谈谈 Redis 5.0 中的 Stream 消息队列?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道 Stream 有哪些命令,更是想知道你是否理解 Stream 的内部数据结构(Radix Tree + listpack),以及它解决了 Redis 之前做消息队列时的哪些痛点。
-
机制理解深度:考察你是否清楚消费者组(Consumer Group)的完整工作机制,包括消息分发策略、ACK 确认、Pending 列表、消息重投递等核心概念。
-
方案选型能力:能否在 Stream、List、Pub/Sub、Kafka 之间做出合理对比和选型,知道 Stream 的能力边界在哪里。
核心答案
Redis Stream 是 Redis 5.0 引入的 内置消息队列,它借鉴了 Kafka 的设计思想,提供了完整的消息队列能力:
| 核心能力 | 说明 |
|---|---|
| 消息持久化 | 消息写入磁盘(AOF / RDB),Redis 重启不丢失 |
| 消费者组 | 同组消费者负载均衡,一条消息只被组内一个消费者处理 |
| 消息确认(ACK) | 消费者处理完发送 XACK,未确认的消息可被重新投递 |
| 历史回溯 | 通过消息 ID 可读取任意位置的历史消息 |
| 阻塞读取 | XREAD / XREADGROUP 支持阻塞等待新消息 |
一句话结论:Stream 是 Redis 官方提供的 轻量级可靠消息队列,适合中小规模场景。如果消息量达到千万级以上或需要严格的顺序保证,仍然建议使用 RocketMQ、Kafka 等消息中间件。
深度解析
一、为什么 Redis 需要 Stream?
在 Stream 出现之前,Redis 做消息队列有三种方案,但都有明显缺陷:
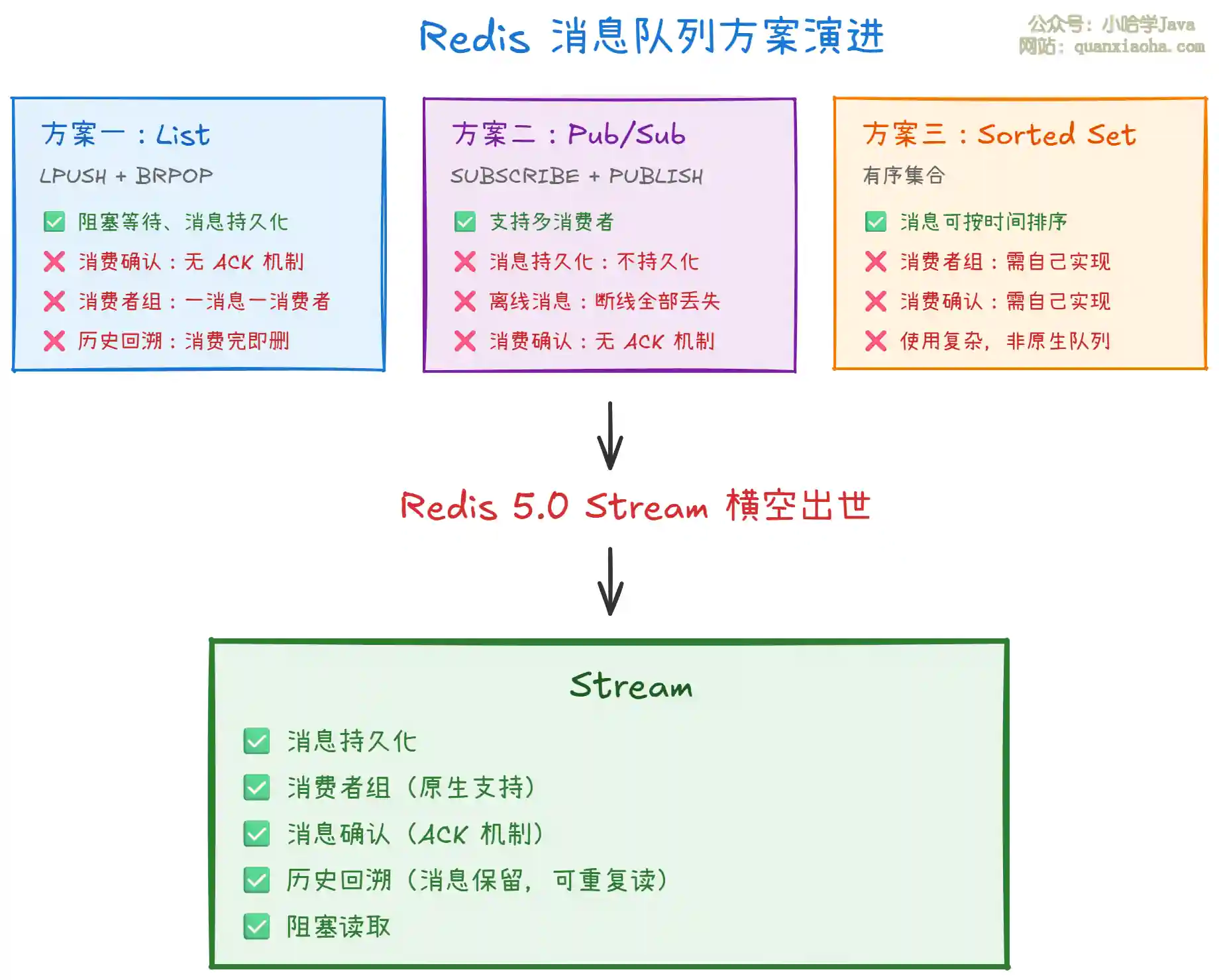
上图展示了 Redis 消息队列方案的演进历程。可以看到,List、Pub/Sub、Sorted Set 各有各的缺陷,Stream 则是 集大成者,一次性解决了所有痛点。
二、Stream 的内部数据结构
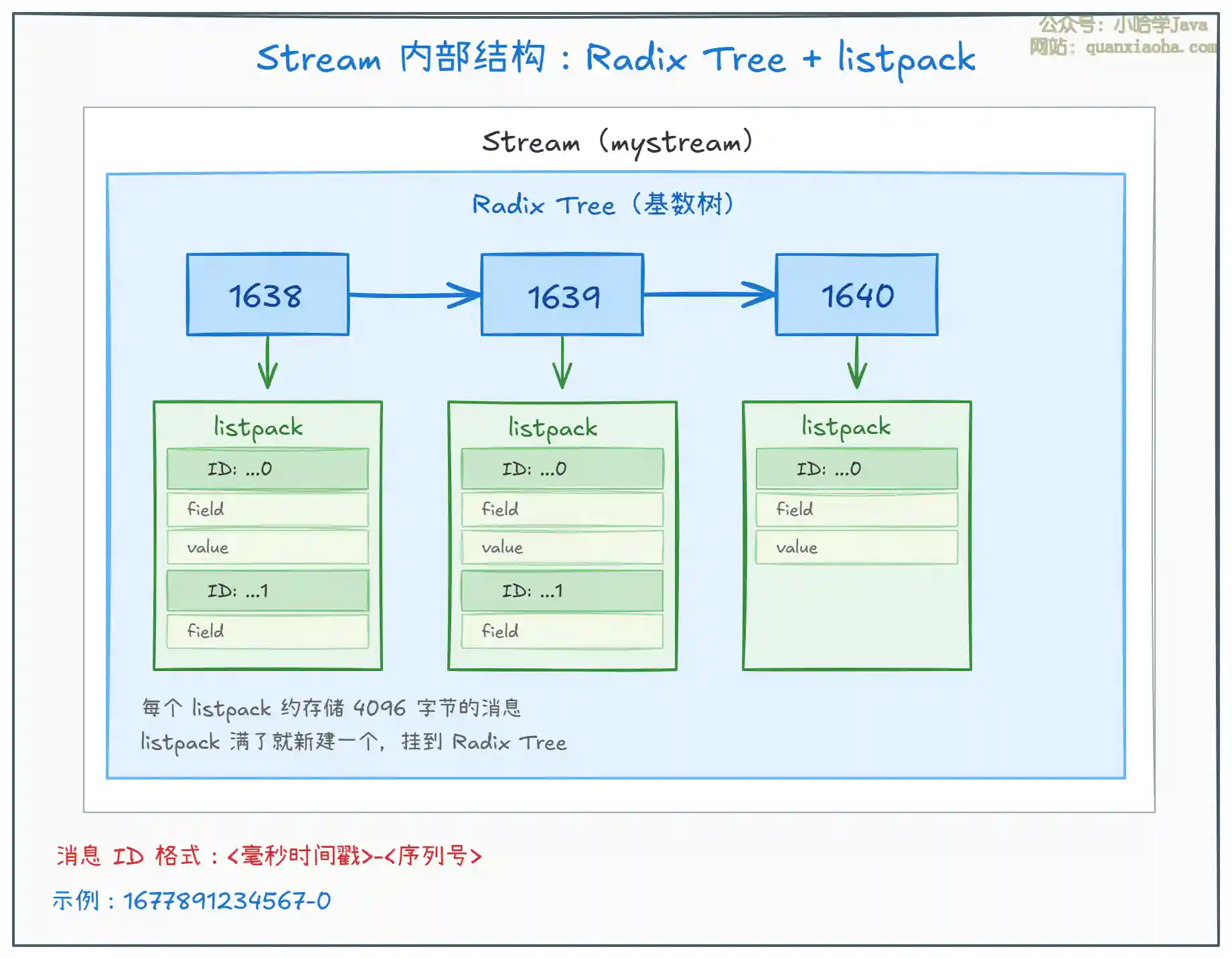
上图展示了 Stream 的内部存储结构:
- Radix Tree(基数树):一种压缩前缀树,用于高效按 ID 范围查找消息。key 是消息 ID 的前缀,value 指向一个 listpack。
- listpack:一种紧凑的内存编码格式(类似 ziplist 的升级版),每个 listpack 约存储 4096 字节的消息。当一个 listpack 写满了,就创建一个新的,挂到 Radix Tree 的新节点上。
- 消息 ID:格式为
<毫秒时间戳>-<序列号>,同一毫秒内多条消息通过序列号区分,保证严格递增。
这种设计的优势:
- 内存高效:listpack 是连续内存,没有指针开销,非常紧凑。
- 范围查询快:Radix Tree 天然支持按 ID 范围快速定位。
- 追加写入快:新消息只需追加到最新的 listpack,非常高效。
三、消费者组完整工作机制
消费者组是 Stream 的核心能力,它允许多个消费者 协作消费 同一个 Stream。

上图展示了消费者组的完整工作流程,核心概念:
last_delivered_id:消费者组记录了一个游标,表示已经投递到哪条消息了。新消费者加入组后,从这个游标之后开始读取,不会读到旧消息。- 消息分发:同组内的消费者,每条消息只会分配给其中一个(轮询或指定),实现负载均衡。
- Pending 列表:每个消费者组维护一个 Pending 列表,记录已投递但尚未 ACK 的消息。如果消费者宕机,这些消息可以被其他消费者接管(
XCLAIM)。 - ACK 确认:消费者处理完消息后调用
XACK,消息从 Pending 列表中移除,表示 "已处理"。
四、Stream 核心命令一览
# ========== 生产者 ==========
# 发送消息(* 表示自动生成 ID)
XADD mystream * user "张三" action "下单" amount "99.9"
# 返回:1677891234567-0(自动生成的消息 ID)
# 查看流信息
XINFO STREAM mystream
# 查看流长度
XLEN mystream
# ========== 消费者组管理 ==========
# 创建消费者组
# 0:从第一条消息开始消费
# $:从最新消息开始消费(只接收新消息)
XGROUP CREATE mystream mygroup 0
# 删除消费者组
XGROUP DESTROY mystream mygroup
# ========== 消费者读取 ==========
# 从消费者组读取消息(> 表示只读未投递的新消息)
XREADGROUP GROUP mygroup consumer1 COUNT 1 BLOCK 5000 STREAMS mystream >
# ========== 消息确认 ==========
# 确认消息已处理
XACK mystream mygroup 1677891234567-0
# ========== Pending 管理 ==========
# 查看 Pending 列表(未 ACK 的消息)
XPENDING mystream mygroup
# 转移消息给其他消费者(处理宕机接管)
XCLAIM mystream mygroup consumer2 3600000 1677891234567-0
# ========== 历史回溯 ==========
# 按范围读取消息(不消费,纯查看)
XRANGE mystream - + COUNT 10
# - 表示最早,+ 表示最新
五、Stream vs Kafka:能替代吗?
| 对比维度 | Redis Stream | Kafka |
|---|---|---|
| 消息存储 | 内存为主(受限于内存大小) | 磁盘为主(TB 级存储) |
| 消息积压 | 受内存限制,积压有限 | 可积压海量消息 |
| 分区 | 不支持多分区 | 支持多 Partition,水平扩展 |
| 消费者组 | ✅ 支持 | ✅ 支持 |
| 消息确认 | ✅ ACK + Pending | ✅ Offset 提交 |
| 消息顺序 | 单 Stream 内有序 | 单 Partition 内有序 |
| 吞吐量 | 10 万+ QPS | 百万+ QPS |
| 运维复杂度 | 低(Redis 自带) | 高(独立集群 + ZooKeeper) |
| 适用规模 | 百万级 / 天 | 亿级 / 天 |
结论:Stream 不能完全替代 Kafka,但在很多中小场景下够用了:
- 用 Stream:微服务内部事件通知、轻量级任务队列、实时数据管道(日志、监控)、消息量百万级以内。
- 用 Kafka:大数据流处理、日志采集平台、核心交易消息、消息量千万级以上、需要多 Partition 水平扩展。
面试高频追问
-
追问一:Stream 消息会占满内存吗?怎么清理?
可以通过
XADD的MAXLEN参数限制 Stream 的最大长度:# 最多保留 10000 条消息,超过自动淘汰最旧的 XADD mystream MAXLEN 10000 * field value # 更高效的方式(近似裁剪,性能更好) XADD mystream MAXLEN ~ 10000 * field value~表示近似裁剪,Redis 不一定精确保留 10000 条,可能多留几十条,但性能更好,不会阻塞。 -
追问二:消费者宕机后消息怎么处理?
宕机消费者的未 ACK 消息会留在 Pending 列表中。其他消费者可以通过
XPENDING查看哪些消息超时未确认,再用XCLAIM将这些消息转移给自己重新处理。也可以用XAUTOCLAIM命令自动转移超时消息。 -
追问三:Stream 的消息 ID 能自定义吗?
可以。
XADD的*表示自动生成,你也可以手动指定 ID,但必须满足 严格递增 的要求(新 ID 必须大于 Stream 中所有已有 ID)。实际生产中基本都用*自动生成。
常见面试变体
- 变体一:"Redis Stream 和 List 做消息队列的区别?"
- 变体二:"Redis Stream 的消费者组是怎么实现的?"
- 变体三:"Redis 能替代 Kafka 吗?"
- 变体四:"Redis 做消息队列有哪些方案?各有什么优缺点?"
记忆口诀
Stream 五大能力:持久化、消费者组、ACK 确认、历史回溯、阻塞读取。
内部结构:Radix Tree + listpack,追加写快、范围查快、内存省。
选型:百万级用 Stream,千万级上 Kafka。
总结
Redis Stream 是 Redis 5.0 引入的内置消息队列,内部使用 Radix Tree + listpack 存储,支持消费者组、ACK 确认、历史回溯、阻塞读取等完整消息队列能力。它填补了 Redis 在可靠消息传递方面的空白,适合中小规模的轻量级消息场景。如果消息量达到千万级以上或需要多分区水平扩展,仍然建议使用 Kafka。