Java 是编译型还是解释型语言?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
概念准确度:面试官不是让你做单选题。他想听你说清楚 Java 的执行机制,以及它跟 C++、Python 这些语言到底有什么不同。
-
JVM 底层认知:字节码、JIT、AOT,这些概念你能不能串成一条线?很多人知道名词但连不起来。
-
横向对比能力:能不能跳出 Java 本身,从语言设计的角度去分析编译和解释的取舍。
核心答案
Java 两种都占了。
.java 源码先经过 javac 编译成 .class 字节码,这一步是编译。然后字节码交给 JVM,JVM 逐条解释执行,这一步是解释。所以它是 "先编译、后解释" 的混合模式。
| 执行方式 | 代表语言 | 怎么跑的 |
|---|---|---|
| 纯编译型 | C、C++ | 源码直接编译成机器码,跑得快但绑平台 |
| 纯解释型 | Python、Ruby | 源码逐行翻译执行,跨平台但慢 |
| 混合型 | Java、Kotlin | 编译成字节码,再由 JVM 解释或 JIT 编译执行 |
说个趣事,我之前面试一个候选人,他说完 "混合型" 之后补了一句:"Python 其实也有字节码编译,严格来说也不算纯解释型。" 就这一句话,直接加分。面试官喜欢能举一反三的人。
深度解析
一、从 .java 到机器码,中间发生了什么
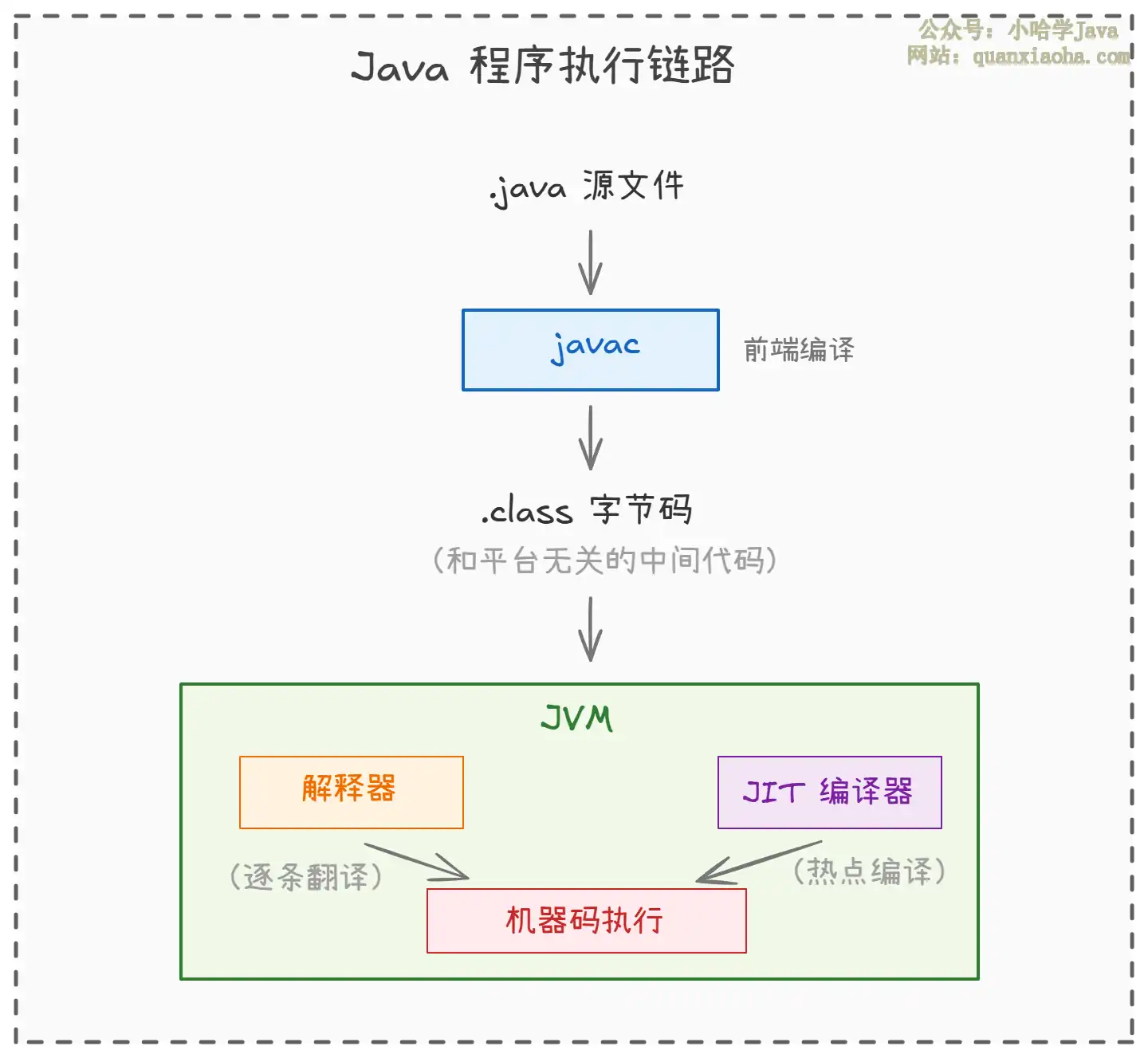
整个过程拆开来看:
编译阶段,javac 把 .java 变成 .class。注意,这里产出的不是 x86 或 ARM 的机器指令,而是一套中间格式,跟具体 CPU 没关系。这就是 Java 跨平台的根基:字节码只有一套,不同平台装不同的 JVM 就行。当年 Sun 公司喊出 "Write Once, Run Anywhere",底气就在这儿。
运行阶段,JVM 拿到字节码后怎么执行?两条路:
- 解释器逐条翻译,边翻边跑。好处是启动快,坏处是每次都要翻译,同样的代码跑十次就翻译十次。
- JIT 编译器不一样。它发现某段代码跑得特别频繁(热点代码),就一次性编译成机器码缓存起来,后面直接跑机器码,不再翻译了。
二、JIT 编译,Java 性能翻盘的关键
总有人说 "Java 慢",这观念大概还停在 JDK 1.0 年代。那时候确实只有解释器,跑起来跟 Python 差不多。但从 HotSpot JVM 开始(JDK 1.2),JIT 编译器把这事给扳回来了。
HotSpot 里有两个 JIT 编译器,分工不同:
| 编译器 | 启动速度 | 峰值性能 | 谁在用 |
|---|---|---|---|
| C1(Client) | 快 | 中等 | 桌面应用 |
| C2(Server) | 慢 | 很高 | 服务端 |
JDK 7 开始搞了个分层编译:先用 C1 快速编译,保证启动速度;跑一会儿之后,把热点代码交给 C2 做深度优化。两层配合下来,长时间跑的服务端应用,性能跟 C/C++ 差距很小。JDK 8 之后分层编译默认开启,不用手动配。
说个题外话,HotSpot 这个名字本身就有来头。"Hot Spot" 指的是 "热点",也就是那些被频繁执行的代码。JVM 的核心设计理念就是找到热点然后重点优化,所以叫 HotSpot。
三、AOT 编译,更新的玩法
JIT 是运行时编译,AOT 则是运行前就编译好。
JDK 9 引入了 jaotc 工具,能把字节码提前编译成机器码。但真正有意思的是 GraalVM,它可以直接把 Java 应用编译成原生二进制文件,连 JVM 都不装也能跑。Spring Boot 3 已经支持 GraalVM AOT,启动时间从秒级降到毫秒级。Cloud Native 场景下这个优势太大了。
// AOT 编译示例(JDK 9+)
// 先编译成字节码
javac HelloWorld.java
// 再用 jaotc 编译成共享库
jaotc --output libHelloWorld.so HelloWorld.class
// 运行时直接使用 AOT 编译的代码
java -XX:AOTLibrary=./libHelloWorld.so HelloWorld
不过 AOT 也有代价:因为缺少运行时信息,有些 JIT 能做的激进优化(比如根据实际类型内联虚方法)AOT 做不了。所以目前主流还是 JIT 为主、AOT 为辅,各有各的场景。
面试高频追问
JIT 和 AOT 到底选谁?
看场景。长时间运行的服务端应用用 JIT,跑得越久优化越好。短生命周期的场景(CLI 工具、Serverless 函数)用 AOT,启动快是王道。
为什么不直接编译成机器码?非要搞字节码这一层?
跨平台。直接编译成机器码,Windows 编译出来的就只能在 Windows 跑。字节码这层抽象,让同一份代码在任何装了 JVM 的系统上都能运行。这是设计上的取舍,不是技术做不到。
JVM 怎么判断哪段代码是 "热点"?
两个计数器:方法调用计数器统计方法被调了多少次,回边计数器统计循环体执行了多少次。超过阈值就触发 JIT 编译。阈值默认是 10000 次(Client)或 100000 次(Server),可以通过 -XX:CompileThreshold 调整。
常见面试变体
- "Java 的执行效率为什么能接近 C++?"
- "解释一下 JIT 编译机制"
- "JVM 是怎么执行字节码的?"
总结
Java 先编译后解释,两种都占了。面试时把 .java → .class → JVM 解释/JIT 编译这条线讲清楚,再顺带提一句分层编译和 AOT,基本就够了。别上来就说 "解释型" 就完事,显得理解太浅。