Redis 单线程,为什么还这么快?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
原理理解深度:面试官不仅仅是想听你列举几个原因,更是想知道你是否真正理解 Redis 的性能来源 —— 是内存速度、IO 多路复用、还是高效数据结构?哪个才是核心因素?
-
系统级知识广度:这道题会涉及到操作系统(
epoll、文件描述符、内核态/用户态)、网络编程(Reactor 模式)、数据结构(SDS、跳表、压缩列表)等多方面知识,体现你的技术功底。 -
对比分析能力:能否从 "为什么不用多线程" 的反面角度来论证单线程设计的合理性,体现你的架构思维。
核心答案
Redis 单线程还能达到 10 万+ QPS,核心原因可以归纳为 4 个方面:
| 快的原因 | 一句话解释 | 重要程度 |
|---|---|---|
| 基于内存操作 | 数据在内存中,纳秒级访问,不碰磁盘 | ⭐⭐⭐⭐⭐ |
| IO 多路复用 | 一个线程管理海量连接,不阻塞 | ⭐⭐⭐⭐⭐ |
| 高效的数据结构 | SDS、ziplist、skiplist 等专为性能设计 |
⭐⭐⭐⭐ |
| 单线程避免开销 | 无锁竞争、无上下文切换、无并发 bug | ⭐⭐⭐⭐ |
一句话结论:Redis 快的本质是 内存 + IO 多路复用,单线程反而是加分项(避免了锁和切换开销),而不是拖后腿。
深度解析
一、基于内存操作(最核心的原因)
这是 Redis 快的 最根本原因,没有之一。
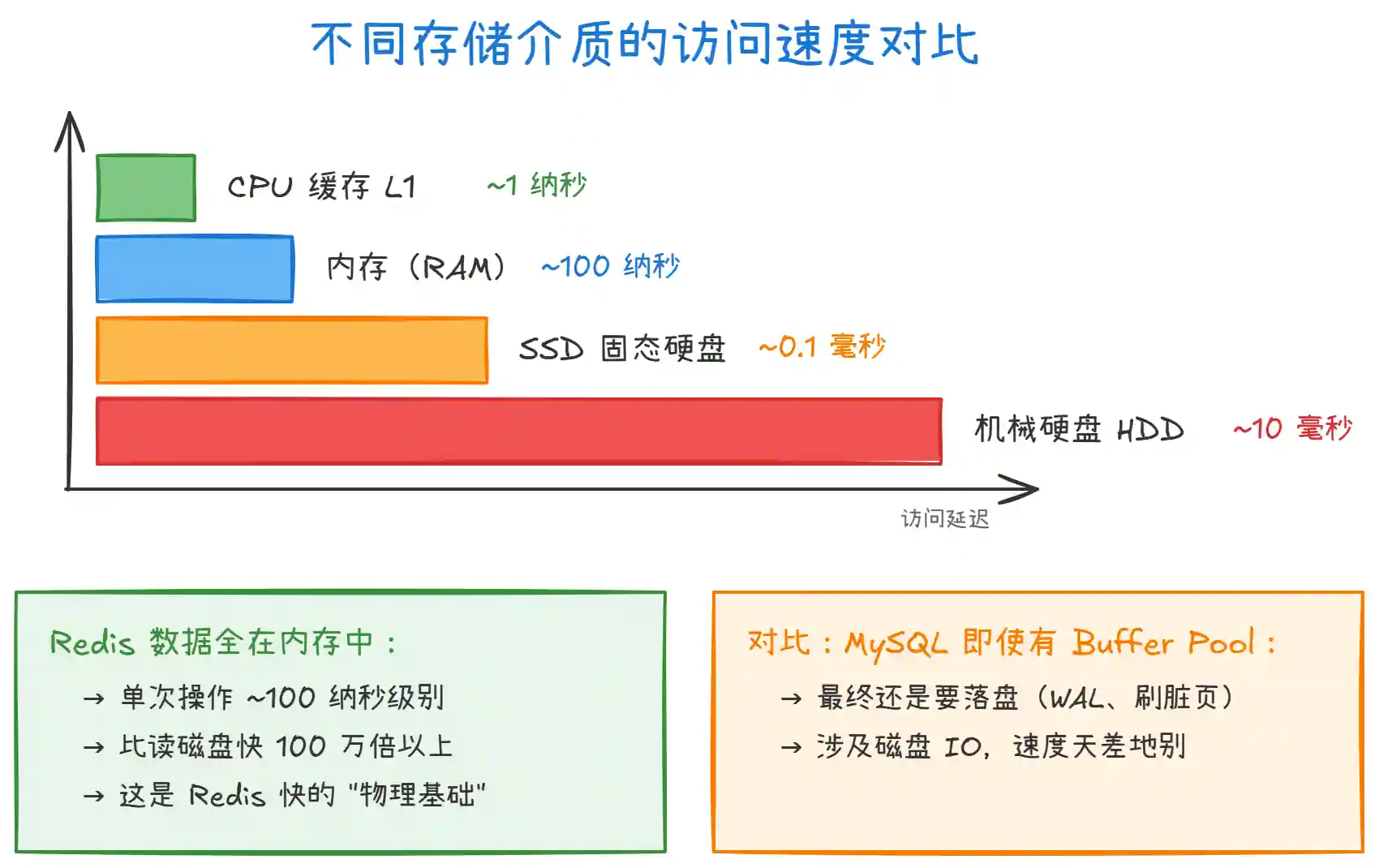
上图对比了不同存储介质的访问速度。关键点:
-
内存 vs 磁盘的量级差距:内存访问约 100 纳秒,SSD 约 0.1 毫秒,差了 1000 倍;机械硬盘约 10 毫秒,差了 10 万倍。Redis 的数据全部存在内存中,每次读写就是一次内存操作,这是它快的物理基础。
-
传统数据库的瓶颈:MySQL 即使有 Buffer Pool 把热数据缓存到内存,但写入时要写 WAL 日志(
fsync刷盘)、定期刷脏页回磁盘,这些磁盘 IO 是绕不开的。Redis 则完全不需要碰磁盘(除非开启持久化),纯内存操作。 -
Redis 的持久化是异步的:即使开启了
RDB或AOF,持久化操作也是由后台线程/子进程完成的,不会阻塞主线程的命令执行。
二、IO 多路复用(高性能的网络模型)
光有内存快还不够,如果每个客户端连接都阻塞等待,性能也上不去。Redis 使用 IO 多路复用 技术,让一个线程就能高效管理数万个客户端连接。
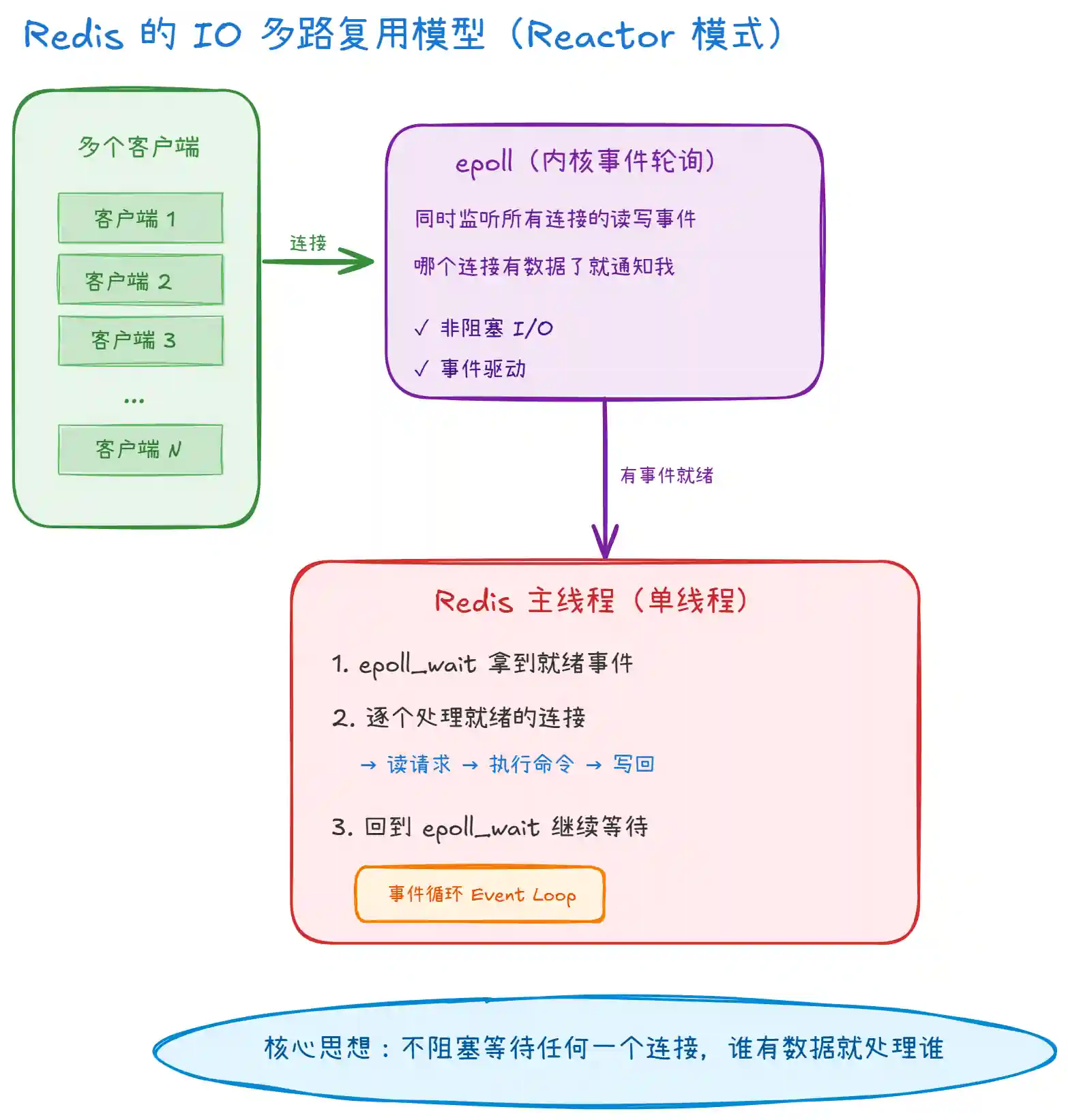
上图展示了 Redis 的 IO 多路复用模型,核心是 epoll + 事件循环(Event Loop):
-
epoll的作用:Redis 将所有客户端连接的文件描述符(FD)注册到epoll内核事件表中。epoll会同时监听这些连接,当某个连接有数据可读或可写时,epoll会通知 Redis 主线程。这样 Redis 就不需要挨个去问每个连接 "你有没有数据",而是 被动接收通知。 -
事件循环(Event Loop):Redis 主线程在一个循环中不断调用
epoll_wait。有事件就处理(读请求、执行命令、写响应),没事件就阻塞等待(不消耗 CPU)。整个过程中,单线程高效地轮流服务所有客户端,没有任何阻塞。 -
为什么不用多线程:因为
epoll已经解决了 "同时管理海量连接" 的问题。一个线程通过epoll就能同时处理几万个连接的 IO 事件,再用多线程反而增加了复杂度。
不同操作系统使用不同的多路复用实现:Linux 用
epoll、macOS 用kqueue、Windows 用WSAPoll。Redis 源码中做了封装,编译时自动选择最优实现。
三、高效的数据结构
Redis 没有直接用 C 语言原生的字符串和数组,而是自己实现了一套专为性能优化的数据结构。
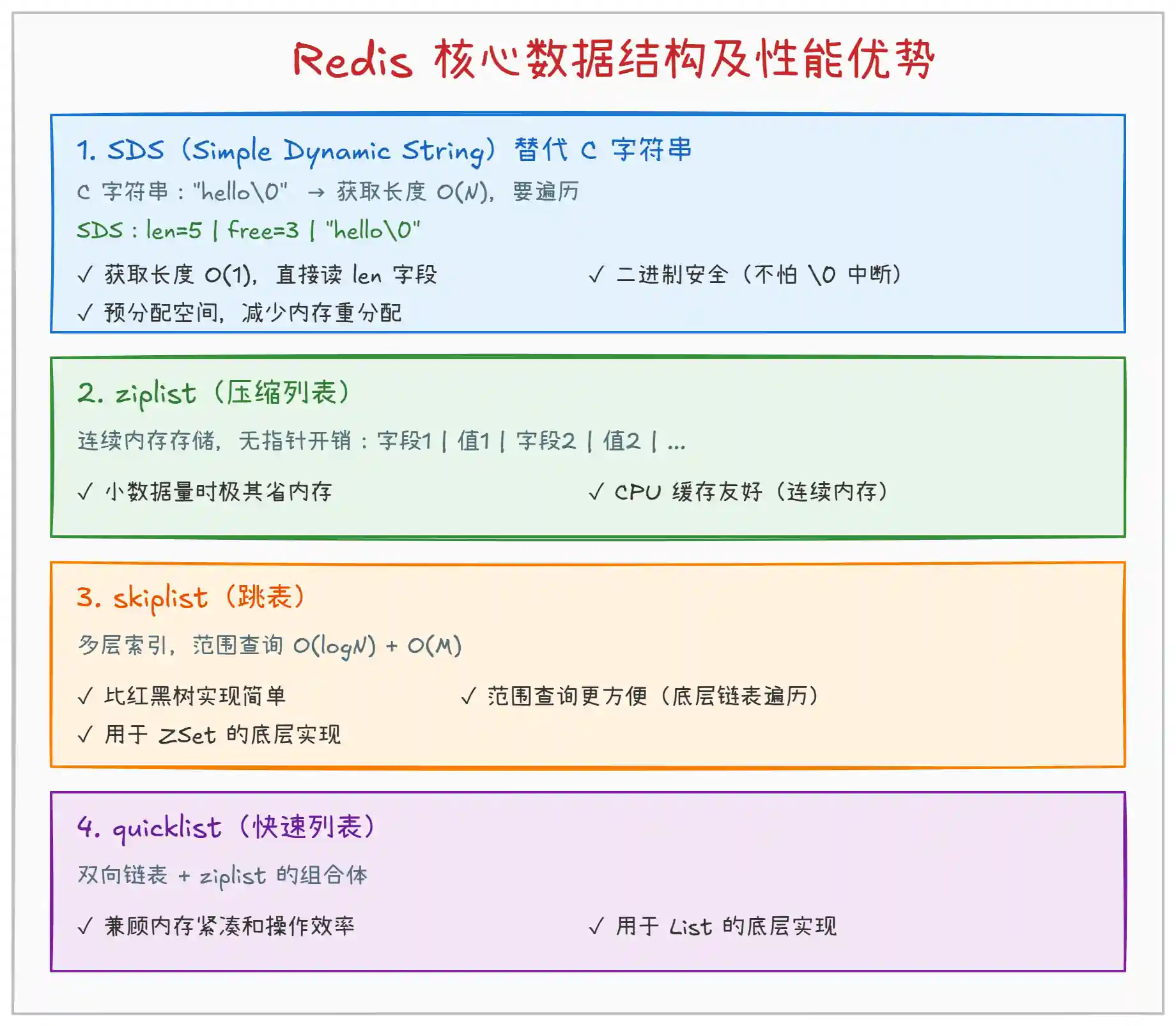
上图展示了 Redis 的核心数据结构及其性能优势:
-
SDS(简单动态字符串):C 语言原生的字符串用
\0标识结尾,获取长度需要遍历(O(N)),而且遇到\0就会被截断。Redis 自己实现的SDS增加了len和free字段,获取长度 O(1),且二进制安全。同时SDS采用预分配和惰性释放策略,减少频繁的内存重分配。 -
ziplist(压缩列表):用一块连续内存存储多个字段和值,没有任何指针开销。小数据量时极其节省内存,而且连续内存对 CPU 缓存非常友好。缺点是元素多了以后插入删除需要大量内存搬移,所以只在数据量小时使用。
-
skiplist(跳表):用于
ZSet的底层实现,查找和范围查询都是 O(logN)。相比红黑树,跳表实现更简单、范围查询更方便(底层就是链表遍历)、内存占用也可控。 -
quicklist(快速列表):
List的底层实现,是双向链表和ziplist的组合体。每个链表节点是一个ziplist,兼顾了内存紧凑和操作效率。
四、单线程本身就是优势

上图的要点:
-
无锁竞争:多线程操作共享数据结构(如全局哈希表)必须加锁,锁意味着等待和阻塞。在 Redis 这种每秒处理 10 万+ 命令的场景下,锁竞争会严重拖慢性能。单线程天然无需加锁。
-
无上下文切换:线程切换需要保存和恢复 CPU 寄存器、栈帧等上下文信息,每次切换消耗约 1~5 微秒。Redis 的单次命令执行也才几微秒,频繁切换反而得不偿失。
-
无并发 bug:多线程代码最头疼的就是死锁、竞态条件、内存可见性等问题,调试和排查成本极高。单线程代码简单可靠,不容易出问题。
-
Redis 的瓶颈不在 CPU:绝大多数 Redis 命令执行都在微秒级,一个 CPU 核心就能跑满 10 万+ QPS。多出来的 CPU 核心留给后台线程(持久化、异步删除等)和操作系统使用就好。
五、其他优化手段
除了上面四大核心原因,Redis 还有很多细节优化:
-
单次命令执行时间有上限:Redis 的命令都是 O(1) 或 O(logN) 的简单操作(
GET、SET、ZADD等),不会出现一条命令跑几秒的情况。如果你用了KEYS *这种 O(N) 的命令导致阻塞,那是使用不当,不是 Redis 的问题。 -
高效的协议:Redis 使用
RESP(Redis Serialization Protocol)协议,解析简单高效,不像 HTTP 那样有复杂的头部解析开销。 -
管道(Pipeline):客户端可以将多个命令打包一次性发送,减少网络往返次数,大幅提升吞吐。
面试高频追问
-
追问一:Redis 单线程有没有什么劣势?
- 单线程无法利用多核 CPU(但可以通过部署多实例解决)。某些 O(N) 的命令(如
KEYS *、HGETALL大 Hash)会阻塞主线程,导致后续请求排队。解决方案是避免使用这些命令,或用SCAN替代。
- 单线程无法利用多核 CPU(但可以通过部署多实例解决)。某些 O(N) 的命令(如
-
追问二:
epoll和select有什么区别?为什么 Redis 用epoll?select每次调用都要把所有 FD 从用户态拷贝到内核态,且最大只能监听 1024 个连接。epoll只需一次注册,内核通过事件回调通知就绪的 FD,没有数量限制,性能从 O(N) 降到 O(1),适合高并发场景。
-
追问三:生产环境 Redis 的 QPS 一般能到多少?
- 单机 Redis 一般 8~10 万 QPS(简单命令)。如果开启了持久化、大 Value、复杂命令等,会打折扣。超高 QPS 可以通过集群横向扩展解决。
常见面试变体
- "Redis 为什么这么快?请从多个角度分析"
- "Redis 为什么选择单线程模型?"
- "Redis 的 IO 多路复用是什么原理?"
- "epoll 和 select 的区别是什么?"
记忆口诀
四大原因:内存快(基础)+ 多路复用(网络)+ 高效结构(数据)+ 单线程(无锁开销)。
本质理解:Redis 快不是因为单线程,而是因为 内存 + epoll。单线程只是锦上添花(避免锁和切换),不是快的主要原因。
总结
Redis 单线程还这么快,核心原因有四个:① 基于内存操作(物理基础)、② IO 多路复用(一个线程管理海量连接)、③ 高效的数据结构(SDS、ziplist、skiplist 等)、④ 单线程避免了锁竞争和上下文切换。其中内存是根本,epoll 多路复用是关键,高效数据结构是保障,单线程无锁是加分项。面试回答时要分层次展开,体现对底层原理的系统性理解。