HashMap 的 remove 方法是如何实现的?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
源码理解深度:面试官不仅仅是想知道 "调用 remove 删除元素" 这个表面行为,更是想知道你是否理解底层的删除逻辑,包括链表节点删除、红黑树节点删除、以及退树化条件。
-
数据结构掌握:考察你是否了解链表删除(指针操作)和红黑树删除(复杂旋转和变色)的区别,以及为什么红黑树删除更复杂。
-
边界条件意识:是否考虑删除头节点、尾节点、中间节点的不同处理,以及删除后是否需要退树化。
核心答案
HashMap 的 remove() 方法核心流程:定位桶 → 遍历查找 → 删除节点 → 更新指针/重构树 → 返回旧值。
| 删除场景 | 数据结构 | 操作方式 | 时间复杂度 |
|---|---|---|---|
| 桶为空 | - | 直接返回 null | O(1) |
| 单节点 | 链表 | 桶直接置 null | O(1) |
| 链表头节点 | 链表 | 桶指向 next | O(1) |
| 链表中间/尾部 | 链表 | 前驱节点.next = 当前.next | O(n) |
| 红黑树节点 | 红黑树 | 删除 + 旋转/变色 | O(log n) |
一句话总结:remove() 先通过 hash 定位桶,然后根据节点类型(链表或红黑树)执行不同的删除逻辑,删除后可能触发退树化(节点数 ≤ 6)。
深度解析
一、remove 方法整体流程
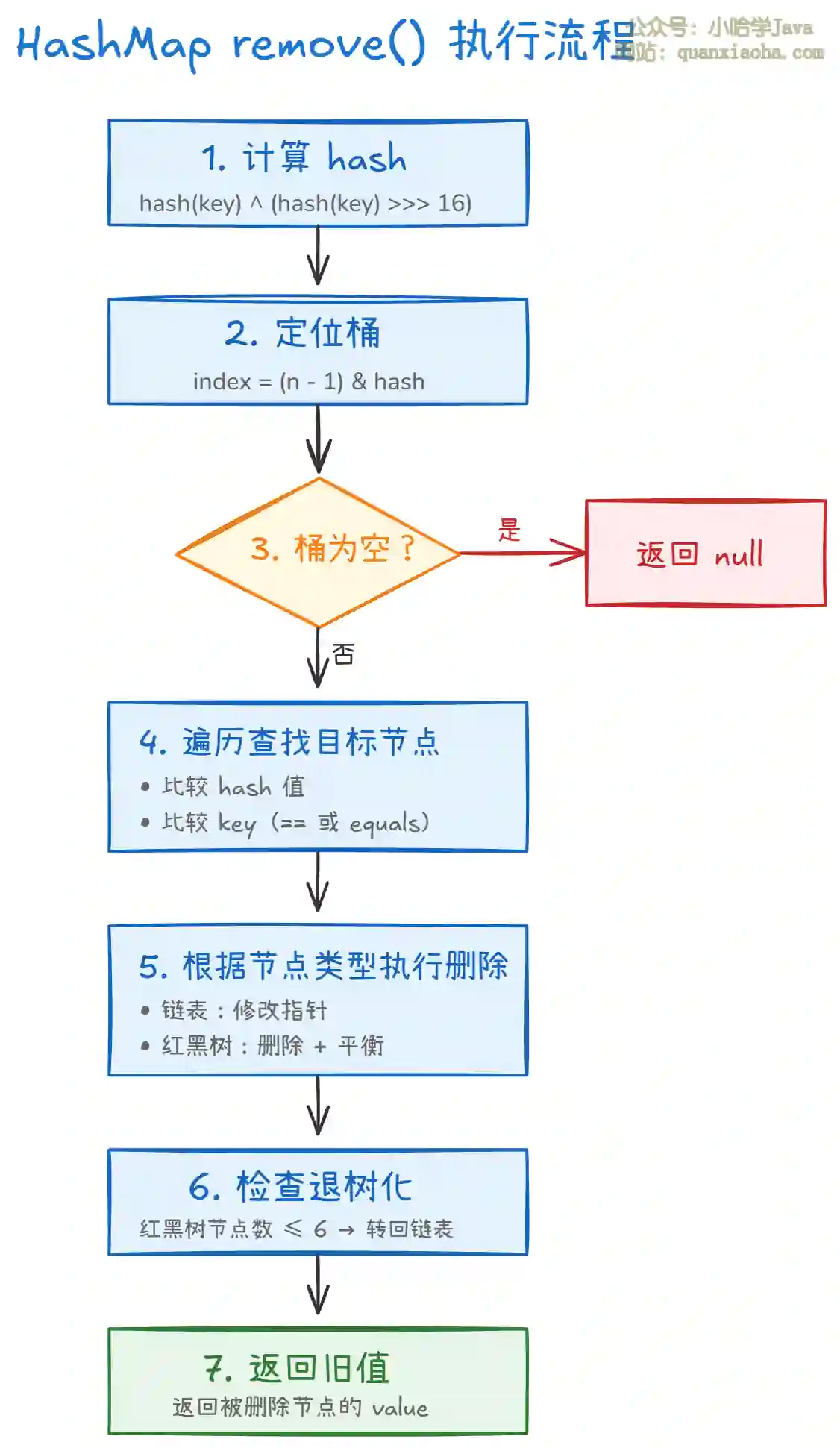
上图展示了 remove() 方法的完整执行流程。整体分为 7 个关键步骤:
- 步骤一 - 计算 hash:与
put()和get()一样,先计算 key 的扰动哈希值 - 步骤二 - 定位桶:通过
(n - 1) & hash定位目标桶 - 步骤三 - 空桶检查:如果桶为空,说明 key 不存在,直接返回 null
- 步骤四 - 遍历查找:遍历链表或红黑树,通过 hash 和 key 找到目标节点
- 步骤五 - 执行删除:根据节点类型执行不同的删除逻辑
- 步骤六 - 检查退树化:如果是红黑树,删除后检查是否需要退化为链表
- 步骤七 - 返回旧值:返回被删除节点的 value,如果没找到返回 null
二、链表节点删除
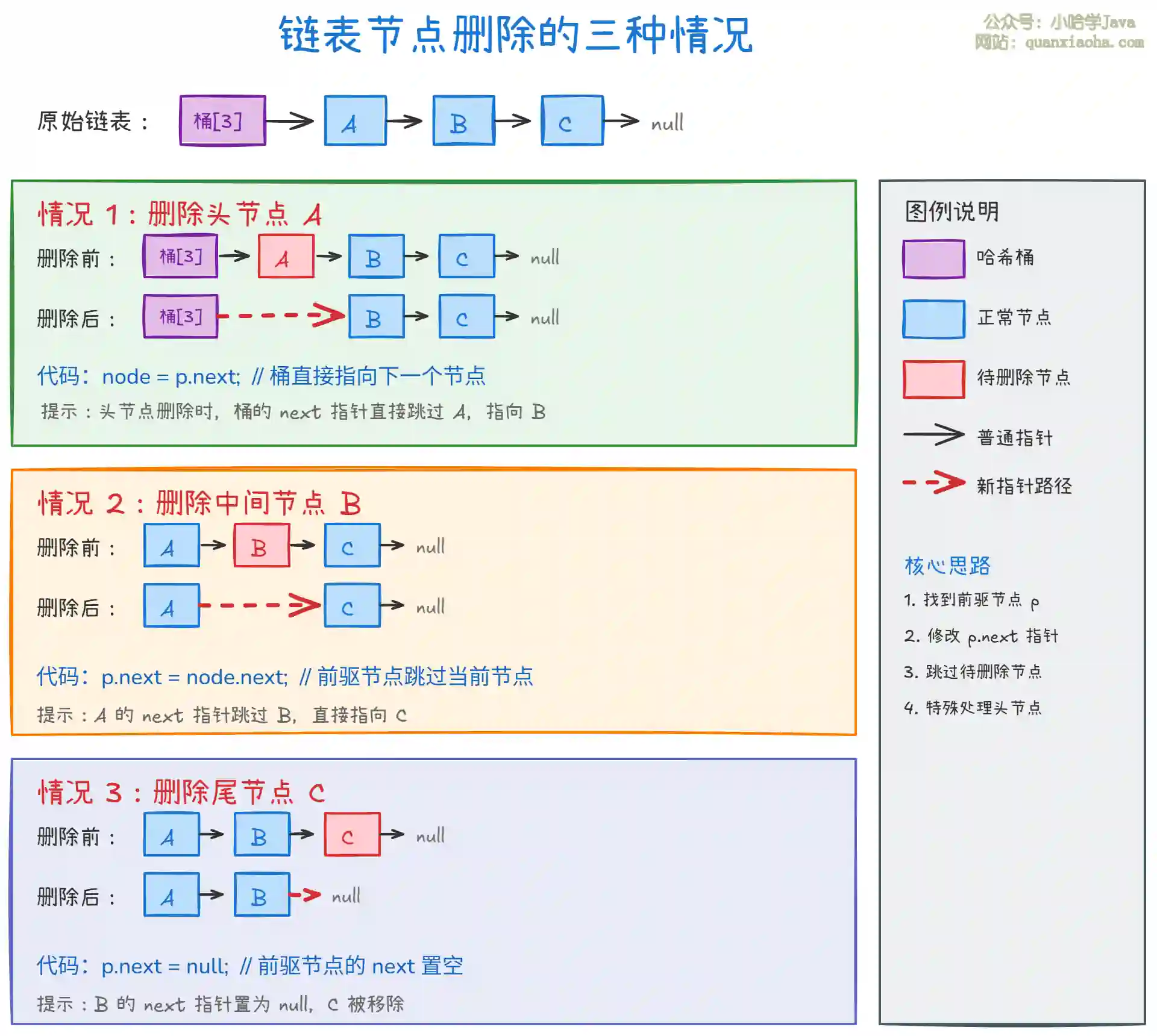
上图展示了链表删除的三种情况。核心操作:
- 删除头节点:直接让桶指向第二个节点,最简单
- 删除中间节点:前驱节点的
next指向当前节点的next,跳过当前节点 - 删除尾节点:前驱节点的
next置为null
链表删除核心代码:
// 链表删除核心逻辑
if (node == p) {
// 删除的是头节点,桶直接指向下一个
tab[index] = node.next;
} else {
// 删除的是中间或尾节点,前驱跳过当前节点
p.next = node.next;
}
// 记录被删除节点的 value,用于返回
e = node;
三、红黑树节点删除
红黑树删除比链表复杂得多,需要考虑树的平衡性:
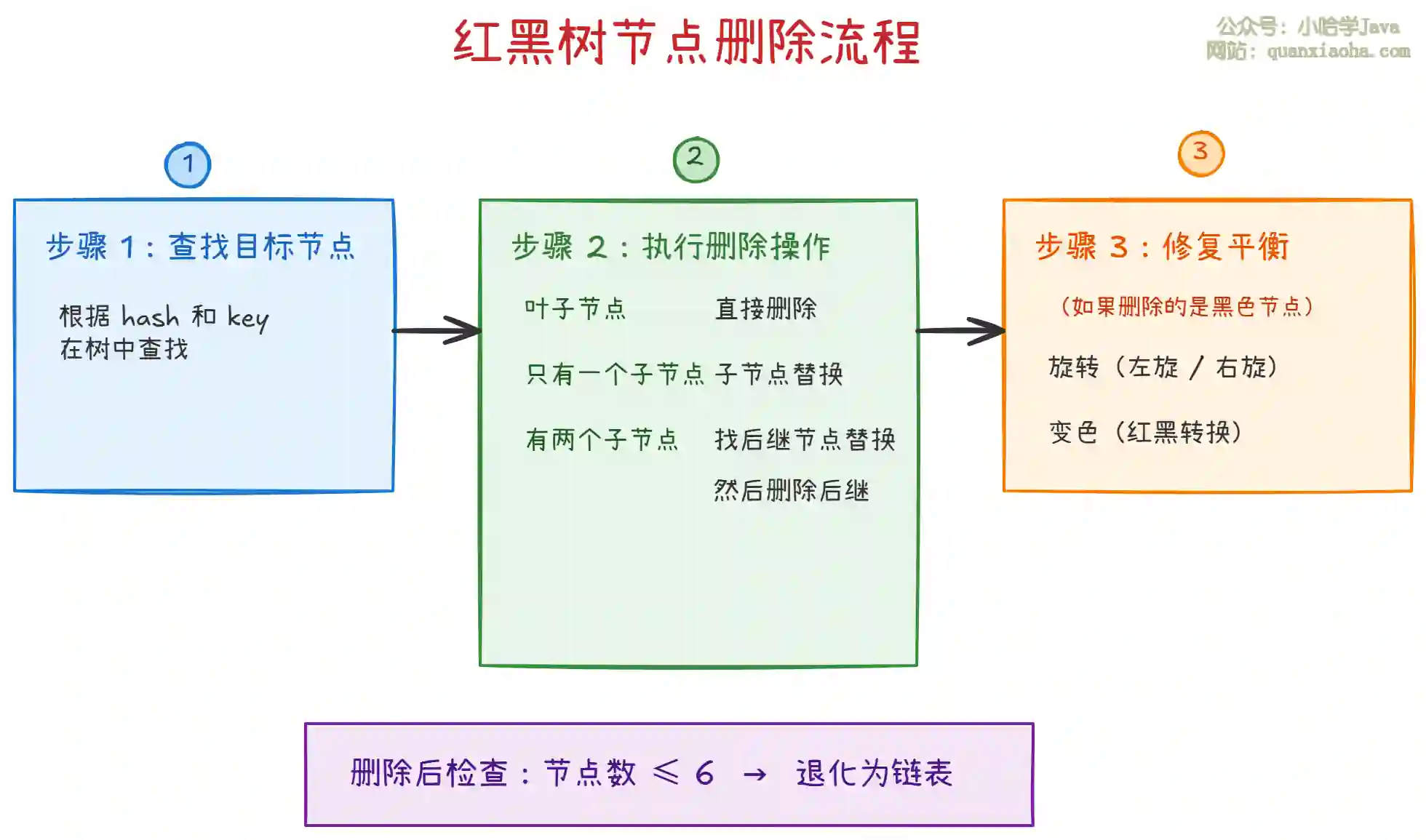
上图展示了红黑树删除的复杂性。关键点:
-
为什么要修复平衡? 红黑树要求从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。删除黑色节点会破坏这个性质。
-
旋转和变色:通过左旋、右旋、颜色调整来恢复平衡,可能需要多次操作。
-
退树化检查:删除后如果红黑树节点数 ≤ 6,会调用
untreeify()转回链表。
红黑树删除核心代码:
// 红黑树删除核心逻辑
if (node instanceof TreeNode) {
// 调用 TreeNode.removeTreeNode() 方法
// 内部处理:删除节点 + 旋转/变色修复 + 检查退树化
((TreeNode<K,V>)node).removeTreeNode(this, tab, false);
}
四、remove 源码核心片段
// HashMap.remove(Object key) 入口方法
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
// 核心删除方法
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
// 1. 定位桶
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
// 2. 查找目标节点
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p; // 头节点就是目标
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
// 红黑树查找
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
// 链表遍历查找
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e; // 找到了
break;
}
p = e; // p 记录前驱节点
} while ((e = e.next) != null);
}
}
// 3. 执行删除
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
// 红黑树删除
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
// 删除头节点
tab[index] = node.next;
else
// 删除中间或尾节点
p.next = node.next;
++modCount; // 修改次数 +1
--size; // 元素个数 -1
afterNodeRemoval(node); // 回调方法(LinkedHashMap 用)
return node; // 返回被删除的节点
}
}
return null; // 没找到,返回 null
}
五、删除后的退树化
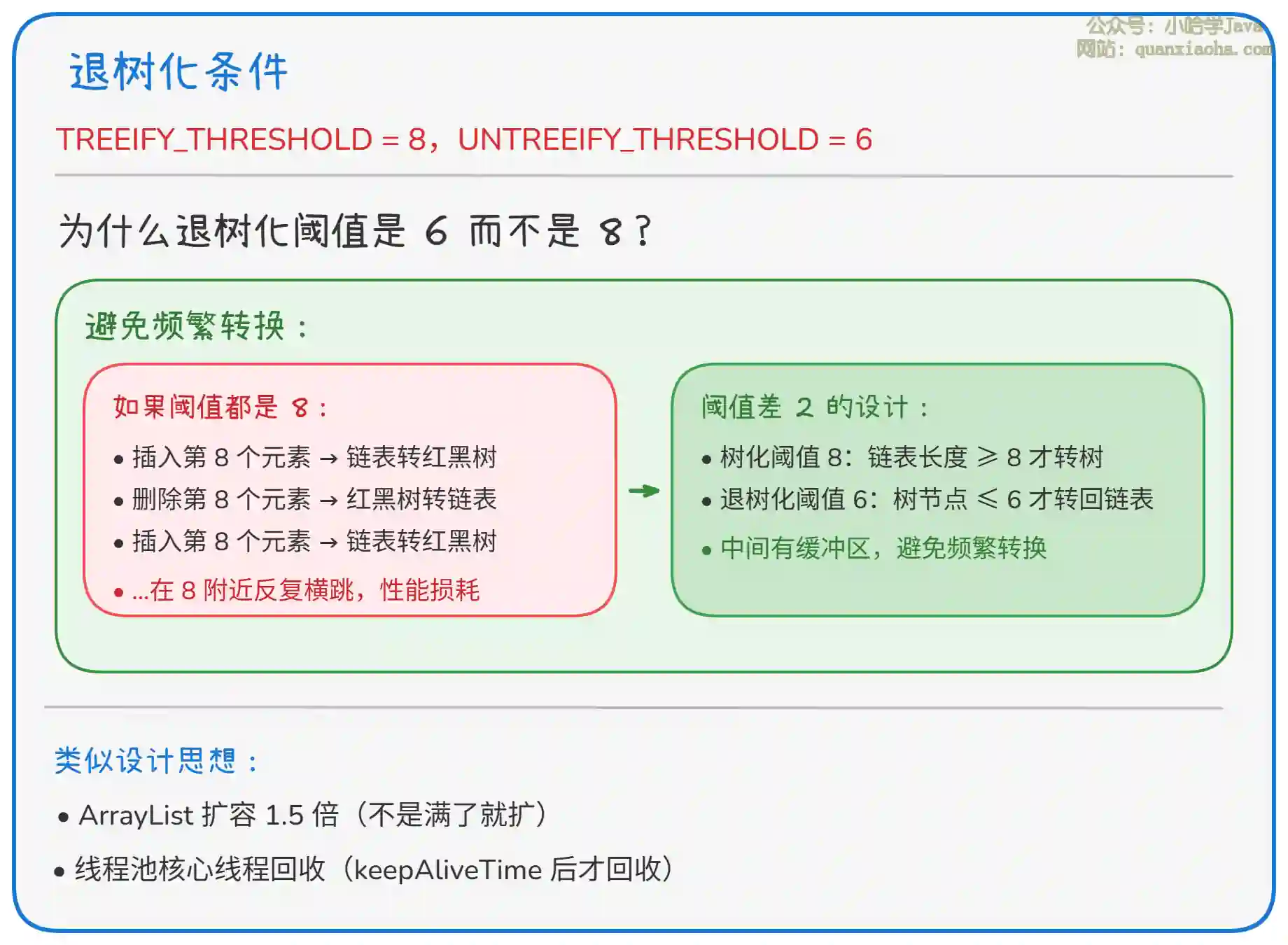
上图解释了退树化的设计思想。核心理解:
- 滞后设计:树化和退树化阈值差 2,是为了避免在边界值附近频繁转换
- 性能优化:转换本身有开销,滞后设计减少了转换次数
- 工程智慧:这种 "缓冲区" 思想在很多地方都有应用
六、remove vs clear
| 方法 | 功能 | 时间复杂度 | 实现 |
|---|---|---|---|
remove(key) |
删除指定 key | O(1) ~ O(n) | 定位 + 遍历 + 删除 |
clear() |
清空所有元素 | O(n) | 遍历数组,每个桶置 null |
// clear() 方法实现
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null; // 每个桶置 null,让 GC 回收
}
}
面试高频追问
-
删除节点后,HashMap 的容量会减小吗?
- 不会!
remove()只删除元素,不会触发缩容 - HashMap 没有缩容机制,容量只会增长
- 不会!
-
为什么红黑树删除比链表复杂?
- 链表只需修改指针,O(1)
- 红黑树删除可能破坏平衡,需要旋转和变色修复,O(log n)
-
remove 和 get 的查找逻辑一样吗?
- 是的!都是先比 hash,再比 key(
==或equals()) - 这也是为什么重写
equals()必须重写hashCode()的原因
- 是的!都是先比 hash,再比 key(
常见面试变体
- "HashMap 删除元素的时间复杂度是多少?"
- "HashMap 为什么没有缩容机制?"
- "删除红黑树节点后为什么要检查退树化?"
记忆口诀
删除流程:定位桶、遍历找、改指针(链表)/ 旋转变色(红黑树)、检查退树化。
退树化:节点少于 7 就退树,阈值差 2 防抖动。
总结
HashMap 的 remove() 方法通过 hash 定位桶后,根据节点类型执行不同删除逻辑:链表删除只需修改指针(O(1)),红黑树删除需要旋转和变色修复平衡(O(log n))。删除后如果红黑树节点数 ≤ 6,会退化为链表。注意:HashMap 只有扩容没有缩容,删除元素不会减小容量。