什么是 Java 序列化与反序列化?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
概念理解:面试官不仅仅是想知道 "对象变字节、字节变对象" 这个定义,更是想考察你是否理解序列化的本质——将内存中的对象状态转换为可存储/可传输的格式。
-
实践应用:序列化在实际开发中无处不在(RPC 调用、缓存存储、消息队列、深拷贝等),考察你是否知道何时需要序列化,以及如何选择合适的序列化方案。
-
安全意识:Java 原生序列化存在安全漏洞(反序列化攻击),考察你是否了解这些风险以及如何在生产环境中规避。
核心答案
序列化是将 Java 对象转换为字节序列的过程,便于存储到文件、数据库或进行网络传输;反序列化是将字节序列恢复为 Java 对象的过程。
| 操作 | 输入 | 输出 | 典型场景 |
|---|---|---|---|
| 序列化 | Java 对象 | 字节序列 | 存储到磁盘、网络传输、分布式调用 |
| 反序列化 | 字节序列 | Java 对象 | 从磁盘读取、接收网络数据、RPC 响应 |
一句话理解:序列化让对象 "离开 JVM"(持久化/传输),反序列化让对象 "回到 JVM"(恢复使用)。
深度解析
一、序列化与反序列化流程
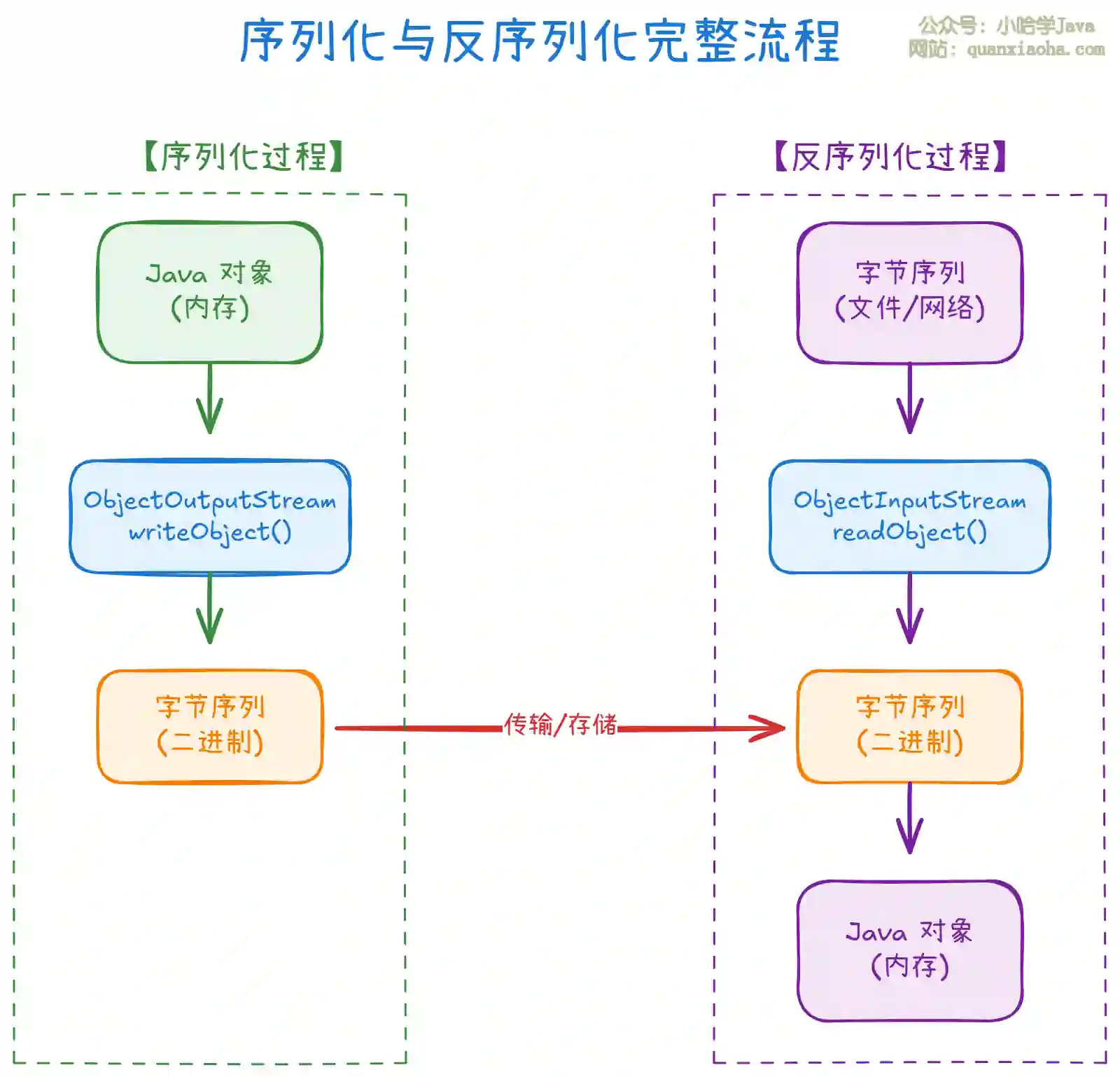
上图展示了序列化与反序列化的完整流程。关键要点:
-
序列化阶段:通过
ObjectOutputStream.writeObject()将内存中的 Java 对象转换为字节序列,可以写入文件、存入数据库、或通过网络发送。 -
传输/存储阶段:字节序列以二进制形式存在,不依赖于具体的 JVM,可以跨机器、跨时间传输。
-
反序列化阶段:通过
ObjectInputStream.readObject()将字节序列重新构建为内存中的 Java 对象,恢复对象的状态。
二、Java 原生序列化实现
基本用法
import java.io.*;
// 实现 Serializable 接口(标记接口,无方法)
class User implements Serializable {
private static final long serialVersionUID = 1L; // 版本号
private String name;
private Integer age;
private transient String password; // transient 关键字:不参与序列化
// 构造方法、getter、setter...
public User(String name, Integer age, String password) {
this.name = name;
this.age = age;
this.password = password;
}
@Override
public String toString() {
return "User{name='" + name + "', age=" + age + ", password='" + password + "'}";
}
}
public class SerializationDemo {
public static void main(String[] args) throws Exception {
User user = new User("张三", 25, "123456");
// ===== 序列化:对象 → 字节 =====
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(user);
byte[] bytes = bos.toByteArray();
System.out.println("序列化完成,字节数: " + bytes.length);
// ===== 反序列化:字节 → 对象 =====
ByteArrayInputStream bis = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bis);
User deserializedUser = (User) ois.readObject();
System.out.println("反序列化结果: " + deserializedUser);
// 输出: User{name='张三', age=25, password='null'}
// 注意:password 被 transient 修饰,反序列化后为 null
}
}
关键点说明
| 关键字/接口 | 作用 | 说明 |
|---|---|---|
Serializable |
标记接口 | 表示类可序列化,无任何方法 |
serialVersionUID |
版本标识 | 保证序列化/反序列化版本一致性 |
transient |
排除字段 | 被修饰的字段不参与序列化 |
static |
类变量 | 不参与序列化(属于类,不属于对象) |
三、serialVersionUID 的重要性
// 场景:序列化后,类结构发生了变化
class User implements Serializable {
private static final long serialVersionUID = 1L; // 必须显式定义!
private String name;
// private String email; // 新增字段后,如果不定义 serialVersionUID 会报错!
}
为什么必须显式定义 serialVersionUID?
- 如果不定义,JVM 会根据类结构自动生成一个版本号
- 类结构变化(新增/删除字段)后,自动生成的版本号会改变
- 反序列化时版本号不匹配,抛出
InvalidClassException
最佳实践:所有可序列化的类都必须显式定义 serialVersionUID,使用 IDE 自动生成即可。
四、常见序列化方案对比
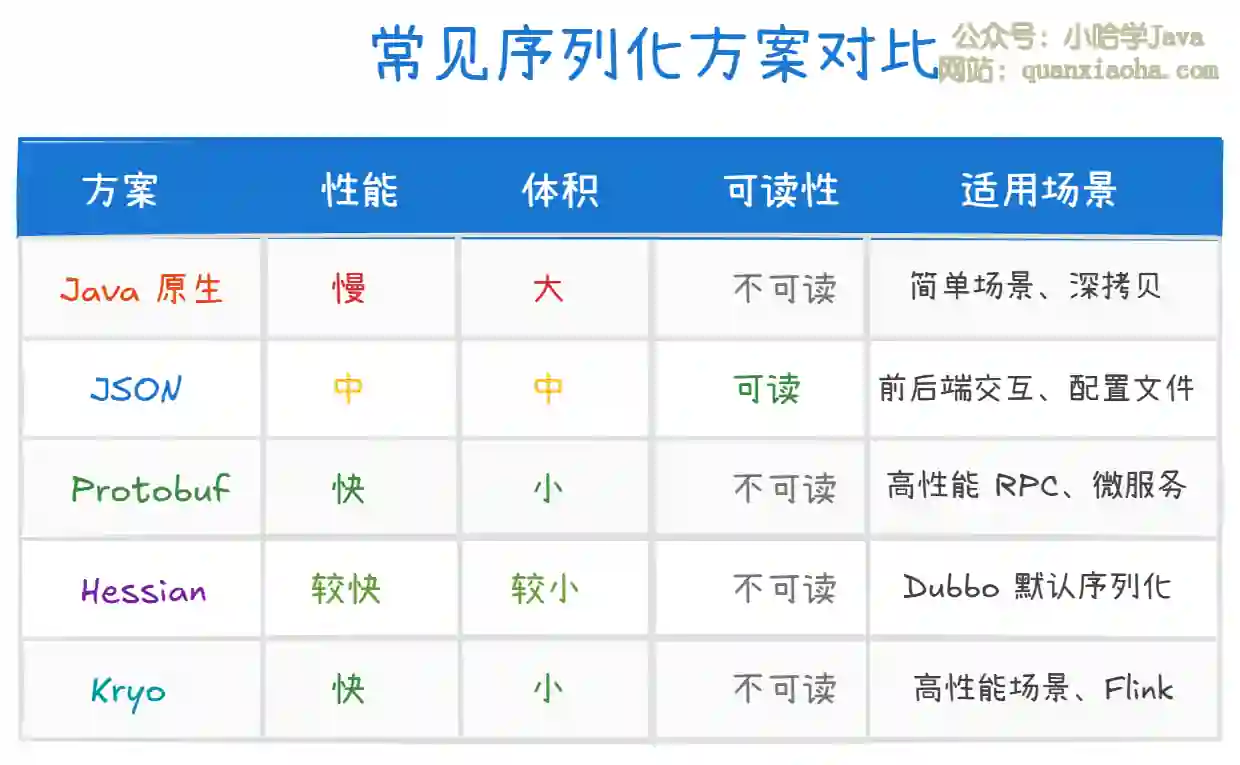
上图对比了常见序列化方案的特点。选择建议:
-
Java 原生序列化:仅用于简单场景或深拷贝,生产环境不推荐(性能差、体积大、有安全风险)
-
JSON(Jackson/Gson):前后端交互首选,可读性好,调试方便,但性能和体积不如二进制方案
-
Protobuf:高性能 RPC 场景首选,需要定义
.proto文件,跨语言支持好 -
Hessian/Kryo:Java 内部 RPC 场景,无需定义 schema,性能优秀
五、序列化的安全风险
// 危险!不要反序列化不可信的数据
ObjectInputStream ois = new ObjectInputStream(untrustedInput);
Object obj = ois.readObject(); // 可能触发恶意代码执行!
Java 原生序列化的安全风险:
- 反序列化攻击:攻击者构造恶意的字节序列,反序列化时会执行任意代码(RCE)
- 典型案例:Apache Commons Collections 反序列化漏洞(2015 年)
- 解决方案:
- 避免使用 Java 原生序列化处理不可信数据
- 使用 JSON 等安全的序列化方案
- 使用白名单机制限制可反序列化的类
面试高频追问
-
Serializable和Externalizable有什么区别?接口 序列化控制 性能 复杂度 Serializable自动序列化所有非 transient字段较低 简单 Externalizable完全自定义 writeExternal()和readExternal()较高 复杂 生产环境推荐使用
Externalizable或第三方序列化框架,性能更好。 -
为什么
static字段不参与序列化?序列化的是对象的状态,而
static字段属于类,不属于对象。所有对象共享同一个static字段,序列化它没有意义。 -
父类没有实现
Serializable,子类可以序列化吗?可以,但父类的字段不会被序列化。反序列化时,父类会调用无参构造方法初始化字段。
常见面试变体
- 变体一:"
transient关键字的作用是什么?" - 变体二:"为什么阿里开发手册不建议使用 Java 原生序列化?"
- 变体三:"RPC 框架中常用的序列化方案有哪些?"
记忆口诀
对象变字节叫序列,字节变对象叫反序列;
Serializable 标记接口,serialVersionUID 版本要定好;
transient 不参与,原生序列化有风险要少用。
总结
序列化将 Java 对象转换为字节序列,便于存储和传输;反序列化将字节恢复为对象。Java 原生序列化通过 Serializable 接口实现,但存在性能差、体积大、安全风险等问题,生产环境推荐使用 JSON、Protobuf 等更优方案。务必显式定义 serialVersionUID,敏感字段使用 transient 排除。