ConcurrentHashMap 为什么在 JDK 1.8 中废弃分段锁?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
架构演进理解:面试官不仅仅是想知道 "废弃了" 这个事实,更是想知道你是否理解分段锁的设计局限性,以及 JDK 1.8 新方案解决了哪些问题。
-
性能权衡思维:考察你是否理解锁粒度、内存开销、并发度之间的权衡,以及为什么 "更简单的 synchronized" 反而比 "复杂的 ReentrantLock" 更好。
-
JVM 优化认知:是否了解 JDK 1.6 后 synchronized 的锁升级机制,以及它如何改变了并发编程的最佳实践。
核心答案
JDK 1.8 废弃分段锁的主要原因:分段锁并发度固定、内存开销大、实现复杂,而 CAS + synchronized 方案并发度更高、内存更省、实现更简洁:
| 对比维度 | JDK 1.7 分段锁 | JDK 1.8 CAS + synchronized |
|---|---|---|
| 并发度 | 最多 16(Segment 数量) | 等于桶数量(默认 16,可扩容) |
| 锁粒度 | 一个 Segment 锁多个桶 | 一个锁只锁一个桶 |
| 内存开销 | 每个 Segment 独立对象 | 无额外锁对象 |
| 扩容灵活性 | Segment 数量固定 | 桶数量动态增长 |
| 实现复杂度 | 复杂(双重哈希、Segment 管理) | 简洁(直接操作桶) |
一句话总结:分段锁是 "中间粒度" 的妥协方案,CAS + synchronized 实现了 "最细粒度" 的完美方案,并发度更高、内存更省。
深度解析
一、分段锁的设计局限性

上图详细展示了分段锁的三大局限。关键理解:
-
并发度固定:Segment 数量在创建时确定,无法随 HashMap 扩容而增加。当桶数量从 16 增长到 65536 时,仍然只有 16 把锁,每把锁保护的桶从 1 个变成 4096 个,竞争加剧。
-
内存浪费:每个 Segment 都是一个完整的 "小 HashMap",包含独立的数组、计数器、锁状态等,比单纯的 Node 数组多消耗不少内存。
-
两次哈希:先定位 Segment,再定位桶,增加了计算开销和代码复杂度。
二、CAS + synchronized 的优势
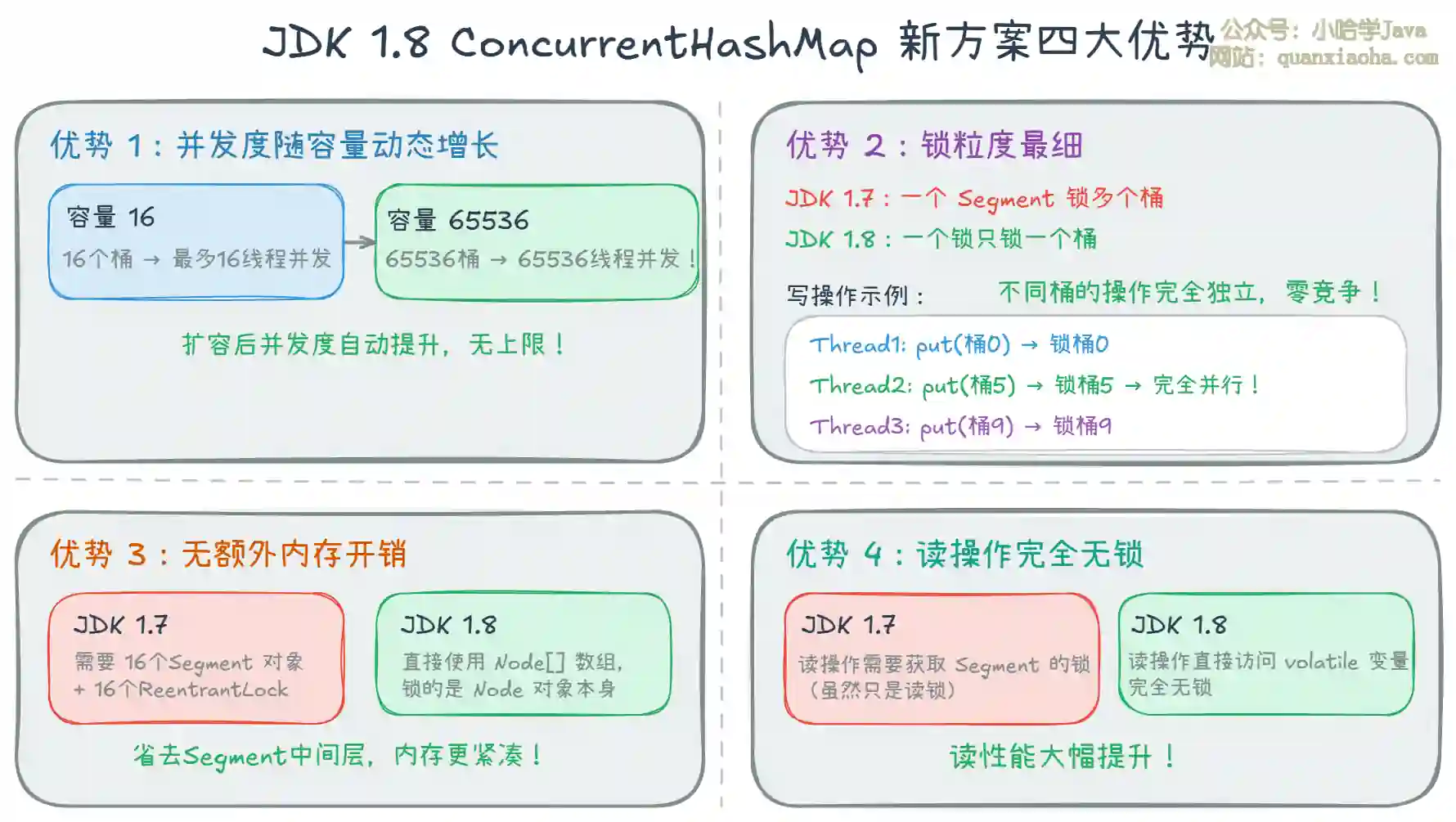
上图展示了 JDK 1.8 新方案的四大优势。核心价值:
- 并发度动态增长:随着 HashMap 扩容,并发度自动提升,理论上无上限
- 锁粒度最细:只锁当前操作的桶,不同桶完全并行
- 内存更省:去掉了 Segment 中间层,直接操作 Node 数组
- 读无锁:利用 volatile 可见性,读操作完全不需要加锁
三、为什么用 synchronized 而不是 ReentrantLock?
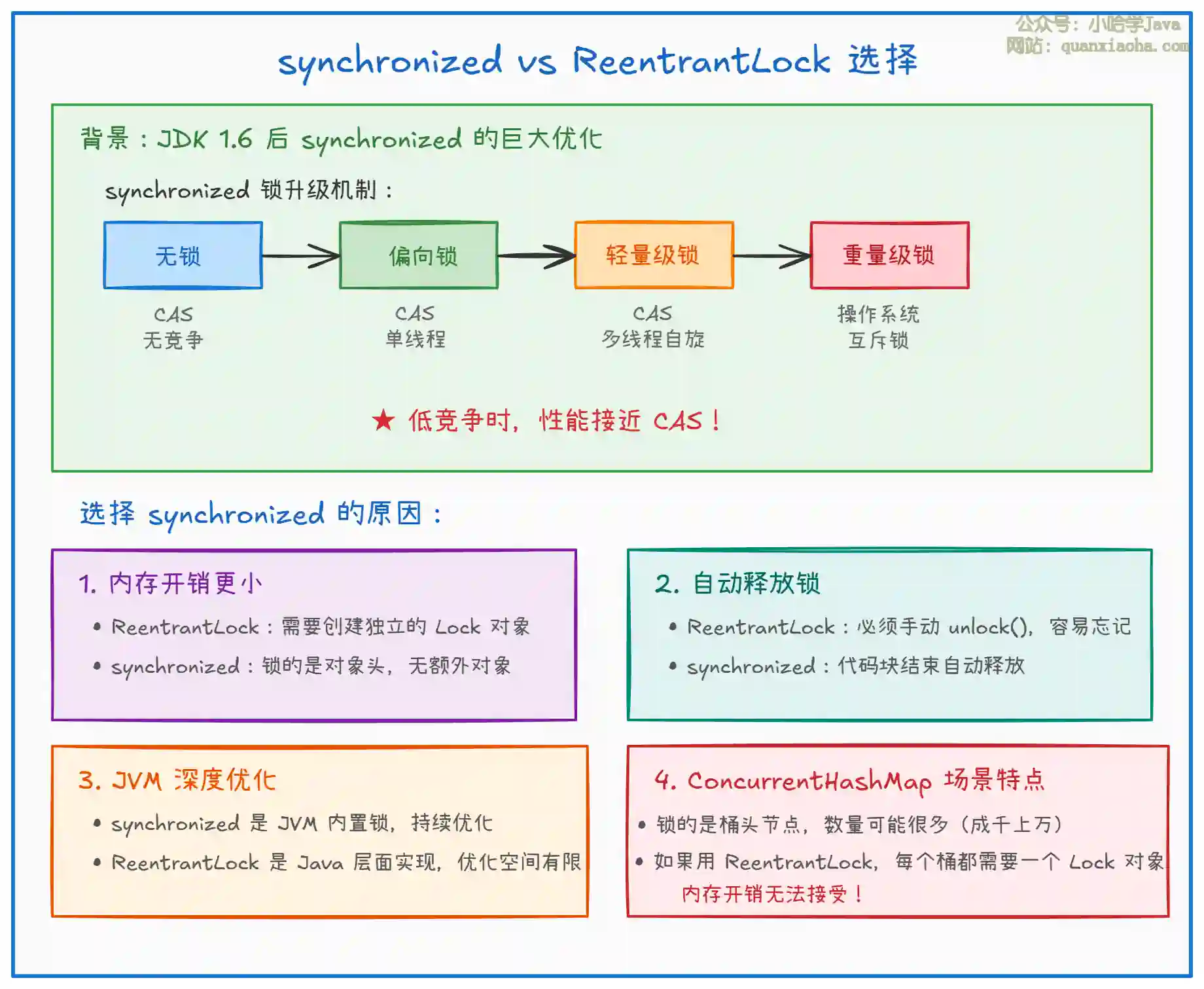
上图解释了为什么选择 synchronized。关键点:
- JDK 1.6 的锁升级:synchronized 不再是 "重量级锁" 的代名词,在低竞争时性能接近 CAS
- 内存开销:如果 65536 个桶都用 ReentrantLock,需要 65536 个 Lock 对象,内存开销巨大
- 自动释放:synchronized 不需要手动释放,代码更简洁,不会忘记 unlock
四、性能对比实测
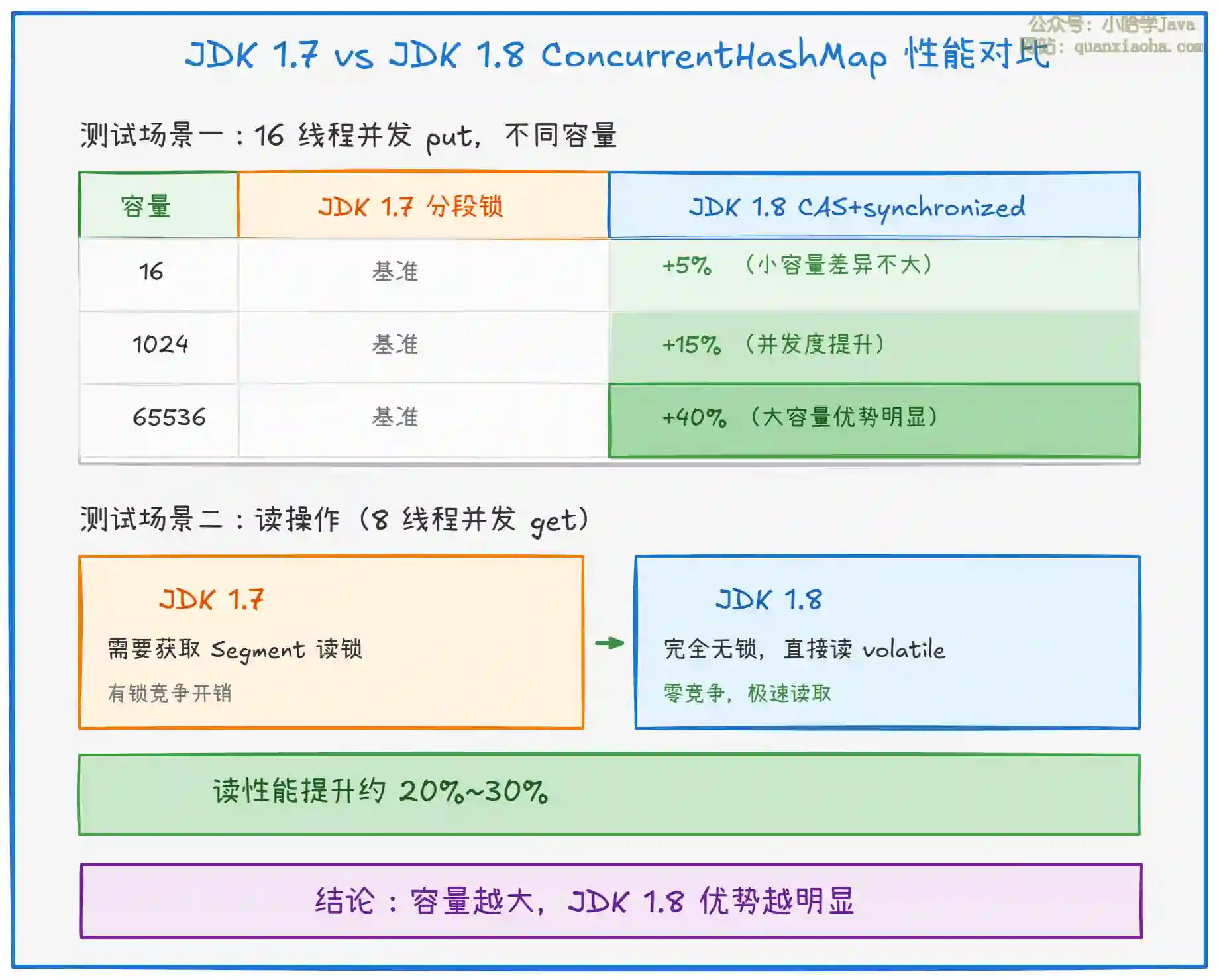
五、源码对比
// ==================== JDK 1.7 分段锁实现(简化)====================
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
int hash = hash(key.hashCode());
// 1. 定位 Segment(第一次哈希)
int segmentIndex = (hash >>> segmentShift) & segmentMask;
Segment<K,V> segment = segments[segmentIndex];
// 2. 在 Segment 内部 put(第二次哈希)
return segment.put(key, hash, value, false);
}
static final class Segment<K,V> extends ReentrantLock {
transient volatile HashEntry<K,V>[] table;
V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 3. 获取 Segment 的锁
lock();
try {
// 4. 在 Segment 内部定位桶
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
// ... 插入或更新
} finally {
unlock();
}
}
}
// ==================== JDK 1.8 CAS + synchronized 实现(简化)====================
public V put(K key, V value) {
int hash = spread(key.hashCode());
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 1. 直接定位桶(只有一次哈希)
if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 2. 空桶:CAS 无锁插入
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
break;
}
// 3. 非空桶:synchronized 锁桶头
else {
synchronized (f) {
// ... 插入或更新
}
break;
}
}
return null;
}
源码对比总结:
- JDK 1.7:两层结构(Segment → HashEntry),需要两次哈希,锁 Segment
- JDK 1.8:单层结构(Node[]),一次哈希,锁桶头或 CAS 无锁
面试高频追问
-
分段锁在 JDK 1.8 中完全消失了吗?
- 是的!JDK 1.8 完全移除了 Segment 类,不再有分段锁的概念
- 但
concurrencyLevel参数仍然保留,用于初始化容量估算
-
synchronized 不会造成性能问题吗?
- JDK 1.6 后 synchronized 有锁升级机制,低竞争时性能很好
- ConcurrentHashMap 中锁的是桶头节点,竞争分散,很少升级到重量级锁
-
CAS 失败后会怎样?
- 自旋重试!如果桶仍然为空,继续尝试 CAS
- 如果桶被其他线程占用了,则进入 synchronized 分支
常见面试变体
- "ConcurrentHashMap 在 JDK 1.7 和 1.8 有什么区别?"
- "为什么 JDK 1.8 用 synchronized 替代 ReentrantLock?"
- "分段锁有什么缺点?"
记忆口诀
分段锁三宗罪:并发度固定不随容量长、内存浪费 Segment 对象多、两次哈希定位效率低。
新方案四优势:并发度随容量涨、锁粒度细到桶、内存省去中间层、读操作完全无锁。
选 synchronized:JDK 1.6 锁升级性能好、无额外对象内存省、自动释放代码简。
总结
JDK 1.8 废弃分段锁的核心原因是 并发度固定、内存浪费、实现复杂。新的 CAS + synchronized 方案实现了 并发度动态增长(随容量扩容)、锁粒度最细(只锁单个桶)、内存更省(无 Segment 中间层)、读无锁(volatile 保证可见性)。选择 synchronized 而非 ReentrantLock 是因为 JDK 1.6 后的锁升级优化,以及无额外内存开销的优势。记住:分段锁是历史的妥协,CAS + synchronized 才是最优解。