RocketMQ 消息堆积了怎么处理?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
问题诊断能力:面试官不仅仅是想知道你怎么 "救火",更是想知道你是否能快速定位消息堆积的根因——是消费端太慢、还是生产端太猛、还是 Broker 出了问题。
-
应急处理经验:考察你是否具备生产环境实战经验,能否在消息堆积时采取正确的应急策略,而不是手忙脚乱、越搞越乱。
-
架构优化思维:面试官想看你是否具备从源头预防堆积的能力,比如合理设计消费者并发度、选择合适的消息模型、做好监控告警等。
核心答案
消息堆积的处理思路可以用一句话概括:先止血、再恢复、最后根治。
具体来说,分为 应急处理 和 根本治理 两个层面:
| 层面 | 策略 | 核心动作 |
|---|---|---|
| 应急处理 | 扩容消费者 | 增加消费者实例数量或线程数 |
| 应急处理 | 消息转发 | 将堆积消息转发到新 Topic,用独立消费者消费 |
| 应急处理 | 临时丢弃 | 非核心业务可丢弃部分历史消息 |
| 根本治理 | 优化消费逻辑 | 减少单条消息处理耗时 |
| 根本治理 | 合理并发设计 | 调整 consumeThreadMin/consumeThreadMax |
| 根本治理 | 监控告警 | 建立堆积量监控,提前预警 |
深度解析
一、消息堆积的常见原因
先搞清楚 "为什么堆",才能对症下药:
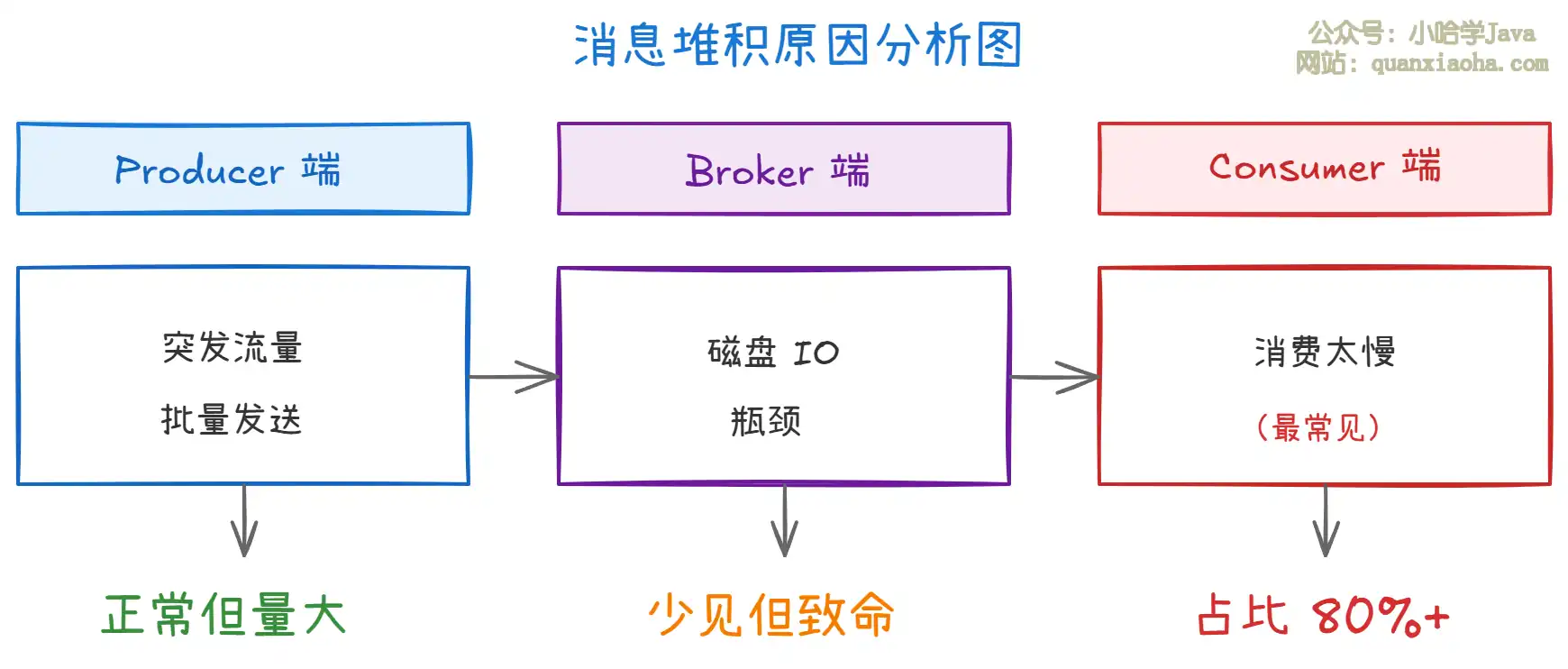
上图展示了消息堆积的三大来源。根据生产经验,Consumer 端消费能力不足是导致堆积最常见的原因,占比超过 80%。具体包括:
- 消费逻辑慢:比如消费消息时同步调用数据库、RPC 调用耗时过长、业务逻辑复杂等
- 消费端异常:代码 Bug 导致反复重试、消费者频繁重启、Full GC 停顿等
- 并发度不够:消费者实例数少、消费线程数配置过低
- 顺序消息瓶颈:使用顺序消息时,同一 MessageQueue 只能单线程消费,吞吐量受限
二、应急处理方案
方案 1:扩容消费者(最快见效)
// 方式一:增加消费者实例(部署更多节点)
// 注意:消费者实例数不能超过 Topic 的 MessageQueue 数量
// 例如 Topic 有 16 个 Queue,最多只能部署 16 个消费者实例
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("consumer_group");
consumer.setConsumeThreadMin(20); // 最小消费线程数,默认 20
consumer.setConsumeThreadMax(100); // 最大消费线程数,默认 20
- 原理:增加消费端的并行处理能力
- 注意:消费者实例数受限于 MessageQueue 数量,超过后新实例会 "空转",不会分配到 Queue
- 适用场景:消费逻辑本身不太慢,只是并发度不够
方案 2:消息转发到新 Topic(堆积量巨大时)
// Step 1:写一个临时消费者,快速消费堆积消息并转发到新 Topic
DefaultMQPushConsumer tempConsumer = new DefaultMQPushConsumer("temp_group");
tempConsumer.subscribe("original_topic", "*");
tempConsumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(
List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
for (MessageExt msg : msgs) {
// 快速转发到新 Topic,不做业务处理
Message newMsg = new Message("new_topic", msg.getBody());
producer.send(newMsg);
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
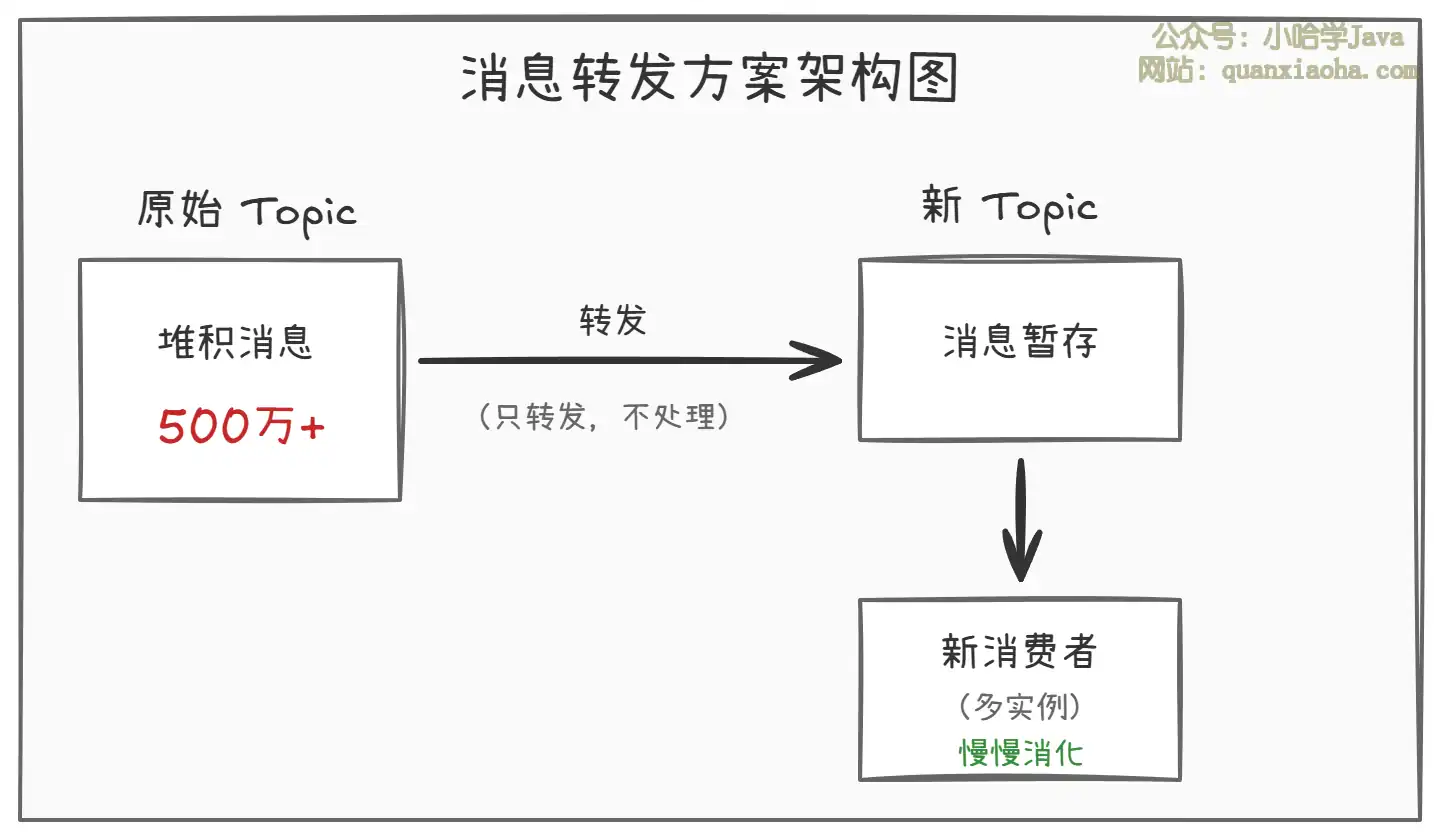
上图展示了消息转发方案的核心思路:用一个轻量级的临时消费者快速将堆积消息从原 Topic 转发到新 Topic,然后由新的消费者集群按照自己的节奏慢慢消费。
- 为什么有效:原 Topic 的堆积被快速清理,恢复了正常的生产消费链路;新 Topic 的消费可以按业务能力慢慢来
- 关键点:转发逻辑要尽量轻量,不做任何业务处理,纯粹 "搬运" 消息
- 适用场景:堆积量特别大(百万级以上),且消费逻辑确实很慢
方案 3:临时丢弃非核心消息
// 对于非核心业务,可以跳过历史消息,从最新消息开始消费
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);
// 或者设置消息过期时间,过期自动丢弃
// 在 Broker 端配置:fileReservedTime = 48(小时)
- 适用场景:日志类、监控类等对历史数据不敏感的业务
- 注意:核心业务链路绝对不能用这种方式,会丢数据
三、根本治理方案
1. 优化消费逻辑
// 反面教材:同步调用多个外部服务
MessageListenerConcurrently listener = (msgs, context) -> {
for (MessageExt msg : msgs) {
userService.getUser(msg.getUserId()); // RPC 调用 1:200ms
orderService.getOrder(msg.getOrderId()); // RPC 调用 2:300ms
inventoryService.deduct(msg.getSkuId()); // RPC 调用 3:150ms
// 单条消息处理耗时 650ms,极容易堆积!
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
};
// 正面教材:批量操作 + 异步化
MessageListenerConcurrently listener = (msgs, context) -> {
// 批量查询,减少 RPC 次数
List<Long> userIds = msgs.stream()
.map(m -> parseUserId(m)).collect(Collectors.toList());
Map<Long, User> userMap = userService.batchGetUsers(userIds); // 一次批量查
// 本地缓存热点数据
// 异步处理非核心逻辑
CompletableFuture.runAsync(() -> {
notifyService.sendNotification(msgs); // 非核心逻辑异步处理
}, asyncExecutor);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
};
2. 合理设置消费并发度
| 参数 | 默认值 | 建议值 | 说明 |
|---|---|---|---|
consumeThreadMin |
20 | 根据业务调整 | 最小消费线程数 |
consumeThreadMax |
20 | 50-200 | 最大消费线程数 |
pullBatchSize |
32 | 32-100 | 每次拉取消息批量大小 |
consumeMessageBatchMaxSize |
1 | 10-50 | 每次消费消息批量大小 |
3. 避免顺序消息导致的堆积
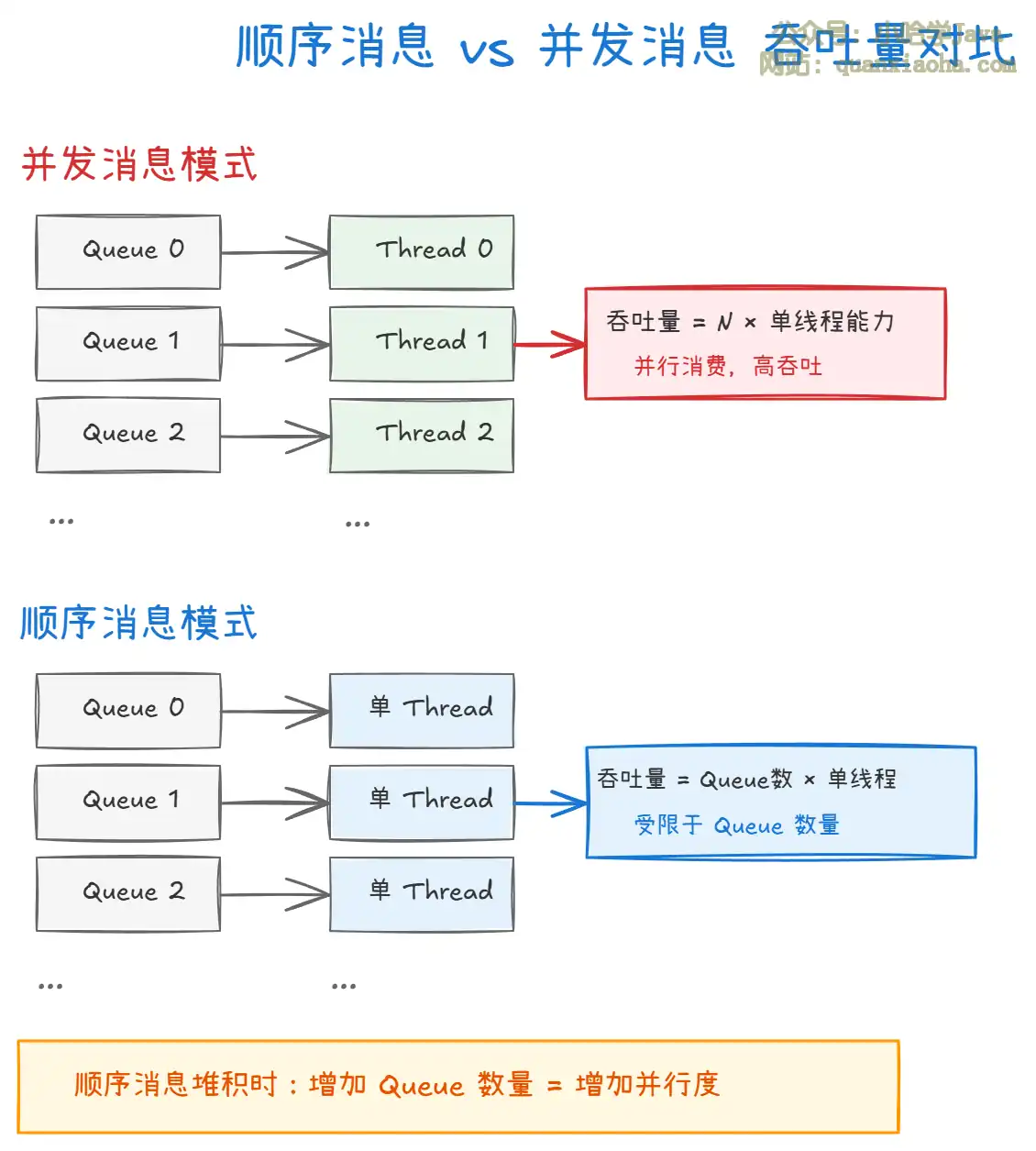
上图对比了并发消息和顺序消息的吞吐量差异。对于顺序消息,由于同一个 MessageQueue 只能被一个消费者线程顺序消费,吞吐量直接受限于 Queue 的数量。
- 如果业务确实需要顺序消费,可以通过 增加 Topic 的 Queue 数量 来提升并行度
- 例如:原来 4 个 Queue 只能 4 线程并发,扩到 16 个 Queue 就能 16 线程并发
4. 建立监控告警机制
// 通过 MQAdmin 工具监控堆积量
// 命令:mqadmin consumerProgress -g consumer_group
// 核心监控指标:
// 1. Diff(堆积量):Consumer Offset 与 Broker Offset 的差值
// 2. 消费 TPS:每秒消费消息数
// 3. 消费延迟:消息从产生到被消费的时间差
// 告警阈值建议(根据业务 SLA 调整):
// - Diff > 10000 条:P2 告警
// - Diff > 100000 条:P1 告警
// - 消费延迟 > 5 分钟:P0 告警
四、处理流程总结
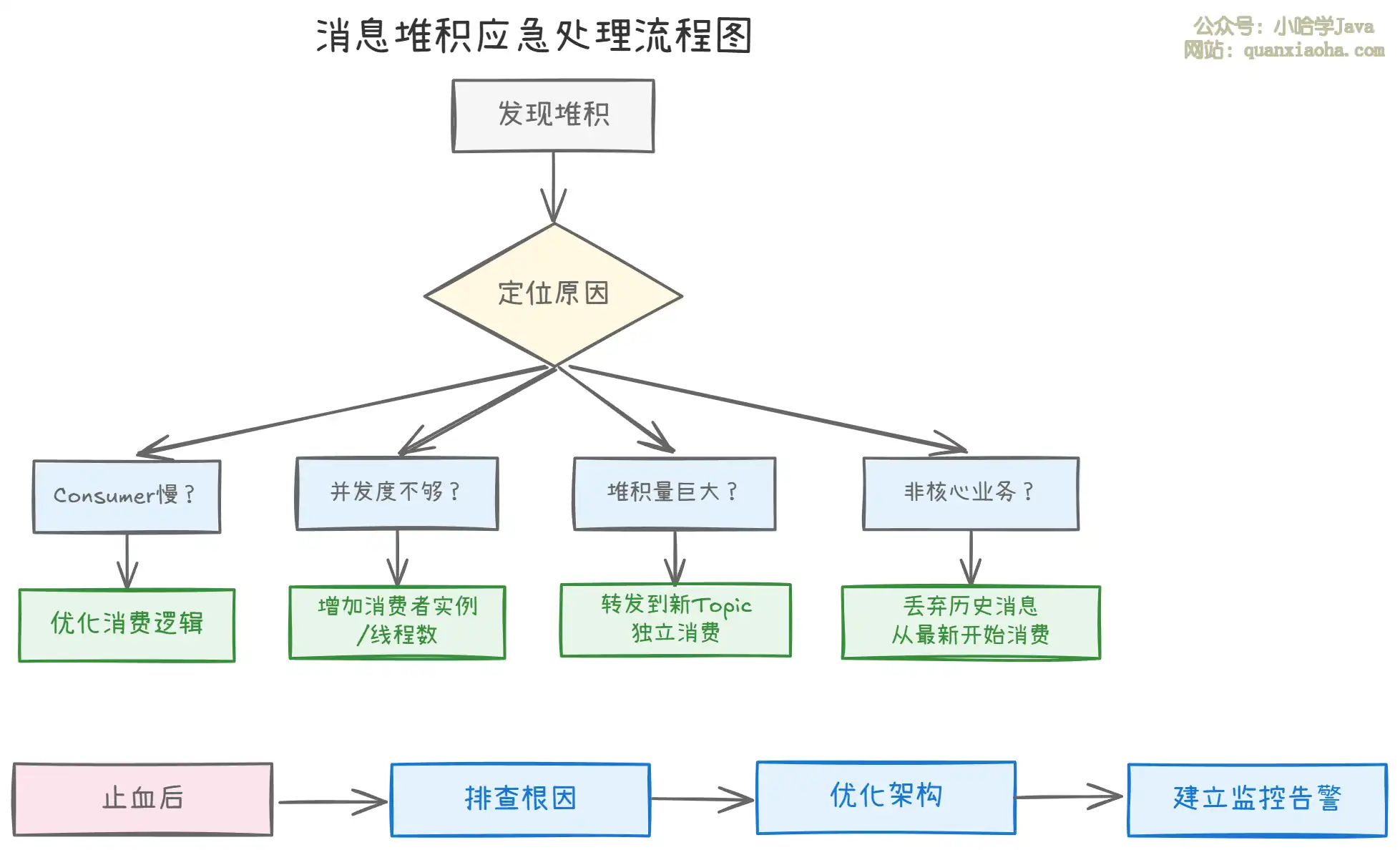
上图展示了从发现堆积到最终根治的完整处理流程。核心原则是:先快速止血恢复服务,再排查根因彻底治理。
面试高频追问
-
追问一:消费者实例数和 MessageQueue 数量是什么关系?
消费者实例数 ≤ MessageQueue 数量时,每个实例至少分配一个 Queue;超过 Queue 数量的实例会空闲。所以扩容消费者前先确认 Queue 数量。
-
追问二:消息堆积会导致什么严重后果?
磁盘打满导致 Broker 拒绝写入、消息过期被清理导致数据丢失、消费延迟导致业务逻辑时效性丧失。
-
追问三:RocketMQ 怎么查看消息堆积情况?
使用
mqadmin consumerProgress命令查看每个消费者组的 Diff 值,或在 Dashboard 控制台监控 Consumer Lag。 -
追问四:广播消费模式会有堆积问题吗?
广播模式下每个消费者都会消费所有消息,堆积只和单个消费者自身消费能力有关,扩容消费者并不能分担压力,需要通过优化消费逻辑来解决。
常见面试变体
- 变体一:线上 RocketMQ 消费延迟很高怎么排查?
- 变体二:如何避免 RocketMQ 消息堆积?
- 变体三:RocketMQ 消费者怎么提高消费速度?
- 变体四:百万级消息堆积,如何快速恢复?
记忆口诀
"先止血、再治病"——应急三板斧:扩容(加实例/线程)、转发(新 Topic 缓冲)、丢弃(非核心业务);根治四件套:优化逻辑、调并发、加 Queue、建监控。
总结
消息堆积的处理核心是 "先止血再根治":应急阶段通过扩容消费者、消息转发、临时丢弃等手段快速恢复;根治阶段从优化消费逻辑、合理配置并发度、增加 Queue 数量、建立监控告警等方面入手。其中 80% 以上的堆积根因在消费端,所以日常开发中要格外关注消费逻辑的性能。