什么是 Redis 集群脑裂问题,怎么解决?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
问题识别能力:面试官不仅仅是想知道 "脑裂" 这个名词,更是想知道你是否能从 网络分区 的角度理解脑裂的产生原因,以及脑裂为什么会带来 数据丢失 和 数据不一致 的严重后果。
-
原理理解深度:考察你是否了解哨兵模式和 Cluster 模式下脑裂的具体触发机制(主观下线 → 客观下线 → 故障转移),以及旧 Master 在被隔离期间仍然接受写入的危害。
-
方案落地能力:能否给出具体的配置参数(如
min-slaves-to-write、min-slaves-max-lag)和最佳实践,而不是只停留在 "避免脑裂" 的概念层面。
核心答案
脑裂(Split Brain) 是指 Redis 集群中,由于 网络分区 导致出现了 两个 Master 同时接受写入的情况。
| 维度 | 说明 |
|---|---|
| 产生原因 | 网络分区导致哨兵/Cluster 认为旧 Master 宕机,选举出新 Master,但旧 Master 实际还在运行 |
| 核心危害 | 客户端同时向新旧两个 Master 写入数据,导致数据冲突和丢失 |
| 发生场景 | 哨兵模式、Cluster 模式都可能发生 |
| 核心解法 | 配置 min-slaves-to-write + min-slaves-max-lag,让 Master 在从节点不足时 拒绝写入 |
一句话结论:脑裂的本质是网络分区导致 "一主变两主",解决思路是让旧 Master 在与从节点失联后 主动拒绝写入,从源头切断数据不一致的可能。
深度解析
一、脑裂是怎么发生的?
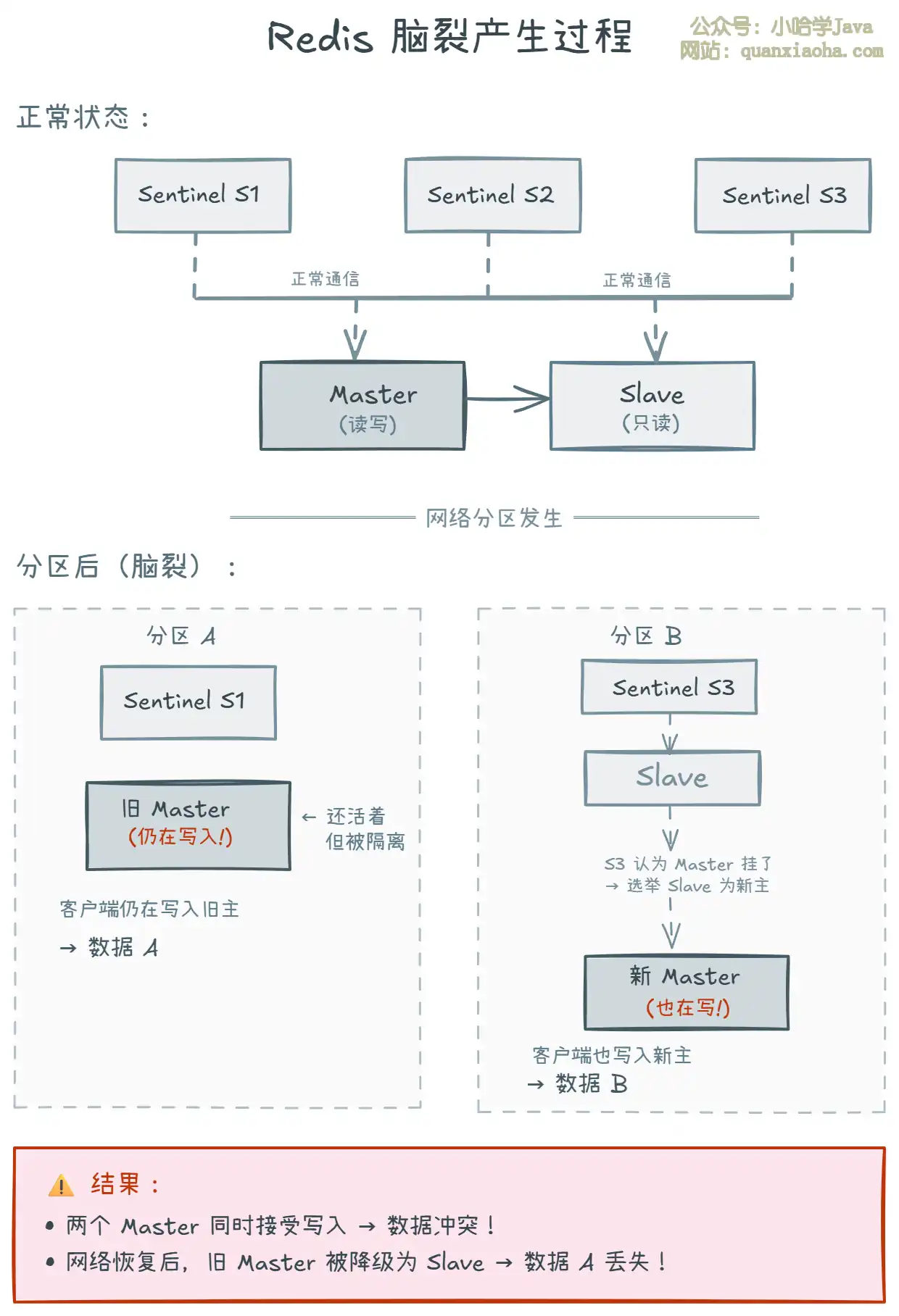
上图展示了脑裂的完整产生过程:
- 正常状态:Sentinel 集群正常监控 Master 和 Slave,一切运行正常。
- 网络分区发生:假设网络出现故障,将 Master 和 Sentinel S1 分在一个分区,Slave 和 Sentinel S3 分在另一个分区。两个分区之间无法通信。
- 分区 B 的动作:Sentinel S3 发现 Master 不可达,认为 Master 宕机了。S3 联合其他 Sentinel(如果有足够 quorum)执行故障转移,将 Slave 晋升为新 Master。此时分区 B 的客户端开始向新 Master 写入数据。
- 分区 A 的问题:旧 Master 实际上还活着,分区 A 的客户端仍然在向旧 Master 写入数据。
- 网络恢复后:旧 Master 发现自己被替代,降级为新 Master 的 Slave,触发全量同步。在旧 Master 上写入的数据 A 会全部丢失!
二、脑裂的危害

上图总结了脑裂的三大危害:
- 数据丢失(最严重):网络恢复后,旧 Master 被降级为 Slave,会清空自身数据并从新 Master 全量同步。脑裂期间写入旧 Master 的所有数据都会 不可逆地丢失。
- 数据不一致:同一个 Key 可能被不同客户端分别写入新旧 Master,最终以新 Master 的数据为准,旧数据被覆盖。
- 客户端混乱:不同客户端连接到不同 Master,读到不一致的数据,业务逻辑出错。
三、解决方案
方案一:配置 min-slaves-to-write + min-slaves-max-lag(最核心)
这是 Redis 官方推荐的最主要解决方案,核心思想是:让 Master 在从节点不可达时主动拒绝写入。

上图展示了 min-slaves-to-write + min-slaves-max-lag 的防护原理:
- 配置含义:
min-slaves-to-write 1表示 Master 至少要有 1 个可用的 Slave 连接才能接受写入;min-slaves-max-lag 10表示 Slave 的复制延迟不能超过 10 秒。两个条件必须 同时满足,Master 才会接受写入请求。 - 脑裂时的防护:网络分区后,旧 Master 联系不上 Slave,不满足
min-slaves-to-write条件,主动拒绝所有写入,返回NOREPLICAS错误。这样客户端无法向旧 Master 写入数据,网络恢复后就不会有数据丢失。 - 效果:确保任意时刻只有一个 Master 能接受写入,从根本上避免了脑裂。
配置示例(redis.conf):
# Master 至少需要 1 个 Slave 连接才能写入
min-slaves-to-write 1
# Slave 的复制延迟不能超过 10 秒
min-slaves-max-lag 10
方案二:合理配置 Sentinel 参数
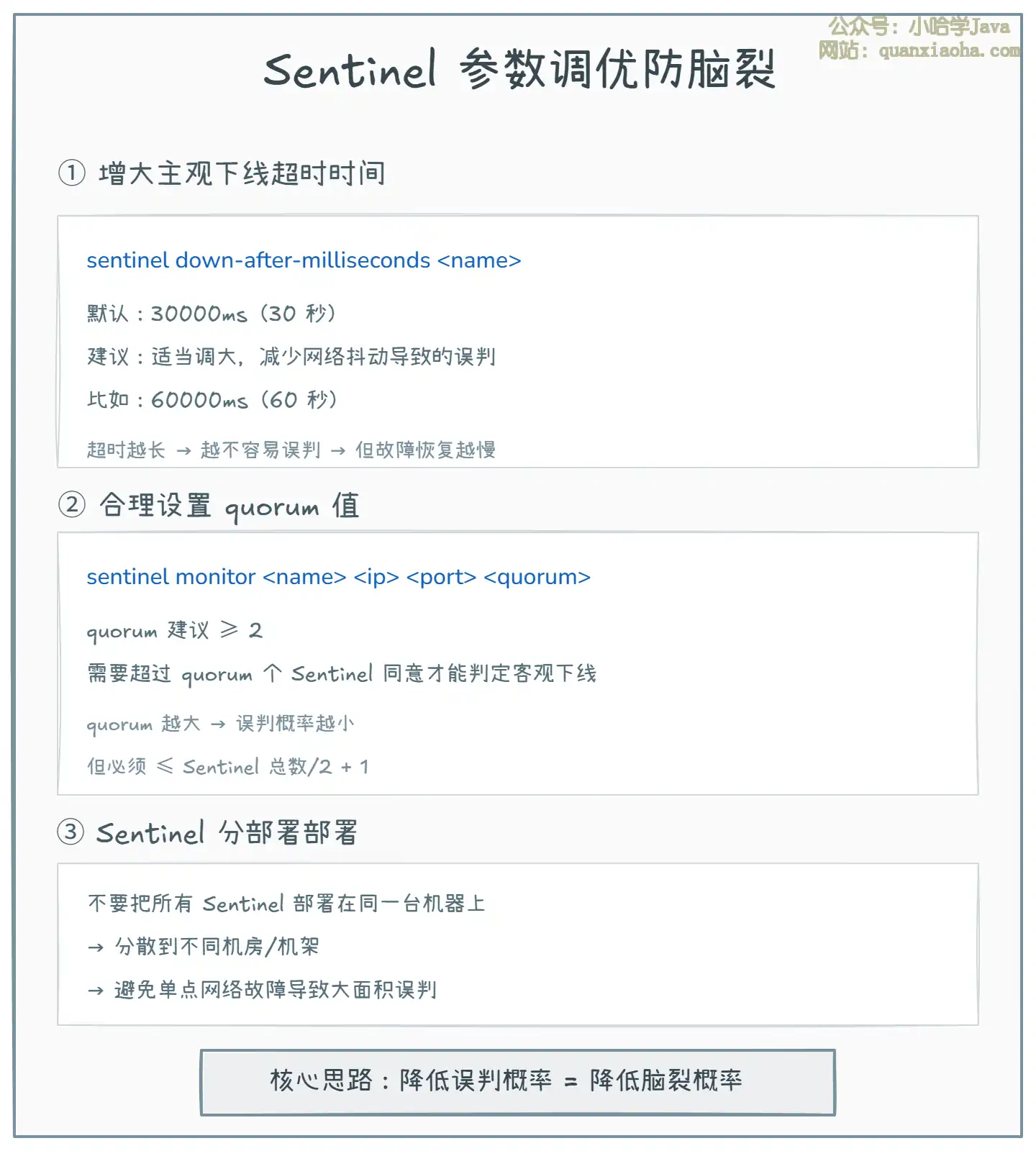
上图展示了通过 Sentinel 参数调优来降低脑裂概率:
- 增大
down-after-milliseconds:超时时间越长,Sentinel 越不容易因为短暂的网络抖动而误判 Master 宕机。但代价是故障恢复变慢,需要在 灵敏度 和 稳定性 之间权衡。 - 合理设置
quorum:quorum 值越大,需要越多的 Sentinel 同意才能判定客观下线,误判概率越小。一般建议 ≥ 2。 - Sentinel 分部署部署:不要把所有 Sentinel 放在同一台机器或同一机架上,避免单点网络故障导致大面积误判。
- 核心思路:降低 Sentinel 的误判概率,就能降低脑裂的发生概率。
方案三:Cluster 模式下的防护

上图展示了 Cluster 模式下的脑裂防护手段:
cluster-node-timeout:控制节点超时判定时间,适当调大可以减少网络抖动导致的误判。cluster-require-full-coverage yes(默认):只要有任何一个 slot 不可用,整个集群停止服务。这在脑裂场景下反而是一种保护——集群直接拒绝写入,避免数据不一致,但代价是牺牲了可用性。min-slaves-to-write:Cluster 中的每个 Master 节点同样支持这个配置,效果和哨兵模式一样。
四、方案对比与最佳实践

上图对比了各方案的优缺点和最佳实践:
min-slaves-to-write+min-slaves-max-lag是 最核心、必须配置 的方案。它从源头阻止了旧 Master 继续接受写入,是解决脑裂的根本手段。- 其他方案(调大超时、增大 quorum)是辅助手段,用于 降低脑裂的发生概率。
- 生产环境建议组合使用:必配
min-slaves-to-write+min-slaves-max-lag,同时合理设置 Sentinel 的超时和 quorum 参数,并将节点分散部署到不同机房/机架。
五、如何检测脑裂是否发生?

上图展示了脑裂的检测手段:
- 监控 Sentinel 日志:关注
+sdown和+odown事件,频繁的主客观下线可能意味着网络不稳定,脑裂风险增加。 - 监控复制偏移量:通过
INFO replication命令查看 Master 和 Slave 的replication offset差距,差距过大说明复制延迟严重。 - 监控 Master 切换事件:关注
+switch-master事件,短时间内多次切换可能是脑裂的信号。 - 监控连接的 Slave 数量:
connected_slaves突然变为 0 说明网络可能已经分区。
面试高频追问
-
追问一:
min-slaves-to-write设为多少合适?一般设为 1 即可(至少 1 个 Slave 连接才能写)。如果对数据安全性要求极高,可以设为 2,但会降低可用性(任意一个 Slave 挂了,Master 就拒绝写入)。
min-slaves-max-lag一般设为 10 秒,根据网络状况调整。 -
追问二:脑裂和 Sentinel 的 "主观下线 → 客观下线" 有什么关系?
脑裂的触发就是从 Sentinel 的主观下线开始的。网络分区后,分区 B 的 Sentinel 联系不上 Master,先标记主观下线,再联合其他 Sentinel 标记客观下线,然后触发故障转移。如果这个过程中是 误判(Master 实际还活着),就会产生脑裂。所以调大超时时间和 quorum 可以减少误判。
-
追问三:CAP 理论和 Redis 脑裂的关系?
脑裂本质是 CP vs AP 的取舍。Redis 选择的是 AP(可用性优先)——故障转移后新 Master 立即服务,不等待旧 Master 的数据同步。配置
min-slaves-to-write是在向 CP(一致性优先) 倾斜——宁可牺牲可用性(拒绝写入),也要保证数据一致性。这是一个工程上的权衡。
常见面试变体
- 变体一:"Redis 哨兵模式下网络分区会导致什么问题?"
- 变体二:"如何保证 Redis 主从切换时不丢数据?"
- 变体三:"Redis 的
min-slaves-to-write参数有什么作用?" - 变体四:"Redis 集群中出现两个 Master 怎么办?"
记忆口诀
脑裂原因:网络分区 → 哨兵误判 → 新旧两主同时写 → 数据丢失。
核心解法:min-slaves-to-write + min-slaves-max-lag,从节点不够就不让写。
辅助手段:调大超时、增大 quorum、分散部署、监控告警。
本质:CP 和 AP 的权衡,Redis 默认偏向 AP,配置后向 CP 倾斜。
总结
Redis 脑裂是网络分区导致出现两个 Master 同时接受写入的问题,网络恢复后旧 Master 降级为 Slave 会导致数据丢失。最核心的解决方案 是配置 min-slaves-to-write + min-slaves-max-lag,让 Master 在从节点不可达时主动拒绝写入。辅助手段包括调大 Sentinel 超时时间、增大 quorum 值、分散部署 Sentinel 节点,以及建立完善的监控告警机制。