Redis 和 Memcached 的区别是什么?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观

面试考察点
-
技术选型能力:面试官不仅仅是想让你列举几个不同点,更是想知道你在实际项目中能否根据业务需求做出合理的缓存选型决策,而不是 "领导说用啥就用啥"。
-
底层原理深度:考察你是否理解两者的线程模型、内存管理机制、持久化策略等核心差异,这些直接影响到生产环境的性能和稳定性。
-
实践经验:能否结合真实场景说明什么时候选 Redis、什么时候选 Memcached,体现的是 "用过且踩过坑" 的实战积累。
核心答案
Redis 和 Memcached 都是高性能的内存缓存中间件,但在功能丰富度、数据结构、持久化、高可用等方面存在显著差异。目前新项目绝大多数场景首选 Redis。
| 对比维度 | Redis | Memcached |
|---|---|---|
| 数据类型 | 5 种基础 + 4 种扩展(String、List、Hash、Set、ZSet 等) | 仅 String |
| 持久化 | 支持 RDB + AOF,数据可落盘 | 纯内存,重启即丢 |
| 高可用 | 主从复制、哨兵、Cluster 集群 | 需要客户端一致性哈希 |
| 线程模型 | 核心 command 单线程(6.0 后网络 IO 多线程) | 多线程 |
| 内存管理 | 根据数据类型选择最优编码,支持淘汰策略 | Slab Allocator 机制 |
| 事务支持 | 事务 + Lua 脚本 | CAS 原子操作 |
| 发布订阅 | 支持 Pub/Sub | 不支持 |
| 单值大小 | 最大 512MB | 最大 1MB |
一句话结论:Memcached 是纯粹的缓存,而 Redis 是 "缓存 + 数据库" 的混合体。新项目基本都选 Redis。
深度解析
一、数据类型差异
这是最核心的区别。Memcached 只能存简单的 Key-Value(String),而 Redis 支持丰富的数据结构。
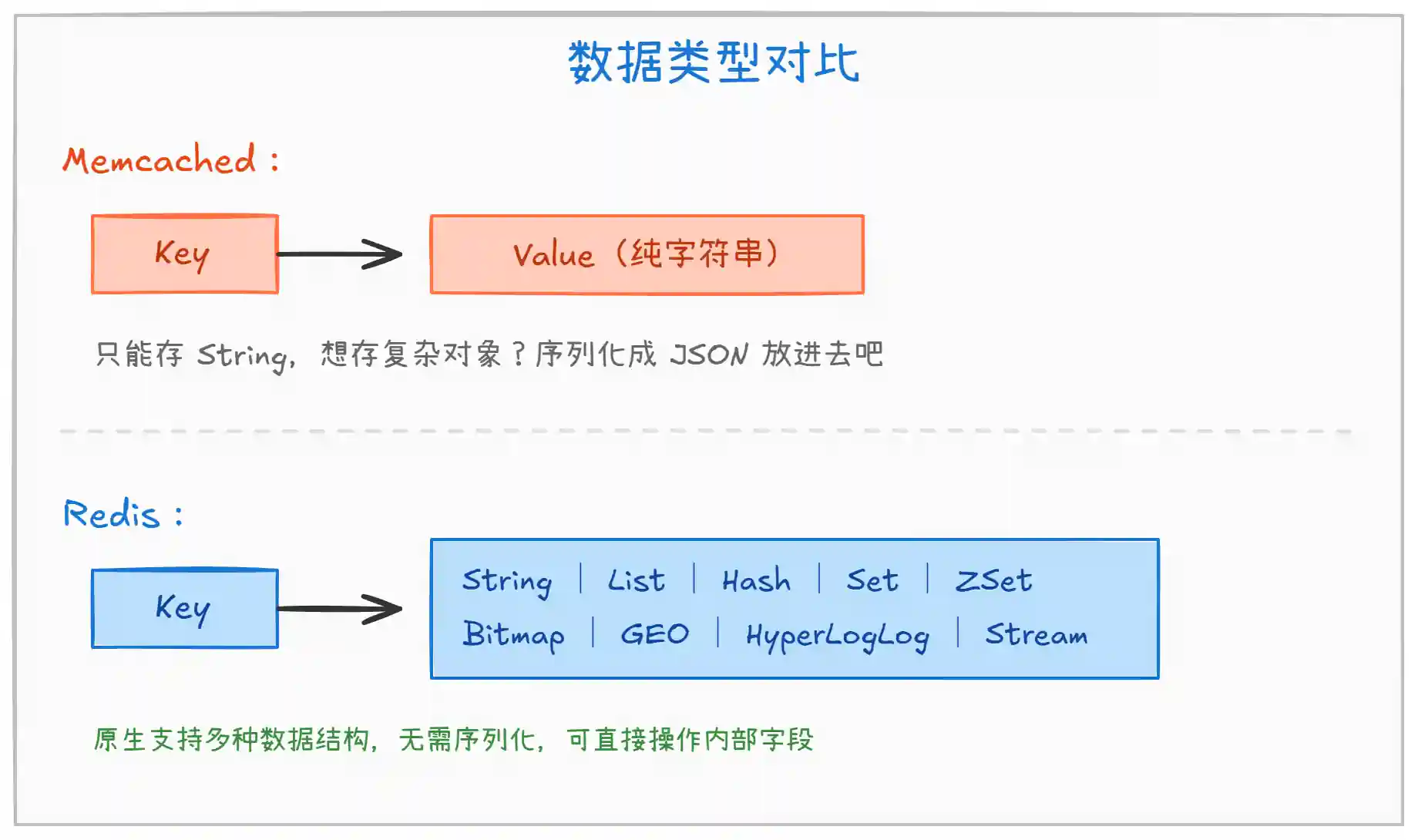
上图展示了两者的数据类型差异。关键点如下:
-
Memcached:只能存储 Key-Value 形式的字符串。如果要存一个用户对象,需要把整个对象 JSON 序列化后存进去,修改某个字段也得把整个对象读出来改完再写回去,既浪费带宽又浪费时间。
-
Redis:原生支持
Hash、List、Set、ZSet等结构。比如用Hash存用户信息,修改年龄只需HSET user:1001 age 26,无需读写整个对象。ZSet更是可以直接做排行榜、延迟队列等复杂业务,Memcached 想都别想。
二、持久化能力
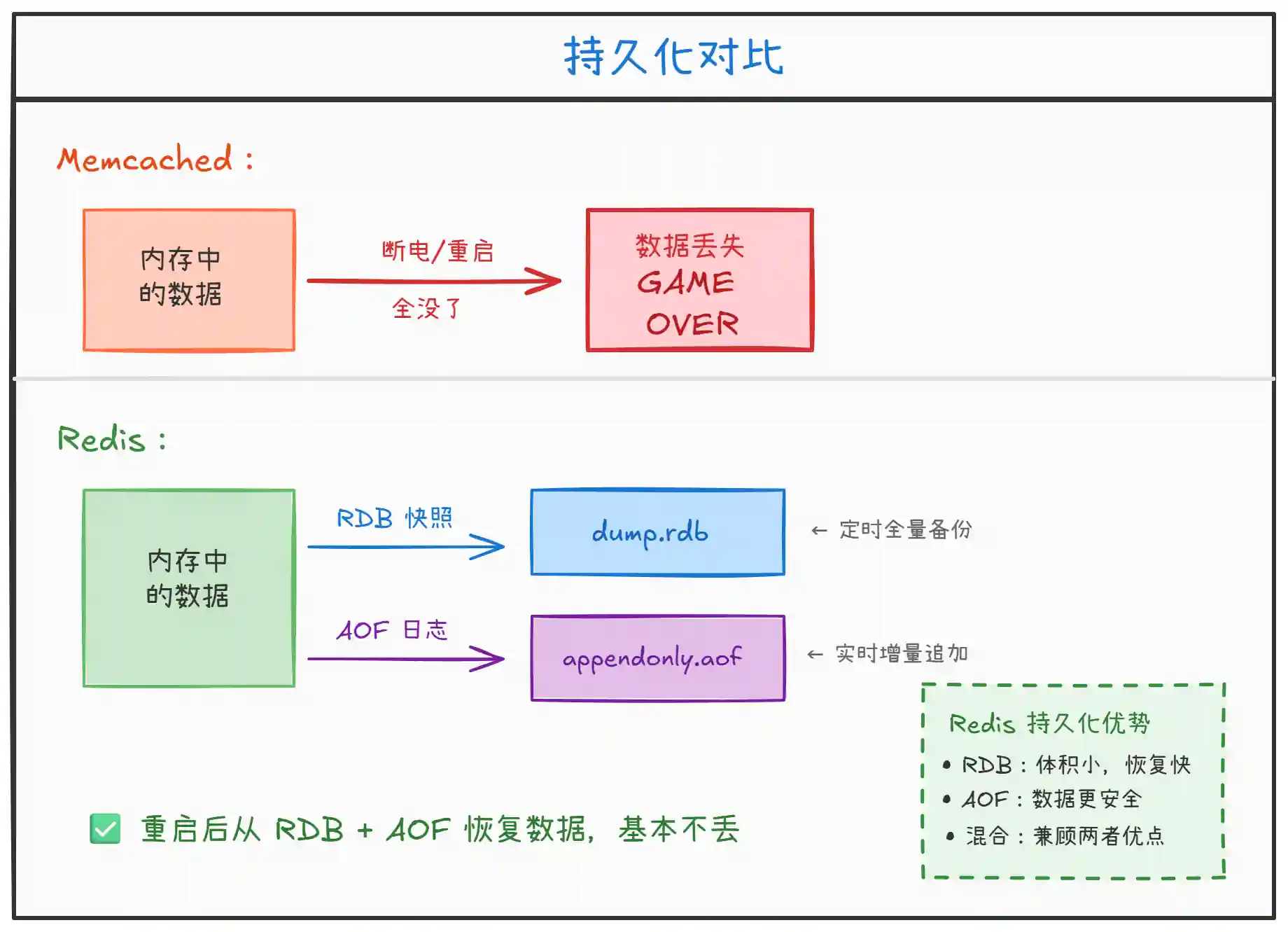
上图展示了两者的持久化差异:
-
Memcached:纯内存存储,没有任何持久化机制。进程一旦重启、服务器宕机或断电,所有数据全部丢失。它就是一个纯粹的缓存,你必须在数据库里保留完整数据。
-
Redis:提供两种持久化方案。
RDB(快照)定期将内存数据全量写入磁盘,恢复速度快但可能丢失最后一次快照之后的数据。AOF(追加日志)记录每一次写操作,数据安全性更高。两者可以组合使用,Redis 4.0 后还支持RDB + AOF混合持久化,兼顾恢复速度和数据安全。
三、线程模型对比
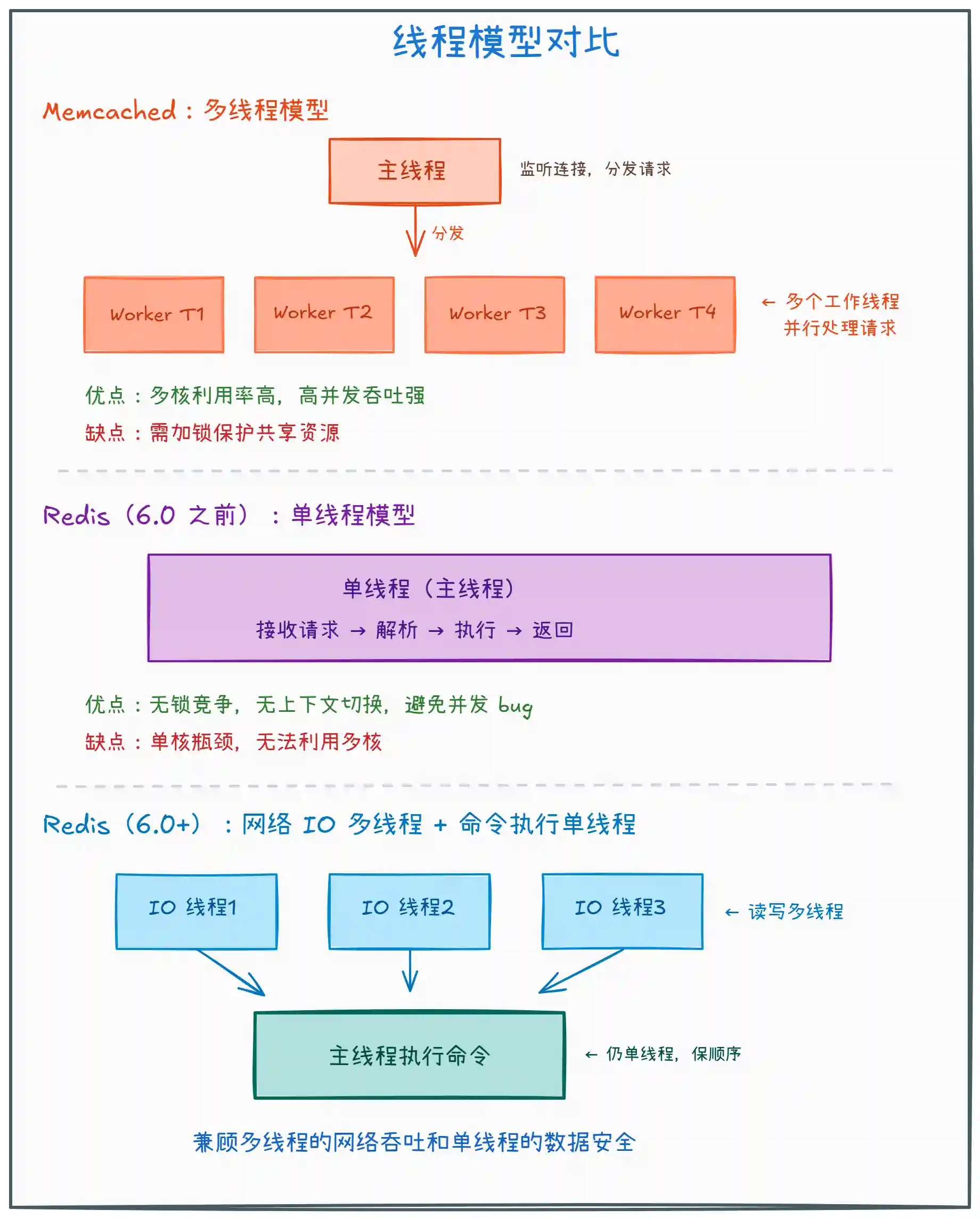
上图展示了三者的线程模型差异:
-
Memcached:采用多线程模型,主线程负责接收连接,然后把请求分发给多个 Worker 线程并行处理。好处是能充分利用多核 CPU,在高并发场景下吞吐量很高。缺点是多个线程操作共享资源时需要加锁,带来了锁竞争的开销和并发 bug 的风险。
-
Redis(6.0 之前):核心命令执行采用单线程模型。看起来是个缺点,但 Redis 作者认为 Redis 的性能瓶颈不在 CPU,而在内存和网络 IO。单线程的好处是避免了锁竞争、上下文切换、并发 bug 等问题,代码也更简单可靠。而且 Redis 是基于内存的操作,单次命令执行极快(微秒级),单线程完全扛得住。
-
Redis(6.0+):引入了网络 IO 多线程,但命令执行仍然是单线程。也就是说,读取客户端请求和写回响应这两个耗时的网络操作由多个 IO 线程并行处理,而真正操作数据的命令执行还是由主线程串行完成。这样既提升了网络吞吐,又保证了数据操作的无锁安全。
四、高可用与集群
-
Redis:原生支持主从复制、哨兵(Sentinel)自动故障转移、Cluster 分片集群,数据分片、故障恢复都可以自动完成,不需要客户端操心。
-
Memcached:没有内建的高可用方案。想要集群?客户端自己做一致性哈希。某台节点挂了?缓存直接失效,请求穿透到数据库,需要客户端自己处理。
五、内存管理
-
Memcached:采用 Slab Allocator 机制,将内存划分为不同大小的 chunk(如 80B、100B、128B...)。写入数据时选择最接近的 slab class,容易产生内存碎片(比如 100 字节的数据放到 128 字节的 chunk,浪费 28 字节)。
-
Redis:根据数据类型和大小自动选择最优的底层编码(如
ziplist、hashtable、skiplist),内存利用率更高。同时支持多种淘汰策略(LRU、LFU、TTL等),在内存满时自动淘汰不常用的数据。
六、如何选型
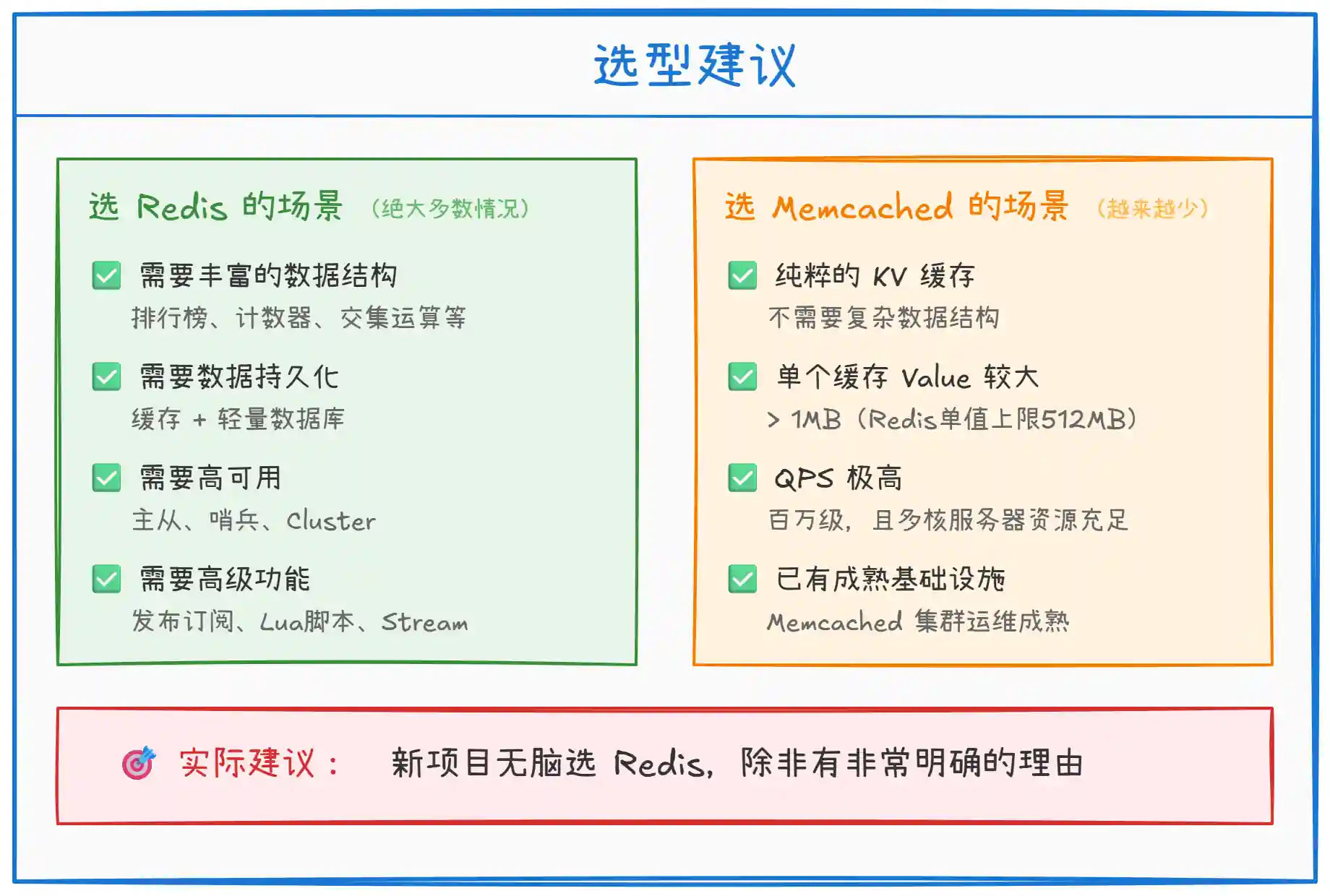
上图给出了两者的选型建议。简单来说:
-
新项目默认选 Redis:功能全面、生态活跃、社区支持好,几乎覆盖了所有缓存场景,还能兼职做消息队列、排行榜、分布式锁等。
-
Memcached 适用场景越来越窄:只有在纯 KV 缓存、超大规模(单机 QPS 百万级)、Value 较大等特殊场景下才有优势。而且现在 Redis 6.0+ 的 IO 多线程也在逐步缩小两者的吞吐差距。
面试高频追问
-
追问一:Redis 单线程为什么还这么快?
- 基于内存操作(纳秒级)、IO 多路复用(单线程处理大量连接)、避免锁竞争和上下文切换、高效的数据结构编码。
-
追问二:Redis 6.0 为什么要引入多线程?会有线程安全问题吗?
- 网络读写成为瓶颈时用多线程提升 IO 吞吐,但命令执行仍然是单线程,不存在线程安全问题。
-
追问三:Memcached 的一致性哈希是什么?Redis Cluster 用的是什么?
- Memcached 客户端通过一致性哈希环做分片,节点增减只影响相邻节点;Redis Cluster 用的是哈希槽(Hash Slot),16384 个槽分配到不同节点,更灵活。
常见面试变体
- "为什么现在大家都用 Redis 而不是 Memcached?"
- "Redis 单线程模型会不会成为性能瓶颈?怎么解决?"
- "你们的缓存方案为什么选 Redis 而不是 Memcached?"
- "Redis 6.0 的多线程和 Memcached 的多线程有什么区别?"
记忆口诀
核心差异:Redis 是 "多功能瑞士军刀"(丰富数据结构 + 持久化 + 高可用),Memcached 是 "纯缓存利器"(简单 KV + 多线程高吞吐)。
选型原则:新项目选 Redis,老项目看场景,纯 KV 高并发才考虑 Memcached。
总结
Redis 和 Memcached 的核心区别在于:Redis 支持丰富的数据类型、数据可持久化、原生高可用集群,是 "缓存 + 数据库" 的混合体;Memcached 仅支持简单 KV 缓存,但多线程模型在纯缓存高吞吐场景下有优势。新项目基本首选 Redis,Memcached 的适用场景越来越少。