Redis 分布式锁如何实现?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观

面试考察点
-
基础掌握度:面试官不仅仅是想知道你会不会用
SETNX,更是想知道你是否理解分布式锁的核心诉求(互斥性、防死锁、可重入、高可用),以及 Redis 实现分布式锁从初级到高级的演进过程。 -
工程实践能力:考察你是否踩过生产环境中分布式锁的坑,比如锁超时释放导致的并发问题、
unlock误删别人的锁、Redis 主从切换导致锁丢失等经典场景。 -
原理理解深度:是否了解 Redisson 的看门狗机制、RedLock 算法的争议,以及分布式锁的局限性(不是银弹,某些场景需要 ZooKeeper)。
核心答案
Redis 分布式锁的实现经历了 三个阶段 的演进:
| 阶段 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 初级 | SETNX + EXPIRE |
简单易理解 | 非原子操作,可能死锁 |
| 中级 | SET key value NX EX + Lua 脚本释放 |
原子加锁,安全释放 | 不可重入,锁续期问题 |
| 高级 | Redisson 框架(推荐) | 可重入、自动续期、成熟稳定 | 单节点仍有极小概率丢失 |
一句话结论:生产环境直接用 Redisson,别自己手写。理解背后的原理(原子操作、防误删、看门狗续期),面试才能答出深度。
深度解析
一、为什么需要分布式锁?
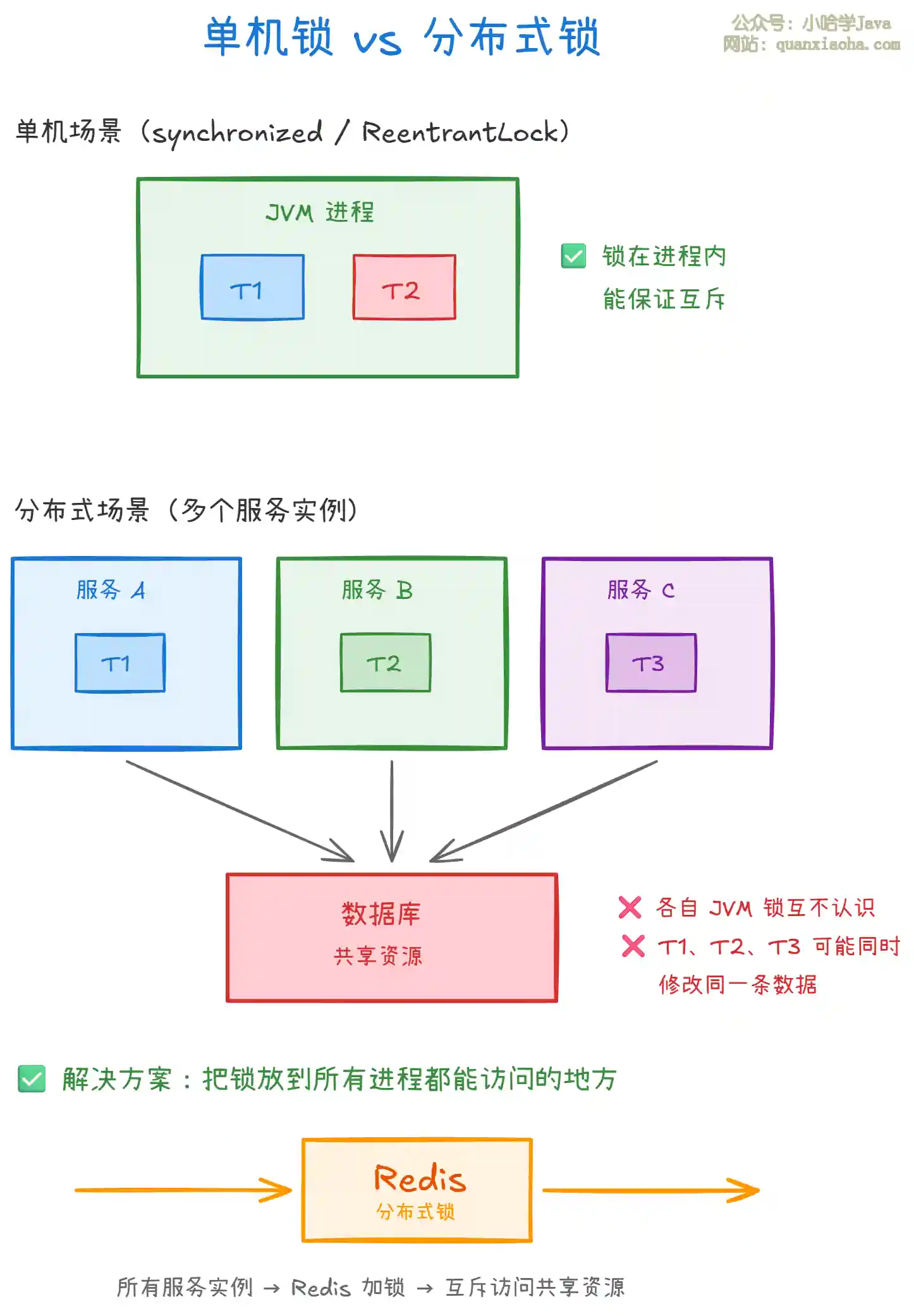
上图解释了分布式锁的必要性。核心要点:
- 单机锁的局限:
synchronized和ReentrantLock只能在同一个 JVM 进程内生效,跨进程就失效了。 - 分布式锁的本质:把锁的状态放到一个 所有进程共享的存储 中(通常是 Redis),各进程通过访问共享存储来竞争锁。
分布式锁必须满足的 5 个条件:
- 互斥性:任意时刻,只有一个客户端能持有锁。
- 防死锁:锁必须有超时机制,即使持有锁的客户端宕机,锁也能自动释放。
- 加锁和解锁必须是同一个客户端:不能释放别人的锁。
- 高可用:锁服务本身不能是单点故障。
- 高性能:加锁/解锁的开销要尽可能小。
二、初级实现:SETNX + EXPIRE(有缺陷)
// ❌ 错误示范:非原子操作
jedis.setnx("lock", "1"); // 加锁成功返回 1
jedis.expire("lock", 10); // 设置过期时间 10 秒
// 问题:如果 setnx 成功后,expire 还没执行就宕机了
// → 锁永远不会过期 → 死锁!
这个方案的问题在于 SETNX 和 EXPIRE 是 两条命令,不具备原子性。如果在两条命令之间发生宕机或网络断开,锁就永远不会过期,导致死锁。
三、中级实现:SET 原子命令 + Lua 释放
Redis 2.6.12 之后,SET 命令支持了 NX 和 EX 参数,可以 一条命令完成原子加锁:
// ✅ 原子加锁:SET key value NX EX seconds
// NX:Not eXists,key 不存在才设置成功(互斥)
// EX:设置过期时间(防死锁)
// value 使用唯一标识(UUID),防止误删别人的锁
String lockValue = UUID.randomUUID().toString();
jedis.set("lock", lockValue, SetParams.setParams().nx().ex(10));
释放锁时,必须 先判断是不是自己的锁,再删除,这两步也需要保证原子性:
// ❌ 非原子释放(有问题)
String value = jedis.get("lock");
if (lockValue.equals(value)) {
// 这里存在时间窗口:判断成功后、删除前,锁可能刚好过期
// 别的线程已经加锁成功了,你却把别人的锁删了!
jedis.del("lock");
}
// ✅ 用 Lua 脚本保证原子释放
String luaScript =
"if redis.call('get', KEYS[1]) == ARGV[1] then " +
" return redis.call('del', KEYS[1]) " +
"else " +
" return 0 " +
"end";
jedis.eval(luaScript, Collections.singletonList("lock"),
Collections.singletonList(lockValue));
为什么用 Lua 脚本? Redis 执行 Lua 脚本时会 单线程原子执行,中间不会被其他命令打断,完美解决了 "判断 + 删除" 的原子性问题。
但中级方案仍然有 两个问题:
- 不可重入:同一线程多次获取同一把锁会阻塞,不能像
ReentrantLock那样重入。 - 锁续期问题:如果业务执行时间超过了锁的过期时间,锁会自动释放,其他线程就能获取到锁,导致并发问题。
四、高级实现:Redisson(生产推荐)
Redisson 是一个 分布式锁框架,解决了中级方案的所有痛点。
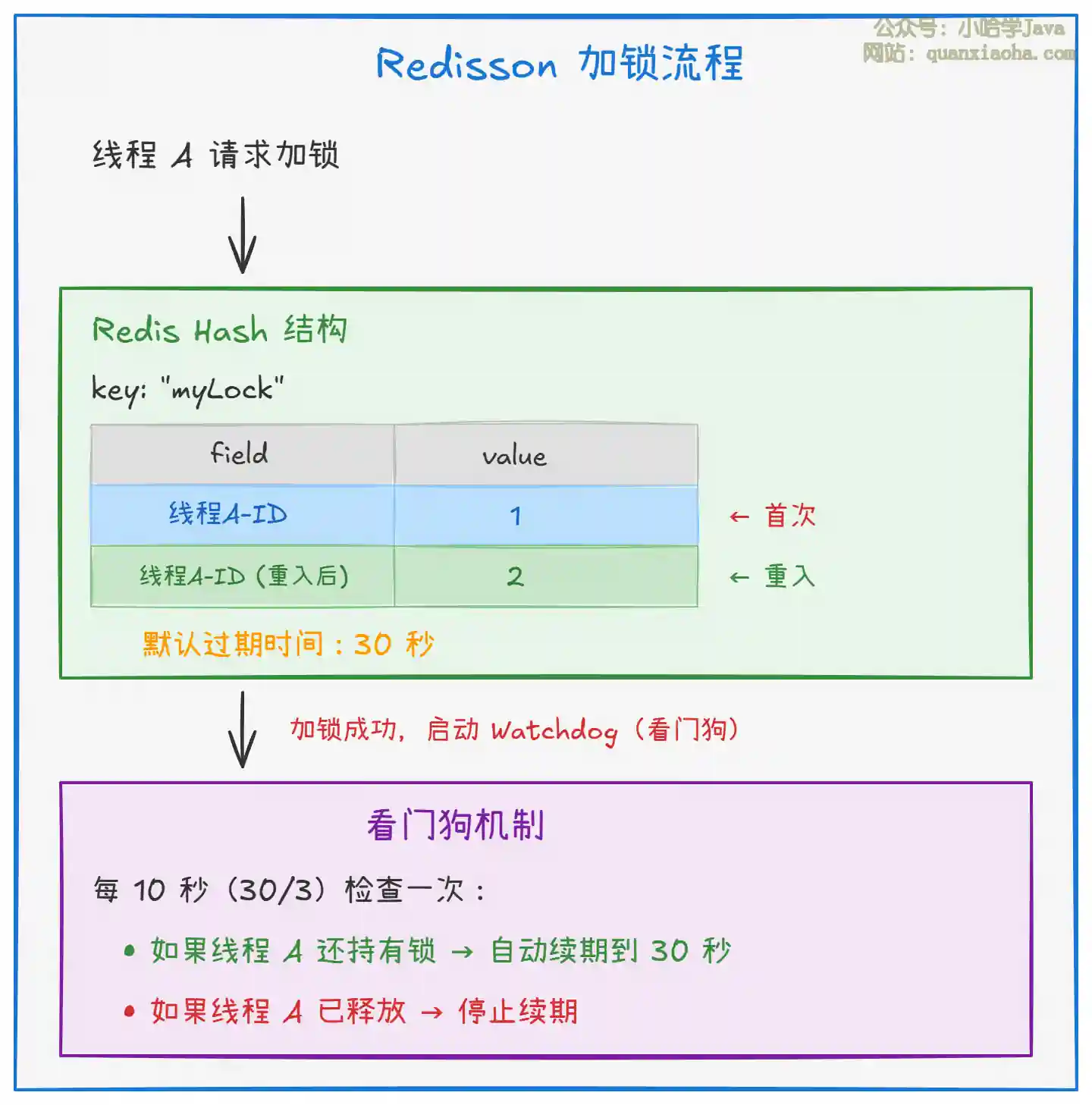
上图展示了 Redisson 的核心设计,要点如下:
- 可重入:使用 Redis 的 Hash 结构 存储,
field是线程唯一标识,value是重入次数。同一线程再次加锁时,value + 1;释放一次,value - 1;value减到 0 才真正删除 key。 - 看门狗自动续期:默认锁过期时间 30 秒,看门狗每隔 10 秒(过期时间的 1/3)检查一次,如果锁还被持有就续期到 30 秒,彻底解决了业务执行时间不确定导致的锁提前释放问题。
Redisson 使用代码示例:
// 1. 引入依赖
// implementation 'org.redisson:redisson-spring-boot-starter:3.27.0'
// 2. 使用分布式锁
@RestController
public class OrderController {
@Autowired
private RedissonClient redissonClient;
@GetMapping("/order")
public String createOrder() {
RLock lock = redissonClient.getLock("order:lock");
try {
// 尝试加锁:最多等待 3 秒,锁自动释放时间 30 秒
boolean acquired = lock.tryLock(3, 30, TimeUnit.SECONDS);
if (!acquired) {
return "获取锁失败,请稍后重试";
}
// 执行业务逻辑...
doBusiness();
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
// 只有持有锁的线程才能释放
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
return "下单成功";
}
}
五、RedLock 算法(多节点方案)
单节点 Redis 存在 主从切换导致锁丢失 的风险:
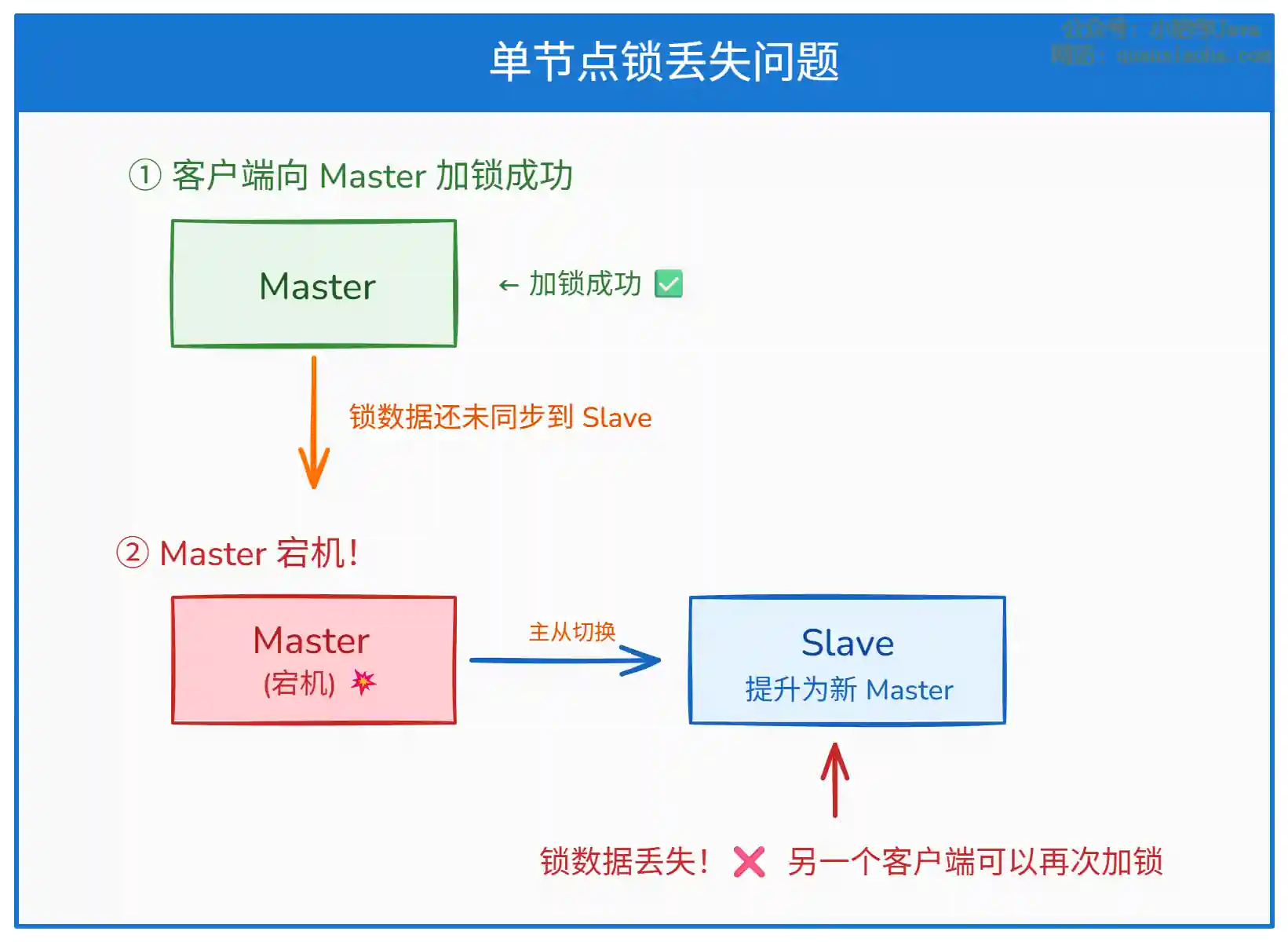
上图展示了主从切换导致锁丢失的场景:
- 客户端在 Master 上加锁成功,但锁数据还没来得及同步到 Slave。
- 此时 Master 宕机,Slave 被提升为新的 Master。
- 新 Master 上没有锁数据,其他客户端可以再次加锁成功 —— 两把锁同时存在,互斥性被打破。
RedLock 的解决方案:使用 N 个独立的 Redis 实例(通常 5 个),加锁时向所有实例发送加锁请求,只有成功在 大多数(N/2 + 1) 实例上加锁,才算成功。
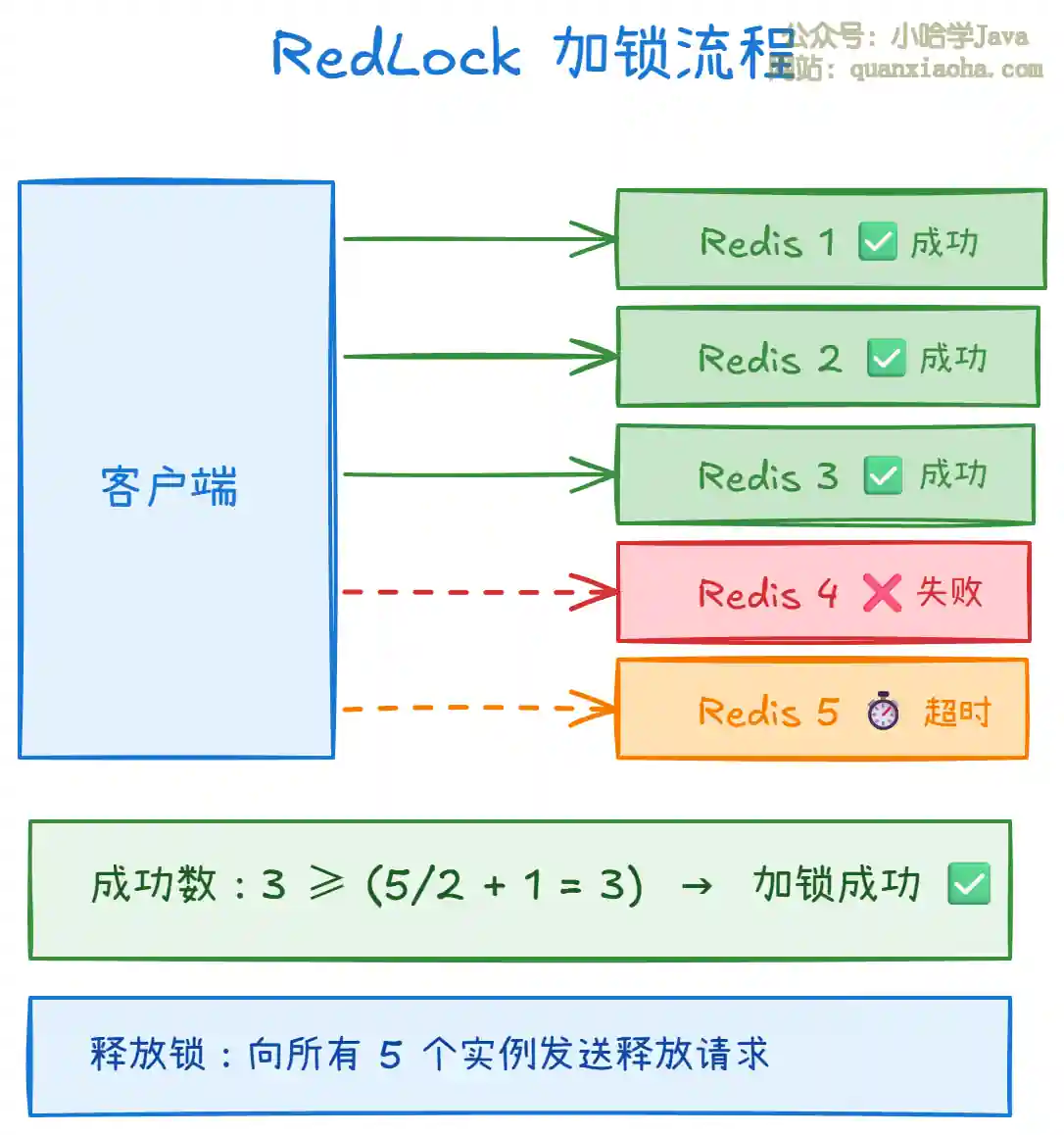
需要注意的是,RedLock 算法在业界 有争议(Martin Kleppmann 曾发文质疑),实际生产中使用 Redisson 单节点或哨兵模式已经能满足大部分场景。如果对锁的可靠性要求极高,建议考虑 ZooKeeper 或 etcd 等基于共识协议的方案。
面试高频追问
-
追问一:Redisson 的看门狗在什么情况下会失效?
如果使用
lock.lock(10, TimeUnit.SECONDS)手动指定了leaseTime,看门狗 不会启动。只有使用无参的lock.lock()或lock.tryLock()不指定leaseTime时,看门狗才会自动续期。此外,如果持有锁的进程被 强行 kill -9(非优雅关闭),看门狗线程也会随之销毁,锁会在剩余过期时间后自动释放。 -
追问二:Redis 分布式锁和 ZooKeeper 分布式锁的区别?
维度 Redis ZooKeeper 性能 高(内存操作,微秒级) 较低(集群间通信,毫秒级) 可靠性 主从切换可能丢锁 强一致(ZAB 协议),不会丢锁 实现方式 SETNX 过期机制 临时顺序节点 + Watch 适用场景 追求高性能、允许极端情况丢锁 追求高可靠、不容忍丢锁 -
追问三:业务代码执行完了但锁还没过期,怎么办?
这是正常的,不影响功能。业务执行完毕后主动调用
unlock()释放锁即可,不需要等到过期。Redisson 的 Lua 脚本会安全地判断锁的归属后再释放。
常见面试变体
- 变体一:"Redis 分布式锁过期了但业务还没执行完怎么办?"
- 变体二:"如何保证 Redis 分布式锁的加锁和解锁是原子操作?"
- 变体三:"Redisson 的看门狗机制了解吗?原理是什么?"
- 变体四:"RedLock 算法了解吗?解决了什么问题?"
记忆口诀
分布式锁演进三步走:
- 初级:
SETNX+EXPIRE→ 非原子,会死锁。 - 中级:
SET NX EX+ Lua 释放 → 原子了,但不能重入、不会续期。 - 高级:Redisson → Hash 可重入 + 看门狗续期,生产首选。
看门狗核心:默认 30 秒过期,每 10 秒续期一次(1/3),手设 leaseTime 则不续。
总结
Redis 分布式锁的实现经历了从 SETNX 到 SET NX EX + Lua 脚本,再到 Redisson 框架 的演进。生产环境推荐直接使用 Redisson,它通过 Hash 结构支持 可重入,通过看门狗机制实现 自动续期,通过 Lua 脚本保证 原子操作。如果对可靠性要求极高,可以考虑 RedLock 多节点方案或 ZooKeeper。