避免回表提升性能。
- 答:
-
追问三:联合索引的设计原则是什么?
- 答:遵循 "最左前缀原则",将高频查询条件放左边,覆盖查询字段放右边;同时考虑区分度,区分度高的字段放前面。
常见面试变体
- "什么是覆盖索引?它有什么优势?"
- "为什么主键查询比二级索引查询快?"
- "如何优化 SQL 减少 I/O 次数?"
- "EXPLAIN 的 Extra 字段中 Using index 是什么意思?"
记忆口诀
回表与覆盖索引:
- 二级索引存 ID:叶子节点不存完整数据
- 回表查聚簇:拿着 ID 再查一次
- 覆盖免回表:查询字段全在索引中
总结
回表是 InnoDB 通过二级索引查询时,因索引不包含完整数据而需要二次查找聚簇索引的过程。避免回表的核心手段是 覆盖索引 —— 将查询涉及的字段都放入联合索引,使 MySQL 能直接从索引树获取所有数据。生产环境中应避免 SELECT *,根据高频查询设计合理的联合索引。