RabbitMQ 的整体架构是怎样的?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道你有没有用过 RabbitMQ,更是想确认你是否清楚它的核心组件(Producer、Broker、Exchange、Queue、Consumer、Binding)以及它们之间的关系。
-
原理理解深度:能否完整描述一条消息从生产到消费的全链路,是否理解 Exchange 的路由机制和 Binding 的匹配规则。
-
架构认知:是否了解 RabbitMQ 集群架构(普通集群 vs 镜像队列 vs 仲裁队列),以及 HAProxy + Keepalived 等高可用方案。
核心答案
RabbitMQ 的整体架构可以用一句话概括:生产者不直接把消息发给队列,而是发给 Exchange,由 Exchange 根据路由规则将消息投递到对应的队列,消费者再从队列中拉取消息。
核心组件一览:
| 组件 | 作用 | 类比 |
|---|---|---|
Producer |
发送消息的应用 | 寄件人 |
Consumer |
接收消息的应用 | 收件人 |
Broker |
RabbitMQ 服务节点 | 邮局 |
Exchange |
接收消息并路由到队列 | 分拣中心 |
Queue |
存储消息的缓冲区 | 邮箱 |
Binding |
Exchange 和 Queue 之间的绑定规则 | 分拣规则 |
Connection |
客户端与 Broker 的 TCP 连接 | 运输通道 |
Channel |
Connection 中的轻量级虚拟连接 | 运输车 |
深度解析
一、消息流转全链路
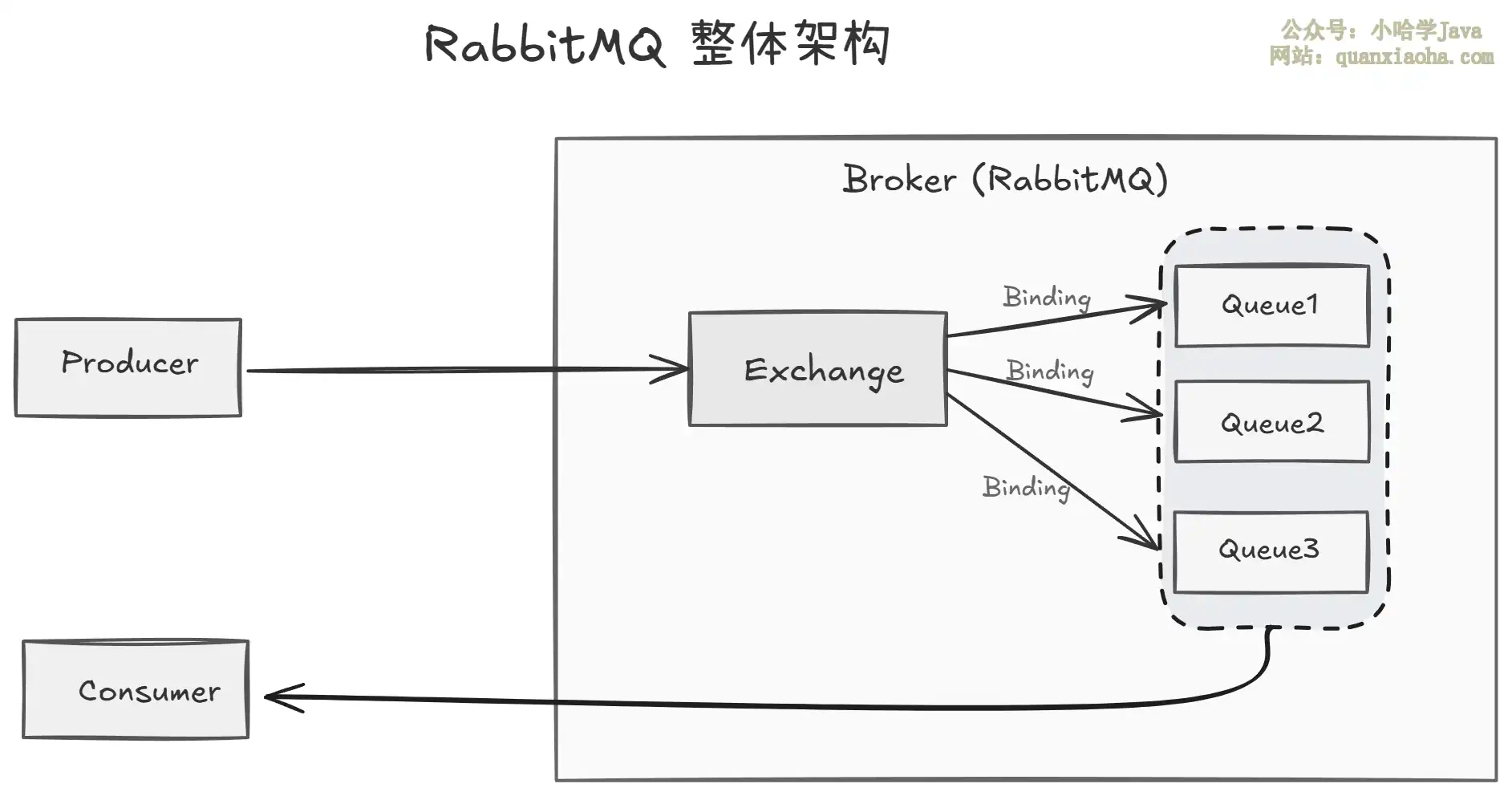
上图展示了 RabbitMQ 消息流转的完整链路。整体流程如下:
-
第一步 —— 生产者发送消息:
Producer将消息发送到Broker上的某个Exchange,而不是直接发给Queue。这是 RabbitMQ 和很多其他消息队列的一个重要区别。 -
第二步 —— Exchange 路由:
Exchange收到消息后,根据自身的类型(direct、topic、fanout、headers)和Binding规则,决定将消息投递到哪些Queue。如果没有任何Queue匹配,消息会被丢弃或返回给生产者(取决于配置)。 -
第三步 —— 队列存储:消息进入
Queue后,会持久化到磁盘(如果配置了持久化),等待消费。 -
第四步 —— 消费者消费:
Consumer通过Connection和Channel连接到Broker,从Queue中订阅或拉取消息进行处理。 -
第五步 —— ACK 确认:消费者处理完消息后,发送
ACK确认。如果消费者在处理过程中崩溃或未确认,消息会重新入队,确保不丢失。
关键点在于,Exchange 是整个路由的核心。理解了 Exchange 的四种类型,就理解了 RabbitMQ 的消息分发模型。
二、Exchange 四种类型对比
这是面试官最爱追问的点,务必搞清楚:
| 类型 | 路由规则 | 典型场景 | 举例 |
|---|---|---|---|
direct |
精确匹配 routing key |
点对点通信 | 日志系统按级别分发(error、info) |
fanout |
广播到所有绑定的 Queue,忽略 routing key |
广播通知 | 群发营销消息、事件通知 |
topic |
通配符匹配 routing key(* 匹配一个词,# 匹配零或多个词) |
发布/订阅模式 | 日志系统按 order.log.error 等主题分发 |
headers |
匹配消息头属性(性能差,极少用) | 特殊路由需求 | 几乎不用 |
说个我自己的经验:90% 的业务场景用 direct 和 topic 就够了。fanout 适合广播场景,headers 基本可以忽略。
三、Connection 与 Channel 的关系
这块很多人搞不清楚,面试官追问的时候容易翻车。
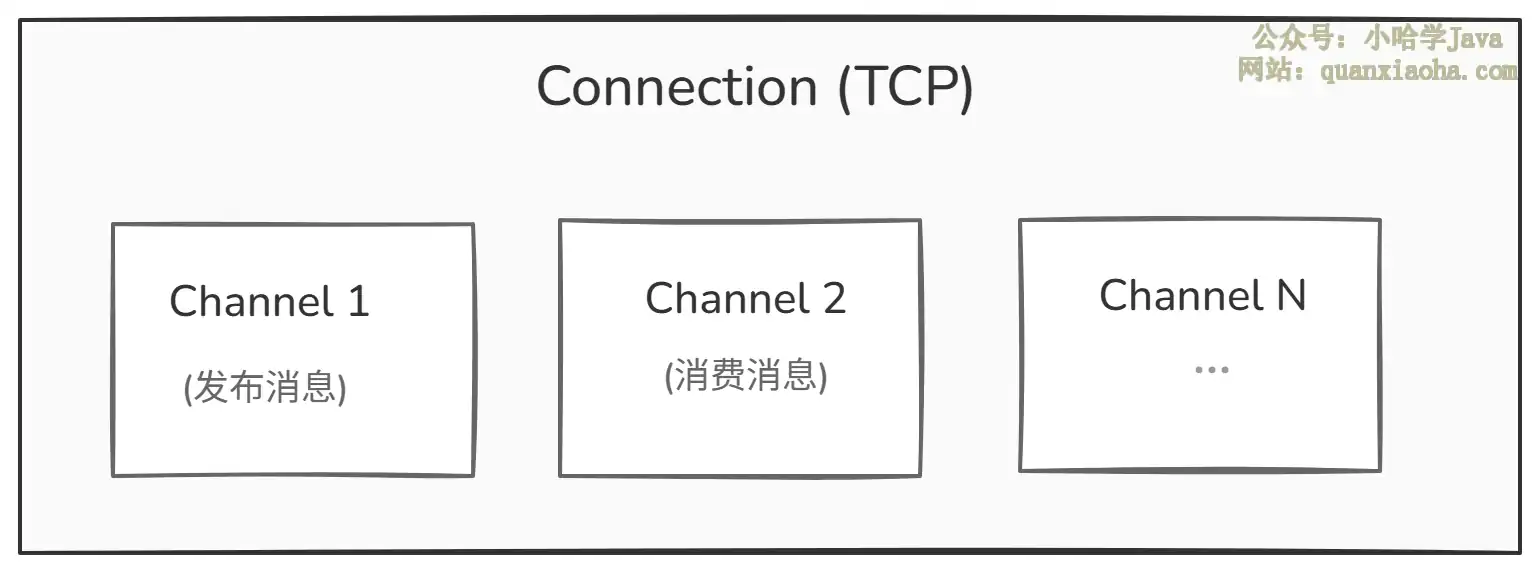
- Connection 是客户端与
Broker之间的一条真实的 TCP 连接,创建和销毁成本很高 - Channel 是
Connection内部的轻量级虚拟连接,复用同一条 TCP 连接,开销极小 - 最佳实践:每个线程使用独立的
Channel,但共享同一个Connection。千万别每个线程都新建一个Connection,性能会炸
四、集群架构
生产环境不会只用单节点,面试官大概率会追问集群方案。RabbitMQ 有三种集群模式:
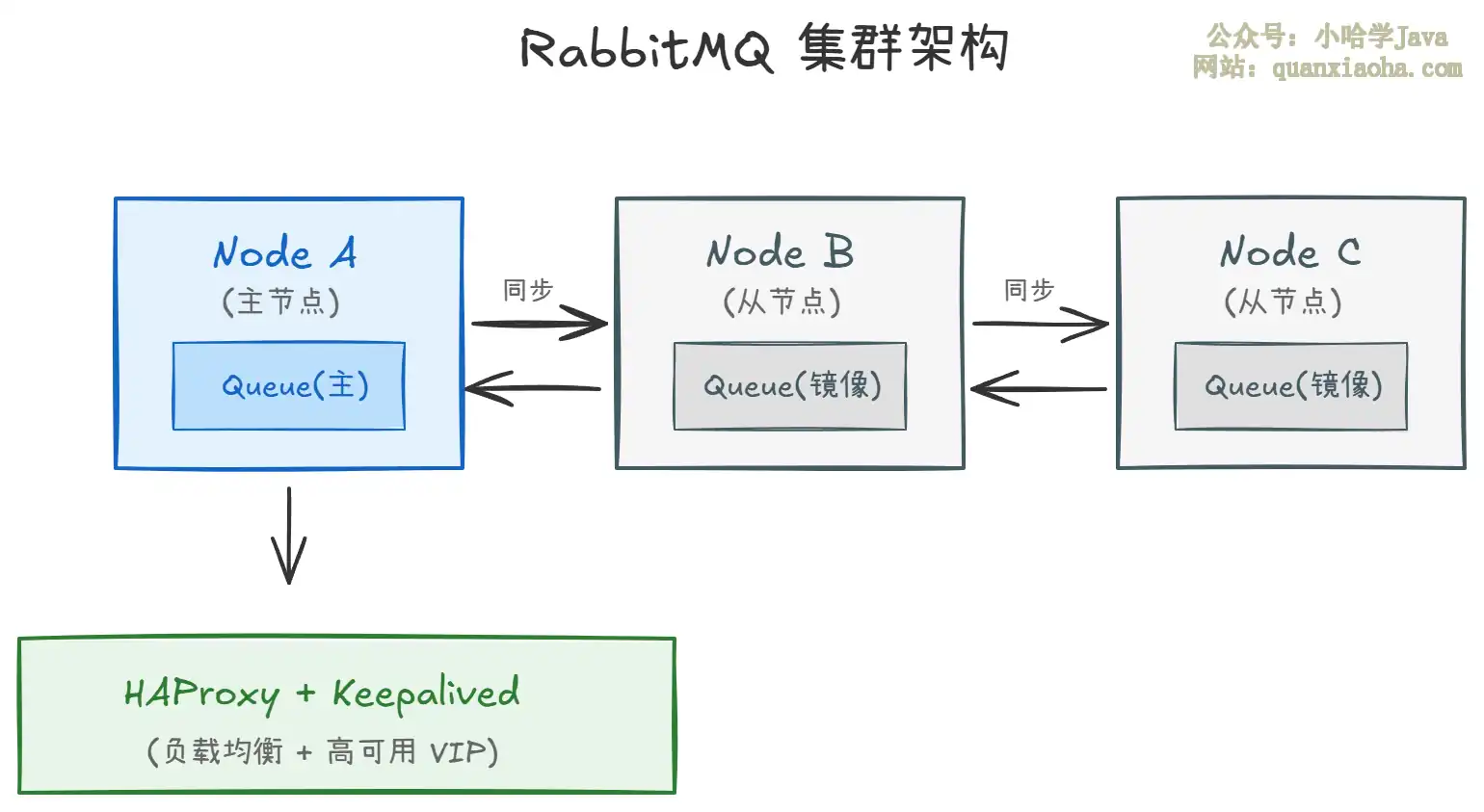
| 集群模式 | 特点 | 适用场景 |
|---|---|---|
| 普通集群 | 队列数据只存在主节点,其他节点只存元数据(指向主节点) | 读取性能要求不高、允许短暂不可用 |
| 镜像队列(经典) | 队列数据在多个节点间同步复制,主节点挂了自动切换 | 对数据可靠性要求高(RabbitMQ 3.13 已弃用) |
| 仲裁队列 | 基于 Raft 共识算法实现,替代镜像队列的推荐方案 | RabbitMQ 4.x 推荐方案,可靠性与可用性兼备 |
这里有个重要趋势:镜像队列在 RabbitMQ 3.13 已被弃用,RabbitMQ 4.x 彻底移除,官方推荐使用仲裁队列(Quorum Queue)。面试时如果提到这个版本差异,绝对是加分项。
面试高频追问
-
如何保证消息不丢失?
- 三个层面:生产者开启
confirm模式确认消息到达 Broker;队列和消息设置持久化(durable=true+deliveryMode=2);消费者手动ACK。
- 三个层面:生产者开启
-
如何保证消息的顺序性?
- 单
Queue单Consumer天然有序。多Consumer时,可以将需要保证顺序的消息通过相同routing key路由到同一个Queue。
- 单
-
RabbitMQ 支持延时消息吗?
- 原生不支持,但可以通过
TTL+ 死信队列(DLX)或安装rabbitmq_delayed_message_exchange插件实现。
- 原生不支持,但可以通过
常见面试变体
- "画一下 RabbitMQ 的架构图,并解释各个组件的作用"
- "RabbitMQ 中 Exchange 有哪几种类型?分别适用于什么场景?"
- "RabbitMQ 集群方案有哪些?你们生产环境用的是哪种?"
记忆口诀
核心组件:生产者发 Exchange,Exchange 按 Binding 路由到 Queue,Consumer 从 Queue 消费。
Exchange 四类型:direct 精确匹配、fanout 全都发、topic 通配符、headers 不常用。
总结
一句话:RabbitMQ 的核心是 Exchange 路由模型——生产者不直接发队列,而是通过 Exchange + Binding 规则分发,理解了 direct、fanout、topic 三种路由类型和集群三种模式(普通、镜像、仲裁),这道题就稳了。别忘了补一句"镜像队列已弃用,推荐仲裁队列",面试官会眼前一亮。