Zookeeper 是 CP 的还是 AP 的?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
CAP 理论理解:面试官不仅仅是想知道 Zookeeper 属于 CP 还是 AP,更是想考察你是否真正理解 CAP 三要素的含义,以及为什么分布式系统不能同时满足三者。
-
Zookeeper 的一致性机制:考察你是否知道 Zookeeper 通过 ZAB 协议保证了强一致性,以及在 Leader 选举期间会发生什么。
-
实际取舍分析:考察你是否能结合实际场景分析 Zookeeper 牺牲可用性的具体表现,而不是只会背结论。
核心答案
Zookeeper 是 CP 系统。
它优先保证一致性和分区容错性,在发生网络分区或 Leader 选举期间,会牺牲可用性——集群在这段时间内无法处理写请求(甚至部分读请求也可能返回旧数据)。
用一张表快速对比常见中间件的 CAP 归属:
| 中间件 | CAP 归属 | 牺牲了什么 | 具体表现 |
|---|---|---|---|
| Zookeeper | CP | 可用性 A | Leader 选举期间集群不可用 |
| Eureka | AP | 强一致性 C | 节点间数据可能不一致,但始终可用 |
| Nacos | CP / AP 可切换 | 灵活选择 | 临时实例走 AP,永久实例走 CP |
| etcd | CP | 可用性 A | 和 Zookeeper 类似,Leader 选举期间不可写 |
| Consul | CP | 可用性 A | Raft 协议,Leader 选举期间不可写 |
深度解析
一、先搞清楚 CAP 到底在说什么
很多人背了无数遍 CAP,但一问细节就糊。先把基础夯实:
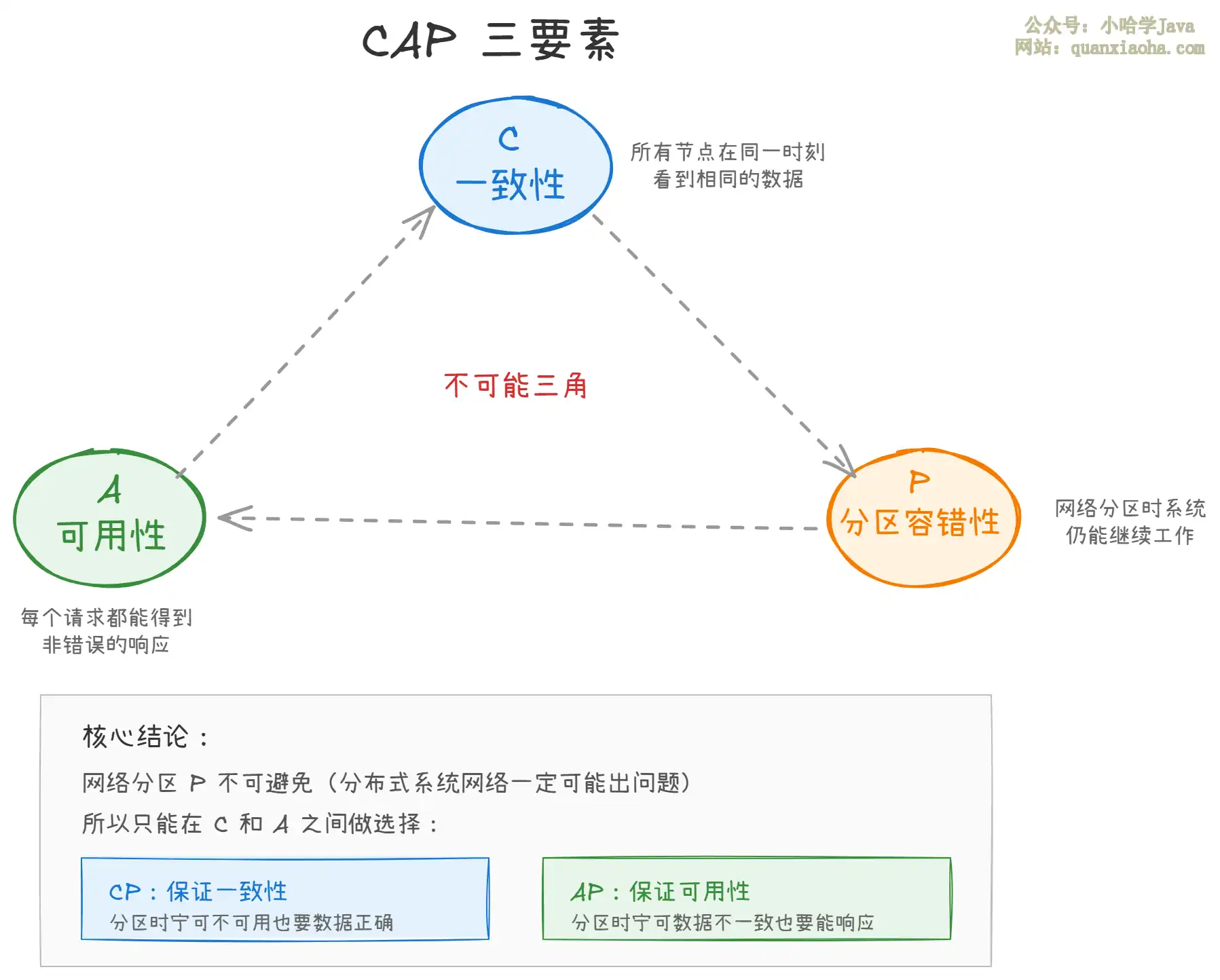
上图展示了 CAP 的核心关系。关键点:
- 在分布式系统中,网络分区(P)是客观存在的,不是你能选的
- 你能选的是:当分区发生时,你是要一致性(C)还是要可用性(A)
- CP 系统的立场:数据不一致宁可挂掉也不能返回错误数据
- AP 系统的立场:哪怕数据暂时不一致,也得给用户响应,不能让人干等着
二、Zookeeper 为什么是 CP?具体怎么体现?
分两个层面来理解:数据写入时的一致性保证 和 异常时的可用性牺牲。
层面一:正常情况下——ZAB 协议保证强一致性

上图展示了 ZAB 协议的核心流程。关键点:
- Leader 收到写请求后,不是自己写完就返回,而是向所有 Follower 发起 Proposal
- 必须等 超过半数 的 Follower 写入本地日志并返回 ACK,Leader 才会 Commit
- 这意味着:任意时刻,已提交的数据在多数节点上一定是一致的
层面二:Leader 选举期间——牺牲可用性
这是 Zookeeper 作为 CP 系统最典型的体现:

上图展示了 Leader 宕机后的完整流程。核心逻辑:
- Leader 挂了之后,整个集群进入选举模式
- 选举期间,所有写请求全部被阻塞,不响应
- 直到新 Leader 选出来,数据同步完毕,才能恢复服务
- 这就是典型的 "宁可不可用,也不能返回不一致的数据"
三、一个常见的争议:Zookeeper 的读请求到底算不算强一致?
这个点很多人搞不清楚,值得展开说一下。
严格来说,Zookeeper 默认情况下,读请求走的是本地节点,不经过 Leader。这意味着:如果你从一个刚恢复的 Follower 上读数据,有可能读到旧数据。

上图说明了 Zookeeper 读写一致性的差异。关键点:
- 写请求是强一致的:必须过半节点 Ack 才能 Commit
- 读请求默认走本地,可能读到旧数据。但可以通过
sync()操作强制同步后再读 - 这不影响 Zookeeper 的 CP 归属,因为 CAP 中的 C 关注的是写操作的线性一致性,而且 Zookeeper 在分区时确实选择了牺牲可用性
四、和 Eureka(AP)对比,感受更直观
Zookeeper 作为 CP 的代价,在对比 AP 系统时特别明显:
| 场景 | Zookeeper(CP) | Eureka(AP) |
|---|---|---|
| Leader 选举期间 | 整个集群不可写 | 不存在 Leader,任何节点可读写 |
| 网络分区时 | 不足半数的分区停止服务 | 所有节点继续独立服务 |
| 节点宕机时 | 触发 Leader 重新选举,短暂不可用 | 其他节点照常工作 |
| 数据一致性 | 写操作强一致 | 节点间数据可能延迟同步 |
| 作为注册中心的坑 | 选举期间服务发现不可用 | 哪怕数据旧一点,也能发现服务 |
这也是为什么 Spring Cloud 早期用 Zookeeper 做注册中心,后来都转向 Eureka 和 Nacos 了——注册中心的核心诉求是可用性,宁可偶尔发现到一个已经下线的服务(重试就行),也不能在 Leader 选举期间整个注册中心用不了。
面试高频追问
-
追问一:既然 Zookeeper 是 CP,那为什么还适合做分布式锁?
分布式锁恰恰需要强一致性——同一时刻只能有一个客户端拿到锁。Zookeeper 的 CP 特性保证了这一点,写操作的强一致确保了锁的互斥性。而且即使 Leader 切换,由于 ZAB 协议会保证数据不丢失,锁的状态也是安全的。
-
追问二:Nacos 为什么能同时支持 CP 和 AP?
Nacos 区分了临时实例和永久实例。临时实例(默认)使用 Distro 协议(AP 模式),客户端主动注册心跳,不需要 Leader;永久实例使用 Raft 协议(CP 模式),服务端主动探测。这种设计很聪明——不同场景用不同的一致性模型。
-
追问三:CAP 理论有什么局限性?
CAP 只考虑了网络分区这一种故障场景,实际上分布式系统还面临延迟、节点崩溃、数据损坏等问题。所以后来有了 BASE 理论作为补充——大多数场景不需要强一致,最终一致就够了。
常见面试变体
- "CAP 理论是什么?能不能三个都要?"
- "为什么注册中心更适合用 AP 系统?"
- "Zookeeper 和 Eureka 的 CAP 模型有什么区别?各适合什么场景?"
- "Nacos 是 CP 还是 AP?"
记忆口诀
Zookeeper 写强一致,选举期间不可用,典型 CP 没得跑。注册中心要可用,Eureka/Nacos 的 AP 更适合。
总结
Zookeeper 是 CP 系统——通过 ZAB 协议保证写操作的强一致性,在 Leader 选举或网络分区期间牺牲可用性。代价就是注册中心这类对可用性要求高的场景不太适合用 Zookeeper,这也是业界逐步迁移到 Nacos 等系统的原因。理解了这个取舍,面试官问到 CAP 和分布式一致性,你基本能一通百通。