JVM 垃圾回收算法有哪些?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
- 算法基础掌握:面试官想知道你是否清楚四种基础 GC 算法的原理和特点,而不是笼统地说一句 "标记清除"。
- 优缺点对比能力:每个算法都有明显的短板,面试官考察你能否说出 "空间碎片"、"复制开销"、"Stop-The-World" 这些关键词,以及它们各自的适用场景。
- 分代收集思想:现代 JVM 不是只用一种算法,而是根据分代特点组合使用。能不能把这层关系讲清楚,是区分 "背八股文" 和 "真理解" 的分水岭。
核心答案
JVM 的垃圾回收算法有 4 种基础算法:
| 算法 | 核心思路 | 优点 | 缺点 |
|---|---|---|---|
| 标记-清除(Mark-Sweep) | 先标记可回收对象,再统一清除 | 实现简单 | 空间碎片多、分配效率低 |
| 标记-复制(Copying) | 将存活对象复制到另一块空间,原空间整体清空 | 没有碎片、分配快(指针碰撞) | 内存利用率只有一半 |
| 标记-整理(Mark-Compact) | 将存活对象向一端移动,清理边界外空间 | 没有碎片、内存利用率高 | 移动对象开销大 |
| 分代收集(Generational) | 根据对象存活特点分代,每代选用最合适的算法 | 兼顾效率和利用率 | 实现复杂 |
现代 JVM(HotSpot)采用的是 分代收集策略,在不同代中组合使用上述基础算法。
深度解析
一、标记-清除算法(Mark-Sweep)
最基础的 GC 算法,分为两步:先标记出所有需要回收的对象,再统一清除。

标记-清除的过程很直观:遍历所有对象,把不可达的标出来(标记阶段),然后把这些对象的内存直接回收(清除阶段)。
- 优点:实现简单,不需要移动对象,不需要额外空间。
- 缺点一:空间碎片。清除后内存中布满了大大小小的空闲块。假设现在要分配一个 3 个单位的对象,虽然总空闲空间够,但没有任何一个连续的空闲块满足要求,分配就会失败。
- 缺点二:分配效率低。碎片化之后,分配器不得不用 "空闲列表"(Free List)来管理可用内存,每次分配都要遍历列表找合适大小的块,比起 "指针碰撞"(Bump the Pointer)那种 O(1) 的分配方式,效率差了不少。
二、标记-复制算法(Copying)
为了解决碎片问题,标记-复制算法把内存一分为二,每次只用其中一半。
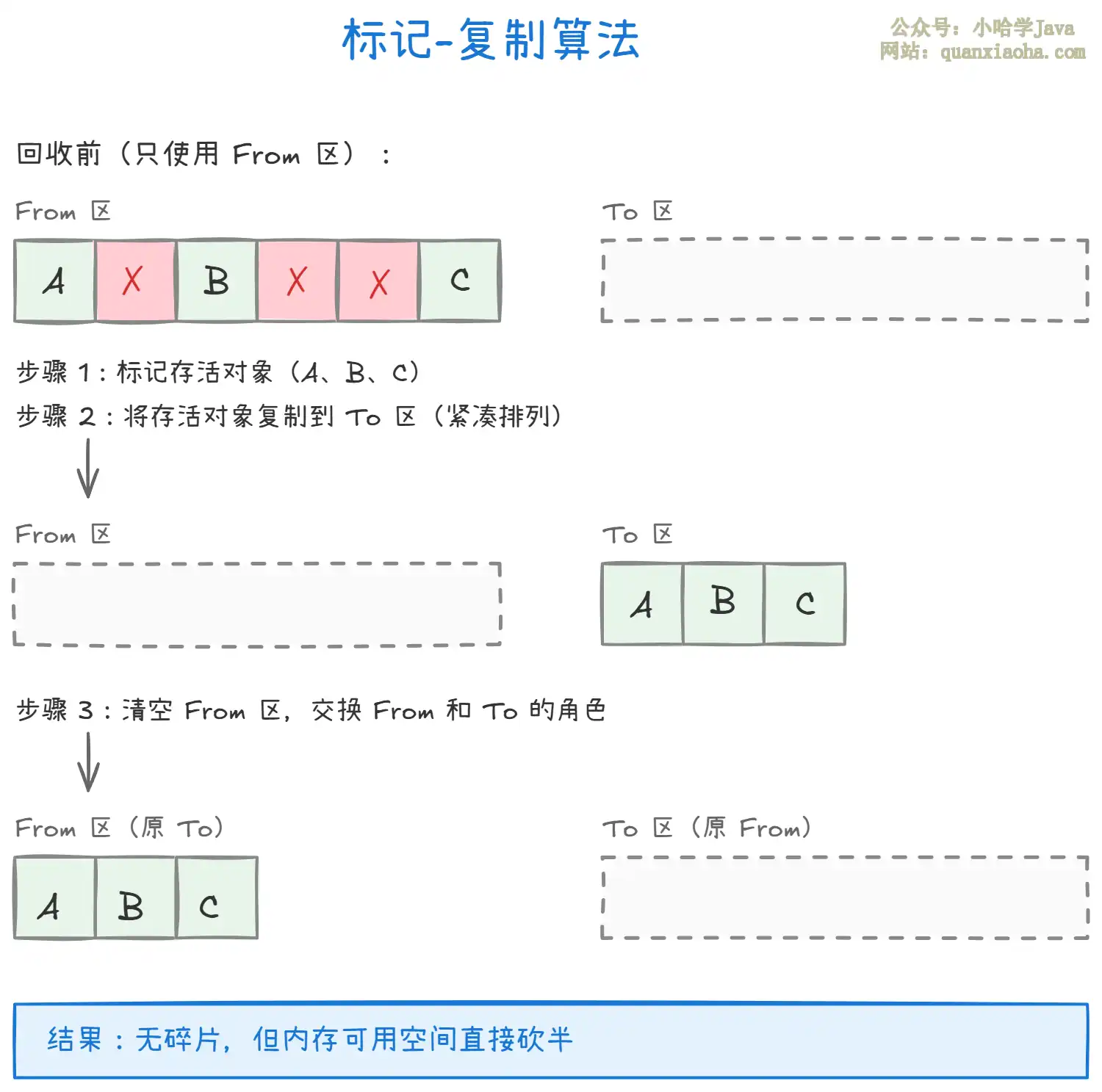
标记-复制的思路很巧妙:每次 GC 只扫描当前正在使用的半区(From 区),把存活对象 按顺序 复制到另一半(To 区),然后 From 区整个清空。复制完成后两个角色互换。
- 优点:复制过去之后对象是紧凑排列的,没有碎片。分配新对象时只需要移动一个指针就行了(指针碰撞),O(1) 搞定,效率极高。
- 缺点:太费内存了。可用空间直接打了个五折,对于堆内存寸土寸金的 JVM 来说,这个代价很大。另外如果存活对象很多,复制操作本身的开销也不小。
HotSpot 的新生代做了一个很聪明的优化——Appel 式回收。它不是严格 1:1 平分,而是把新生代分为一个较大的 Eden 区和两个较小的 Survivor 区(From 和 To),默认比例 8:1:1。每次 GC 只用 Eden + 一个 Survivor,浪费的空间只有 10% 而不是 50%。这块在后面的分代收集中会详细说。
三、标记-整理算法(Mark-Compact)
标记-复制太费空间了,那有没有既不碎片、又不浪费一半内存的方案?标记-整理就是答案。
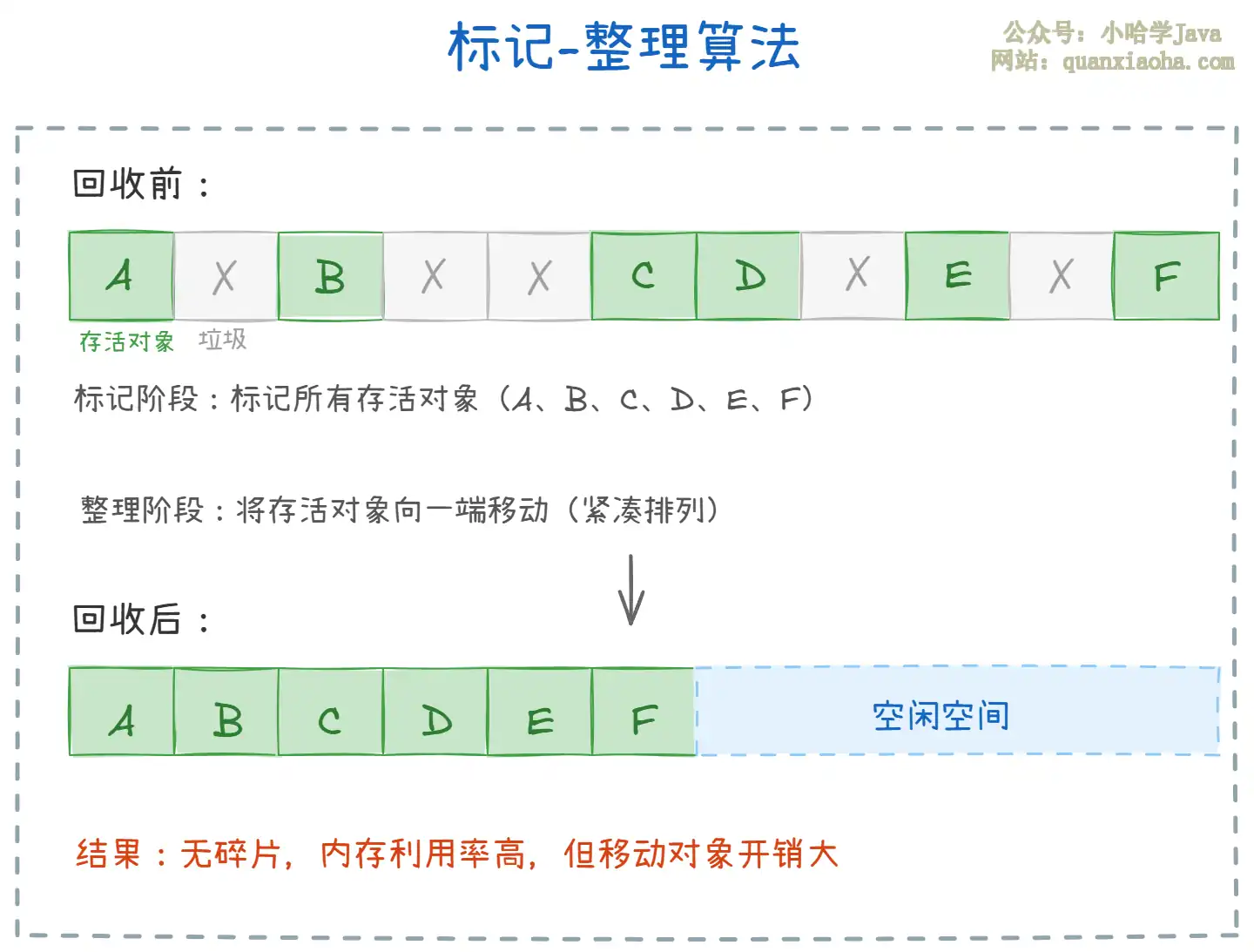
标记-整理分三步:先标记存活对象(和标记-清除一样),然后把所有存活对象往内存的一端 "挪动",最后把边界以外的空间全部释放。
- 优点:既没有碎片,又不浪费额外空间。对老年代这种对象存活率高、GC 不频繁的区域特别合适。
- 缺点:要移动对象就意味着要更新所有指向这些对象的引用,这个开销不小。尤其是老年代对象多的时候,整理过程会比较慢。
所以这也是一个权衡:新生代存活少,用复制算法划算;老年代存活多,移动所有对象的成本太高,但碎片更不能接受,所以用标记-整理。
四、分代收集算法(Generational Collection)
重点来了。前面三种算法各有优劣,现代 JVM 的做法是——不选一个,全都要。
分代收集的核心思想基于一个经验规律:绝大多数对象都是 "朝生夕死" 的。统计表明,约 98% 的对象在一次 Minor GC 中就会被回收。根据对象存活特点的不同,把堆内存分为不同的 "代",每代选用最适合的算法。

分代收集的整体布局如上图所示,Java 堆被划分为新生代和老年代两大区域:
- 新生代(Young Generation):分为
Eden区和两个Survivor区(S0和S1),默认比例 8:1:1。新对象优先在 Eden 区分配。每次 Minor GC 时,将 Eden 和当前使用的 Survivor 区中的存活对象复制到另一个 Survivor 区,然后清空前两个区域。使用标记-复制算法,因为新生代对象存活率极低,只需要复制少量存活对象,效率很高。而且由于有 Survivor 区做缓冲,实际浪费的空间只有 10%(一个 Survivor 区),而不是 50%。 - 老年代(Old Generation):存放长期存活的对象和大对象。由于老年代对象存活率高,如果用复制算法,需要复制大量对象,效率太低。所以老年代使用 标记-清除 或 标记-整理 算法。具体用哪种取决于选择的垃圾收集器:
CMS使用标记-清除(追求低延迟),Serial Old、Parallel Old使用标记-整理(追求吞吐量)。
五、对象如何晋升到老年代?
聊到分代收集,就绕不开对象从新生代晋升到老年代的规则,这同样是高频考点:
| 晋升条件 | 说明 |
|---|---|
| 年龄达到阈值 | 对象在 Survivor 区每熬过一次 Minor GC,年龄 +1,默认达到 15 岁(-XX:MaxTenuringThreshold)晋升到老年代 |
| 大对象直接进入老年代 | 超过 -XX:PretenureSizeThreshold 设定值的对象,直接在老年代分配,避免在新生代来回复制 |
| 动态年龄判断 | Survivor 区中相同年龄的所有对象大小总和超过 Survivor 空间的一半,则年龄 >= 该年龄的对象直接晋升 |
| 空间分配担保 | Minor GC 后 Survivor 区放不下所有存活对象,通过担保机制直接进入老年代 |
六、三种基础算法全面对比
一张表总结清楚:
| 维度 | 标记-清除 | 标记-复制 | 标记-整理 |
|---|---|---|---|
| 空间碎片 | ❌ 有碎片 | ✅ 无碎片 | ✅ 无碎片 |
| 内存利用率 | ✅ 高 | ❌ 最高浪费 50% | ✅ 高 |
| 移动对象 | ❌ 不移动 | ✅ 复制存活对象 | ✅ 移动存活对象 |
| 引用更新 | ❌ 不需要 | ✅ 需要更新引用 | ✅ 需要更新引用 |
| 分配方式 | 空闲列表 | 指针碰撞 | 指针碰撞 |
| 适用场景 | 存活对象多 | 存活对象少 | 存活对象多 |
| 典型应用 | CMS 的老年代 | 新生代(Eden + Survivor) | Serial Old、Parallel Old |
一句话总结这个取舍关系:空间碎片和内存利用率不可兼得,要么牺牲空间换无碎片(复制),要么牺牲时间换无碎片(整理),要么省时间但忍受碎片(清除)。
面试高频追问
-
为什么新生代用复制算法,老年代用标记-整理?
- 核心原因就一个字:活的对象少不多。新生代 98% 的对象熬不过一次 GC,用复制算法只需要复制那 2% 的存活对象,非常高效。老年代对象存活率高,复制意味着要拷贝大部分对象,还不如直接整理。
-
为什么 Survivor 区要设计两个?
- 为了避免复制算法的 "全量复制" 问题。两个 Survivor 交替使用,一个做来源,一个做目标,保证每次 GC 后存活对象都有地方放。只有一个的话,复制算法就没法做了。
-
CMS 为什么用标记-清除而不是标记-整理?
- 因为 CMS 的设计目标是 低延迟。标记-整理需要移动对象并更新引用,这个过程中用户线程必须暂停(STW),而 CMS 为了减少停顿,选择了不移动对象的标记-清除。代价就是会有碎片,碎片太多时会退化为
Serial Old做一次全量整理。
- 因为 CMS 的设计目标是 低延迟。标记-整理需要移动对象并更新引用,这个过程中用户线程必须暂停(STW),而 CMS 为了减少停顿,选择了不移动对象的标记-清除。代价就是会有碎片,碎片太多时会退化为
-
JDK 11 引入的 ZGC 和 Shenandoah 用的什么算法?
- 它们用的是 染色指针 + 读屏障 实现的并发整理算法,可以在移动对象的同时让用户线程继续运行,理论上做到了整理操作不产生 STW 停顿。这是 GC 技术的前沿方向。
常见面试变体
- "说一说 JVM 的垃圾回收算法,各自的优缺点是什么?"
- "为什么新生代用复制算法?老年代为什么不用?"
- "JVM 的分代收集是怎么做的?为什么要分代?"
- "标记-清除和标记-整理有什么区别?"
记忆口诀
四种算法:标记清除有碎片,标记复制费空间,标记整理两全美但移动慢,分代收集组合拳。 分代对应:新生代配复制(活得少、复制快),老年代配清除或整理(活得多、移动慢)。 Eden Survivor 比例:8:1:1(八成新建,一成来,一回去)。
总结
JVM 有四种基础 GC 算法:标记-清除、标记-复制、标记-整理、分代收集。现代 HotSpot 采用分代策略——新生代用复制算法(存活少、效率高),老年代用标记-清除或标记-整理(存活多、不能浪费空间)。面试时把三种基础算法的优缺点和分代收集的组合思路讲清楚,基本就稳了。