RabbitMQ 是如何保证高可用的?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
集群方案掌握度:面试官不仅仅是想知道你知道有集群这回事,更是想确认你是否清楚普通集群、镜像队列、仲裁队列三者的区别和演进关系。
-
故障恢复机制:是否理解主从切换、脑裂处理、节点恢复等故障场景下的实际行为。
-
生产实践意识:能否结合实际场景说明高可用架构的部署方案(Federation、Shovel、负载均衡等),而不只是停留在概念层面。
核心答案
RabbitMQ 的高可用从 四个层面 来保证:
| 层面 | 机制 | 解决什么问题 |
|---|---|---|
| 集群层面 | 多节点组成集群,元数据共享 | 单点故障 |
| 队列层面 | 镜像队列 / 仲裁队列实现数据复制 | 数据丢失 |
| 网络层面 | Federation / Shovel 实现跨集群通信 | 异地多活、跨机房 |
| 接入层面 | HAProxy + Keepalived 负载均衡 + VIP 漂移 | 透明故障切换 |
深度解析
一、普通集群——只解决元数据共享
普通集群是最基础的部署方式。它的核心思路是:每个节点都有全量的元数据(Exchange、Binding、Queue 的声明信息),但队列的实际数据只存在于主节点上。
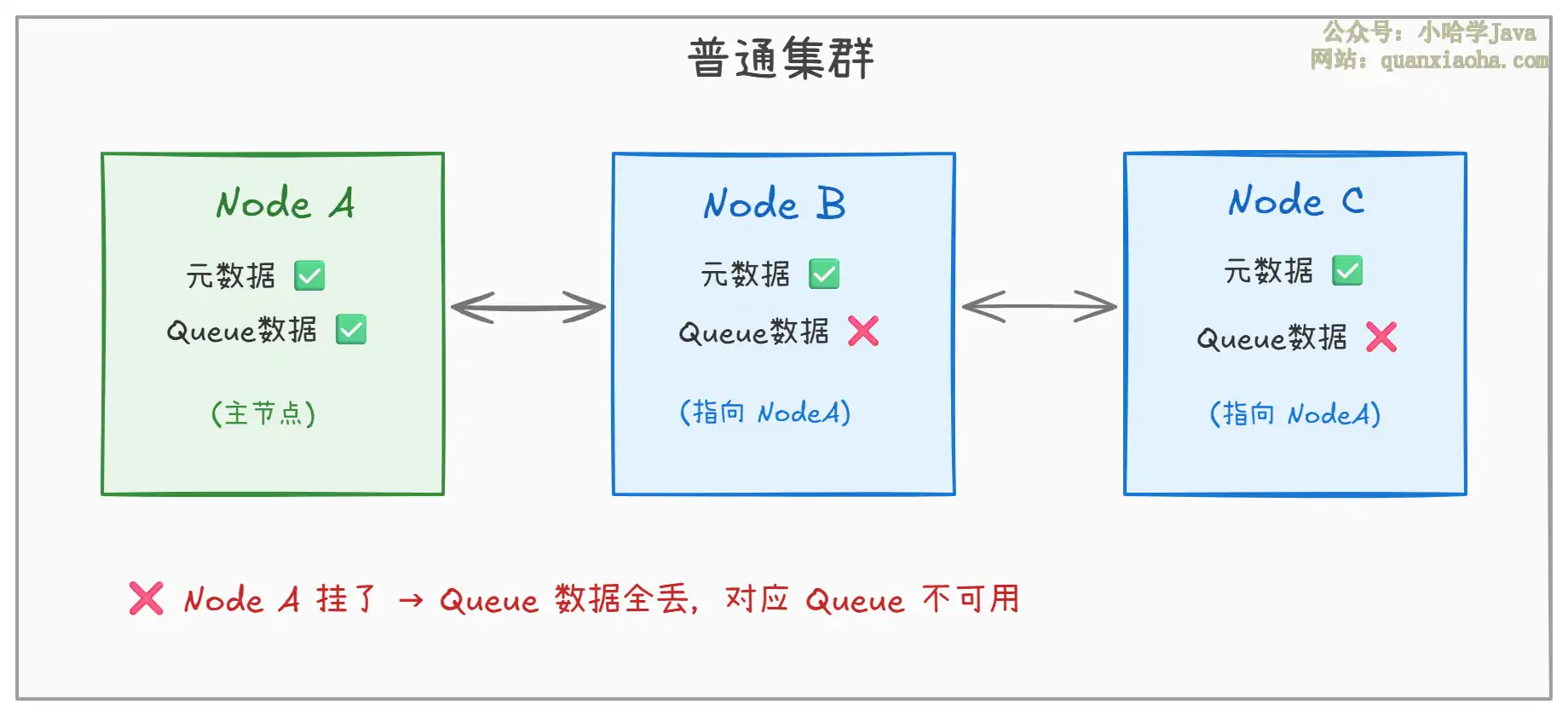
- 元数据同步:每个节点都知道集群中有哪些
Queue、Exchange、Binding,消费者连接任何节点都能找到Queue所在的主节点 - 数据不复制:消息本身只存在主节点,其他节点收到消费请求时会临时从主节点拉取数据(带来网络开销)
- 致命缺陷:主节点一旦挂了,该节点上的
Queue数据直接丢失,直到主节点恢复才能重新可用
所以普通集群解决的是 "节点挂了不影响路由查找",但不解决 "数据不丢"。
二、镜像队列——主从复制(已弃用)
镜像队列就是在普通集群的基础上,把 Queue 的数据复制到其他节点上。
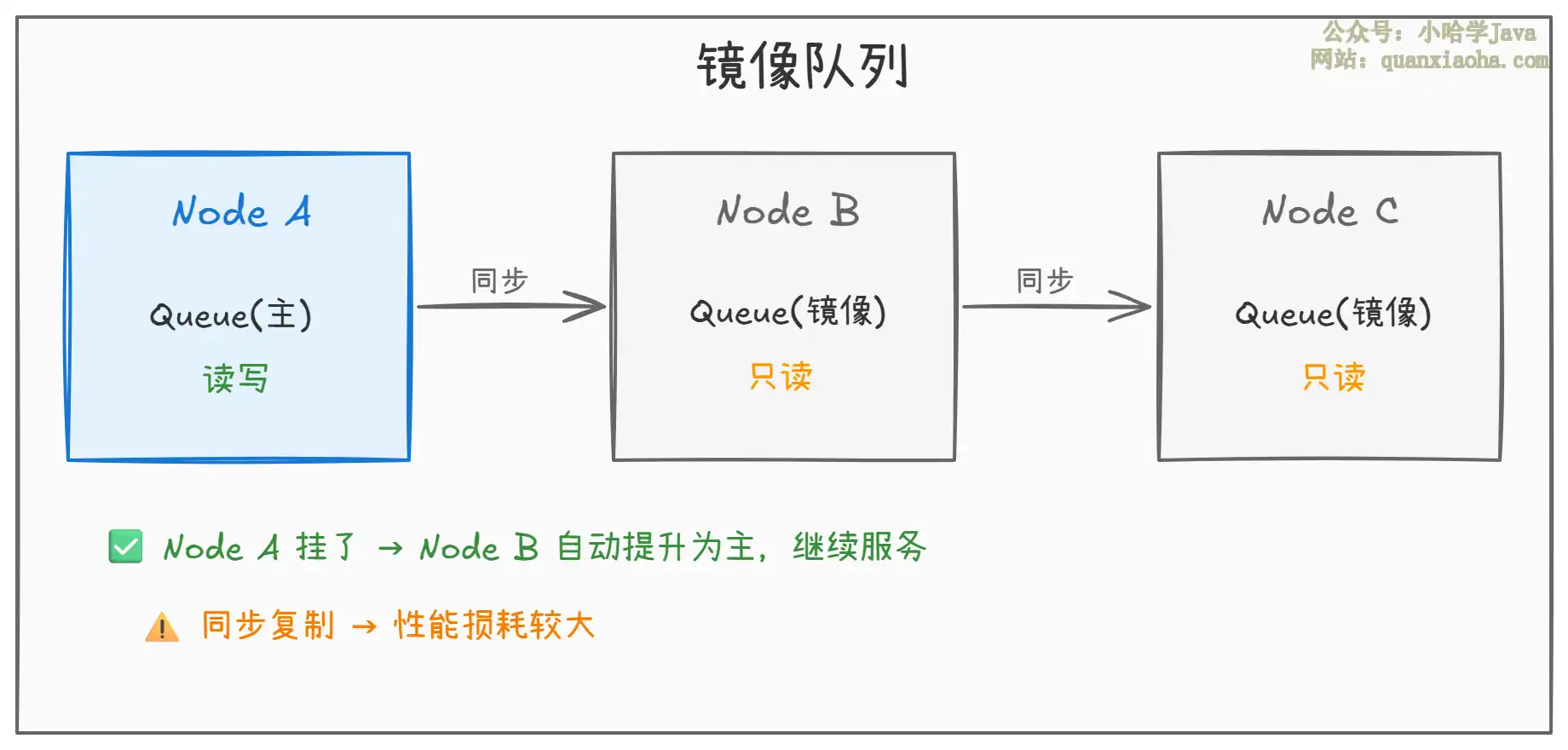
- 主从模式:
Queue有一个Master和多个Slave,写操作先到Master,再同步到Slave - 自动故障切换:
Master挂了,最老的Slave被提升为新的Master - 同步策略:通过
ha-sync-mode配置,automatic为同步复制(安全但慢),manual为异步复制(快但可能丢数据)
但这里有个大坑:镜像队列在 RabbitMQ 3.13 已被弃用,RabbitMQ 4.x 彻底移除。原因是什么呢?
- 主从同步采用
Guaranteed Multicast机制,实现复杂且不够可靠 - 脑裂场景处理不够优雅
- 性能开销大,特别是在节点数多的时候
面试时主动提到这个版本差异,面试官会觉得你关注技术演进,加分。
三、仲裁队列——当前推荐方案
仲裁队列(Quorum Queue)是 RabbitMQ 3.8 引入、官方大力推荐的新方案,基于 Raft 共识算法 实现。
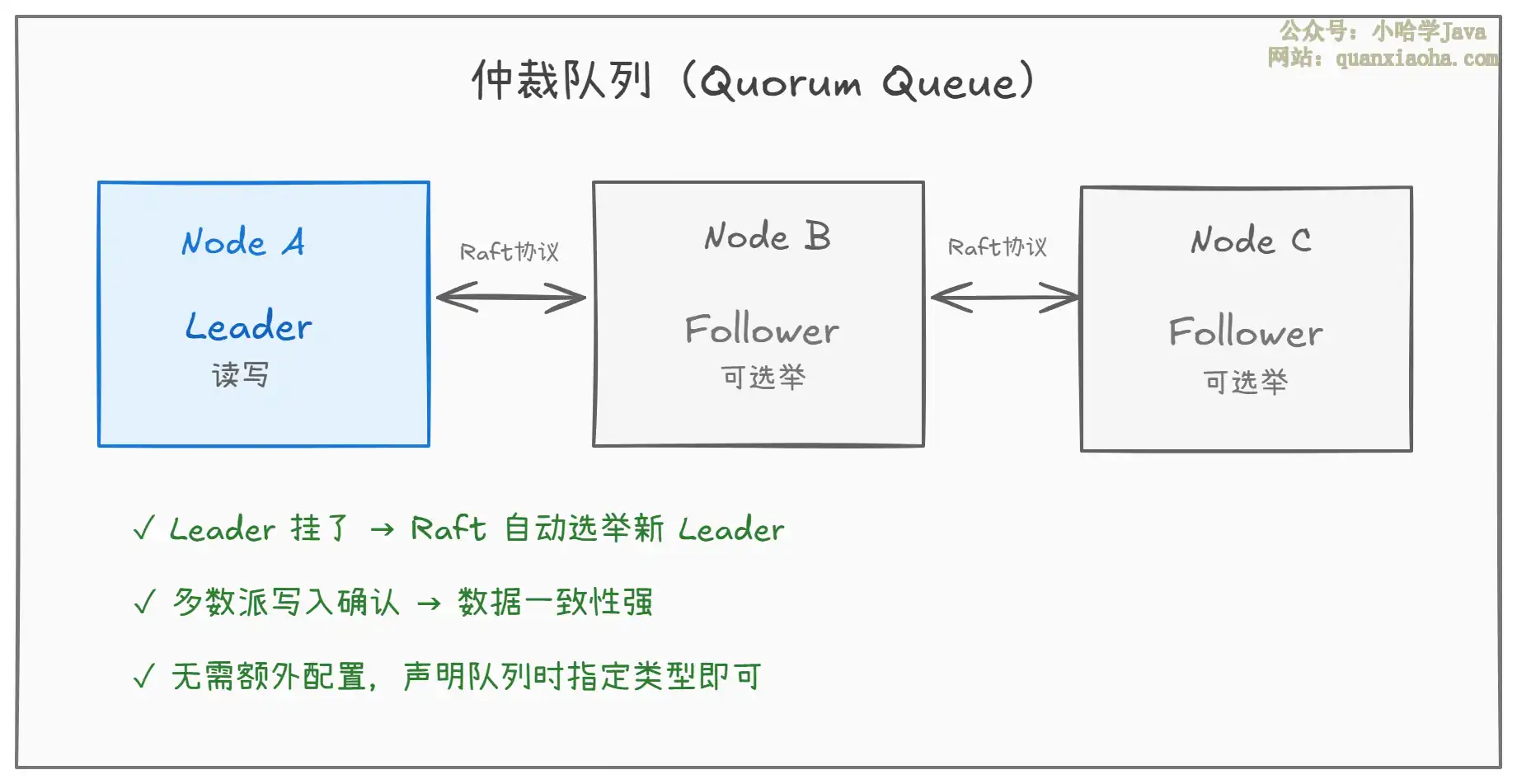
- Raft 共识:写入操作需要大多数节点(
quorum)确认,默认 3 节点集群需要 2 个确认 - 自动选举:
Leader故障后,Follower通过Raft选举自动选出新Leader,无需人工干预 - 声明方式简单:只需要在声明队列时设置
x-queue-type: quorum即可
| 对比维度 | 镜像队列(已弃用) | 仲裁队列(推荐) |
|---|---|---|
| 共识算法 | Guaranteed Multicast |
Raft |
| 数据安全 | 异步同步可能丢数据 | 多数派确认,强一致 |
| 故障恢复 | 需要额外配置 | Raft 自动选举 |
| 性能 | 同步模式下较慢 | 比 Mirror Queue 更优 |
| 版本支持 | 3.13 弃用,4.x 移除 | 3.8+ 支持,4.x 默认推荐 |
一句话总结:新项目直接用仲裁队列,别犹豫。
四、Federation 与 Shovel——跨集群高可用
如果你的业务需要跨机房、跨地域部署,单集群就不够了。RabbitMQ 提供了两种跨集群通信的插件:
Federation(联邦):
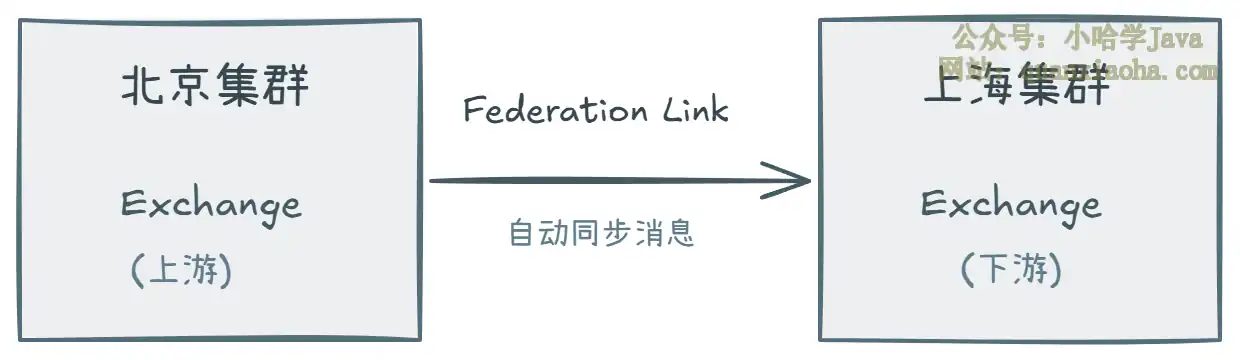
- 不需要集群间节点互相发现,通过 AMQP 协议在
Exchange之间转发消息 - 支持单向和双向联邦
- 适合跨地域、松耦合的场景
Shovel(铲子):
- 比
Federation更灵活,可以精确控制消息的搬运规则 - 支持跨不同版本、不同类型的消息中间件之间的数据迁移
- 适合数据迁移、特定队列的跨集群同步
五、HAProxy + Keepalived——接入层高可用
有了集群和数据复制,但客户端怎么做到透明切换?总不能让业务代码里写死 IP 吧。
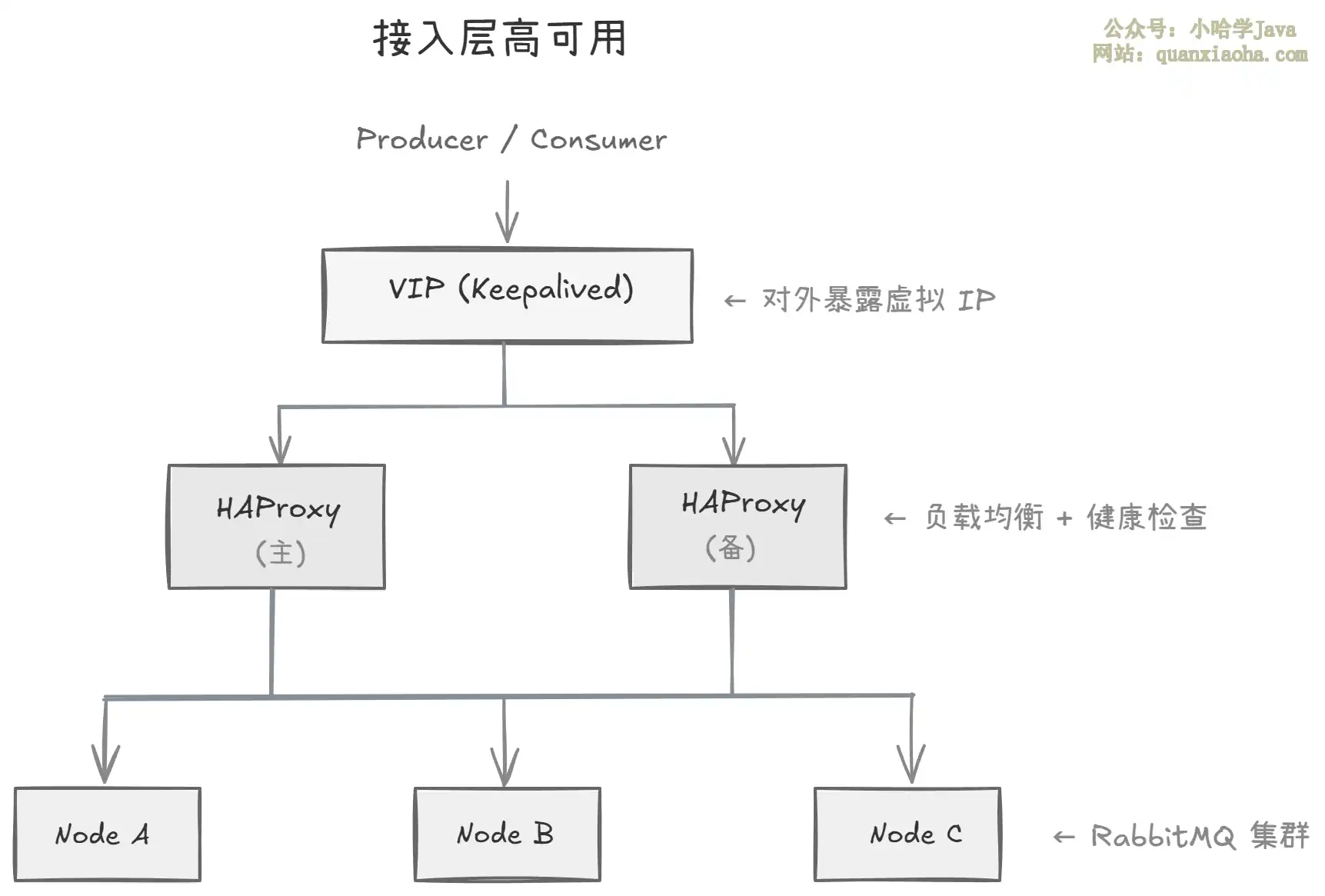
- HAProxy:做四层或七层负载均衡,定期对 RabbitMQ 节点做健康检查,自动剔除故障节点
- Keepalived:提供
VIP(虚拟 IP),主HAProxy挂了自动VIP漂移到备节点 - 客户端透明:业务代码只连
VIP,完全感知不到后端节点的变化
这才是生产环境完整的部署方案。面试时把这一整套画出来,面试官基本就不会再追问了。
面试高频追问
-
仲裁队列的性能比镜像队列好吗?
整体上是的。仲裁队列基于
Raft的多数派写入,虽然每次写入需要多数节点确认,但实现更简洁高效。而且仲裁队列在消息持久化方面做了很多优化(如 WAL 预写日志),吞吐量在大多数场景下优于镜像队列。 -
发生脑裂怎么办?
普通集群和镜像队列可以通过配置
cluster_partition_handling来处理:pause_minority(少数派自动暂停)是生产环境推荐策略。仲裁队列基于Raft算法本身就能处理网络分区,不需要额外配置。 -
如何监控 RabbitMQ 集群健康状态?
RabbitMQ 自带 Management 插件提供 HTTP API 和 Web 界面;生产环境建议配合
Prometheus + Grafana做指标监控,重点关注队列深度、消息吞吐量、连接数、节点内存和磁盘使用率。
常见面试变体
- "RabbitMQ 集群中某个节点挂了会怎样?消息会丢吗?"
- "镜像队列和仲裁队列有什么区别?你们生产环境用的哪个?"
- "RabbitMQ 如何实现跨机房部署?"
记忆口诀
高可用四层:集群共享元数据、队列数据要复制(仲裁队列)、跨机房用 Federation、接入层 HAProxy + VIP。
仲裁队列优势:Raft 共识、多数派确认、自动选举、官方推荐。
总结
一句话:RabbitMQ 高可用从集群、队列复制、跨机房、接入层四个维度保障。生产环境标准方案是 仲裁队列 + HAProxy + Keepalived + 多节点集群。面试时重点讲仲裁队列(Raft 共识、自动选举),顺带提一句镜像队列已弃用,最后补上接入层负载均衡方案,这道题就是满分回答。