InnoDB 中索引类型有哪些?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道索引类型的名称,更是想知道你是否理解不同索引的底层结构(聚簇 vs 非聚簇)、存储方式、查询效率差异。
-
性能优化意识:考察你是否清楚各类索引的适用场景,能否在实际表设计中根据业务特点选择合适的索引类型,避免索引失效或不必要的索引。
-
原理深度:是否理解 "回表"、"覆盖索引"、"最左前缀" 等核心概念,能否解释为什么某些查询快、某些查询慢。
核心答案
InnoDB 的索引从结构上分为 两大类,从功能上分为多种类型:
- 按结构分类:
- 聚簇索引(Clustered Index):主键索引,叶子存数据。
- 二级索引(Secondary Index):非主键,叶子存主键值。
- 按功能分类(二级索引):
- 普通索引(Index): 最基本的索引 。
- 唯一索引(Unique) :允许 NULL,值唯一 。
- 主键索引(Primary Key):不允许 NULL,唯一非空。
- 联合索引(Composite):多列组合索引 。
- 前缀索引(Prefix):字符串前 n 个字符。
- 全文索引(Full-text):文本搜索(5.6+ 支持)。
一句话总结:InnoDB 只有两种物理结构 —— 聚簇索引(主键)和 二级索引(非主键),其他都是功能层面的划分。
深度解析
一、聚簇索引 vs 二级索引
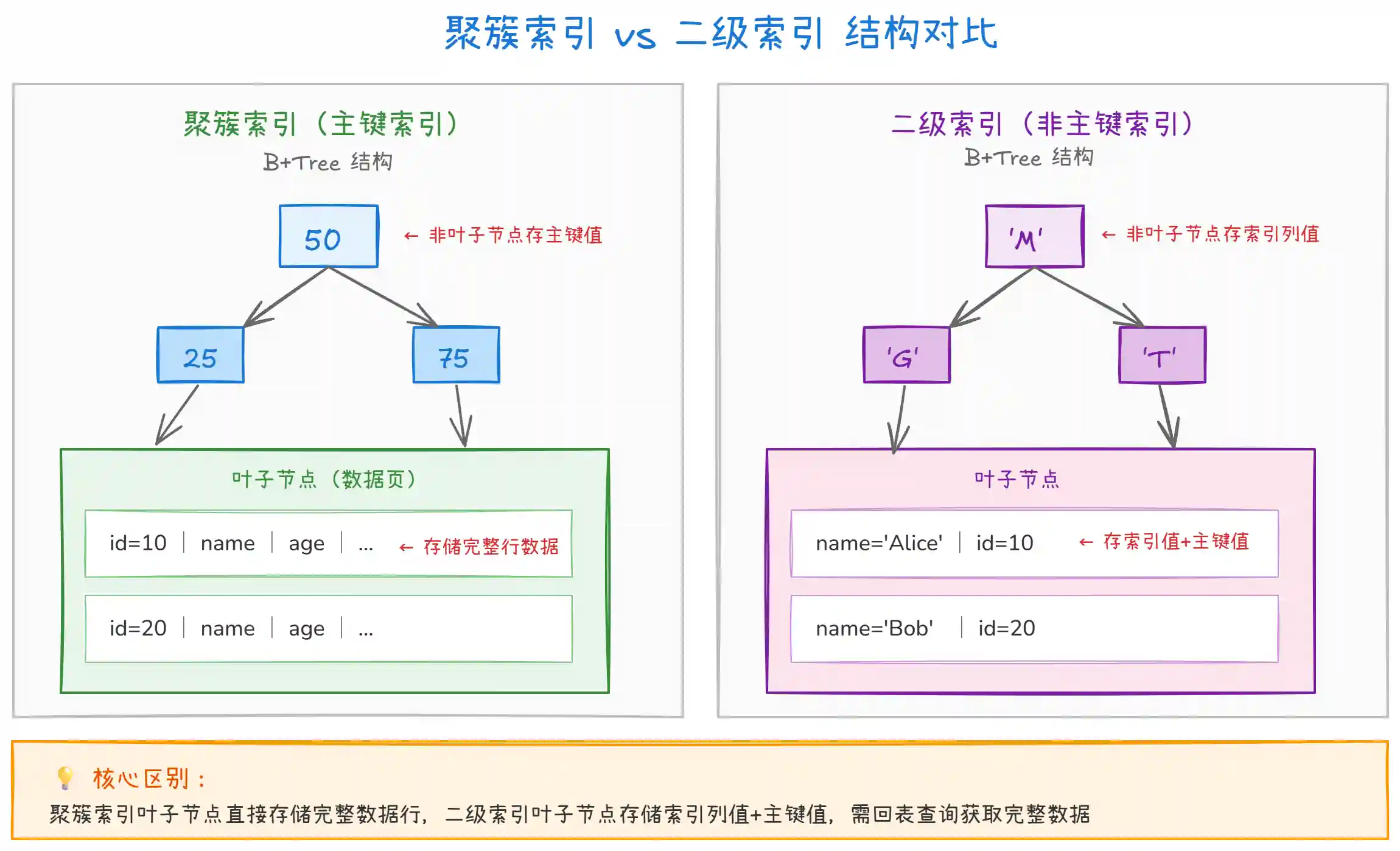
上图展示了聚簇索引和二级索引的核心结构差异:
-
聚簇索引(Clustered Index):
- 叶子节点直接存储完整的行数据,数据和索引合二为一
- 一张表只能有一个聚簇索引(通常是主键)
- 数据按主键顺序物理存储,范围查询效率高
- 如果没有显式定义主键,InnoDB 会选择第一个非空唯一索引;都没有则生成 6 字节的隐藏主键
-
二级索引(Secondary Index):
- 叶子节点存储索引列的值 + 主键值
- 一张表可以有多个二级索引
- 查询时如果需要其他列,必须 "回表" 查聚簇索引
二、回表查询过程
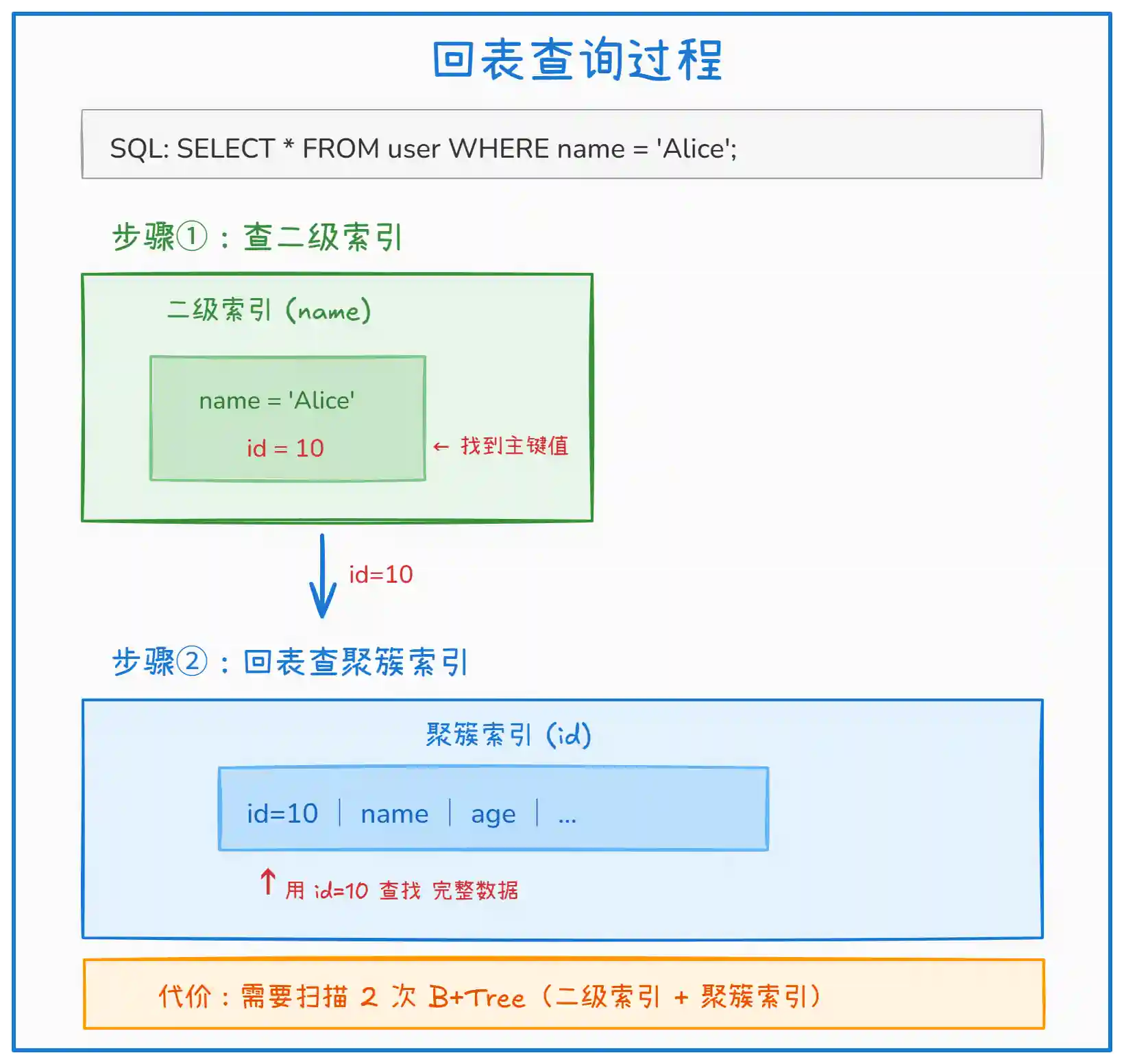
上图展示了回表查询的完整过程:
- 第一步:在
name列的二级索引中查找'Alice',找到对应的主键值id=10 - 第二步:拿着主键值
id=10回到聚簇索引中查找完整的行数据 - 性能代价:需要访问两棵 B+Tree,产生两次随机 I/O
优化方案 —— 覆盖索引:
-- 如果只需要 name 和 id,不需要回表
SELECT id, name FROM user WHERE name = 'Alice';
-- 因为二级索引已经包含了 name 和 id,直接返回,无需回表
三、各类索引详解
1. 主键索引
-- 创建方式
CREATE TABLE user (
id INT PRIMARY KEY, -- 方式一:列级约束
name VARCHAR(50)
);
CREATE TABLE user (
id INT,
name VARCHAR(50),
PRIMARY KEY (id) -- 方式二:表级约束
);
ALTER TABLE user ADD PRIMARY KEY (id); -- 方式三:后续添加
特点:
- 是聚簇索引,叶子节点存储完整行数据
- 唯一且非空(
NOT NULL + UNIQUE) - 一张表只能有一个主键
- 推荐使用自增整数作为主键(减少页分裂)
2. 唯一索引
-- 创建方式
CREATE TABLE user (
id INT PRIMARY KEY,
email VARCHAR(100) UNIQUE -- 列级约束
);
CREATE UNIQUE INDEX idx_email ON user(email); -- 独立创建
特点:
- 索引列的值必须唯一(允许 NULL,且多个 NULL 不冲突)
- 是二级索引,叶子节点存储主键值
- 查询时会使用索引优化
与主键的区别:
| 对比项 | 主键索引 | 唯一索引 |
|---|---|---|
| 是否允许 NULL | ❌ 不允许 | ✅ 允许 |
| 每表数量 | 只能 1 个 | 可以多个 |
| 物理结构 | 聚簇索引 | 二级索引 |
| 存储内容 | 完整行数据 | 主键值 |
3. 普通索引
-- 创建方式
CREATE INDEX idx_name ON user(name);
ALTER TABLE user ADD INDEX idx_name(name);
特点:
- 最基本的索引类型,无特殊约束
- 允许重复值和 NULL
- 是二级索引
适用场景:频繁作为查询条件的列,如 WHERE、ORDER BY、JOIN 的列。
4. 联合索引
-- 创建方式
CREATE INDEX idx_name_age ON user(name, age);
ALTER TABLE user ADD INDEX idx_name_age(name, age);
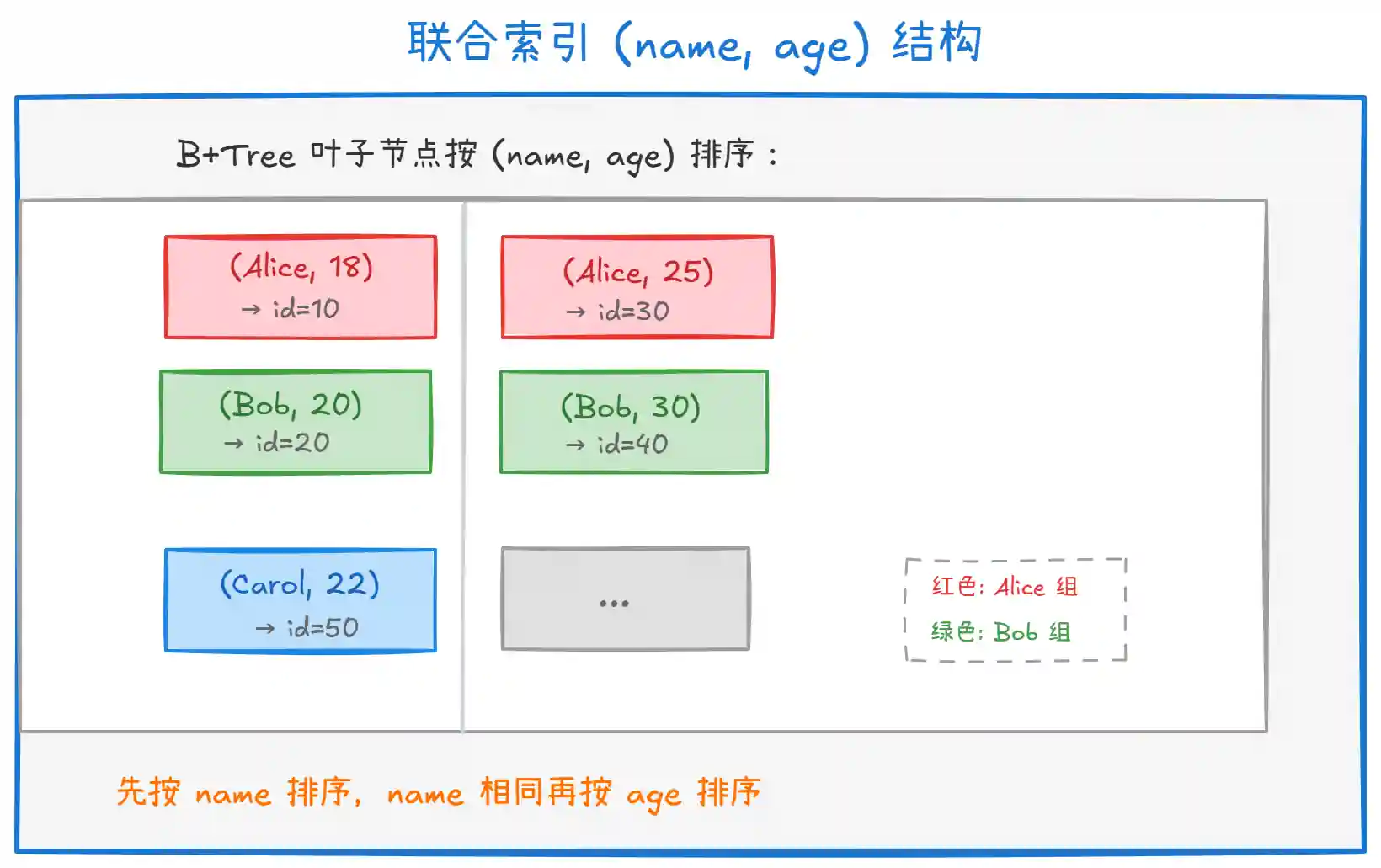
最左前缀原则:
-- ✅ 走索引
SELECT * FROM user WHERE name = 'Alice';
SELECT * FROM user WHERE name = 'Alice' AND age = 18;
SELECT * FROM user WHERE name = 'Alice' AND age > 15;
-- ❌ 不走索引(缺少最左列 name)
SELECT * FROM user WHERE age = 18;
-- ✅ 部分走索引(只有 name 走索引,age 不走)
SELECT * FROM user WHERE name = 'Alice' AND age > 15 ORDER BY create_time;
设计原则:
- 把区分度高的列放在左边
- 把常用的查询列放在左边
- 考虑 "覆盖索引" 优化
5. 前缀索引
-- 创建方式:只取前 10 个字符建索引
CREATE INDEX idx_email_prefix ON user(email(10));
适用场景:
- 字符串列很长(如 URL、邮箱、大文本)
- 列的前几个字符区分度已经足够
注意:
- 前缀索引无法用于
ORDER BY和GROUP BY - 无法用于覆盖索引(必须回表)
-- 如何选择前缀长度?
SELECT
COUNT(DISTINCT LEFT(email, 5)) / COUNT(*) AS prefix5,
COUNT(DISTINCT LEFT(email, 10)) / COUNT(*) AS prefix10,
COUNT(DISTINCT email) / COUNT(*) AS full
FROM user;
-- 选择区分度接近完整索引的最短前缀
6. 全文索引
-- 创建方式
CREATE FULLTEXT INDEX idx_content ON article(title, content);
-- 使用方式
SELECT * FROM article
WHERE MATCH(title, content) AGAINST('MySQL 索引');
特点:
- MySQL 5.6+ InnoDB 开始支持全文索引
- 用于文本内容的全文搜索
- 支持中文分词(需要配置
ngram解析器)
适用场景:文章内容搜索、商品描述搜索等。
四、索引设计最佳实践
-- ✅ 好的索引设计
-- 1. 选择区分度高的列
SELECT COUNT(DISTINCT column) / COUNT(*) FROM table;
-- 区分度 > 0.1 比较适合建索引
-- 2. 联合索引遵循最左前缀
CREATE INDEX idx_status_create_time ON orders(status, create_time);
-- 支持:WHERE status = 1
-- 支持:WHERE status = 1 ORDER BY create_time
-- 3. 利用覆盖索引避免回表
CREATE INDEX idx_user_cover ON orders(user_id, status, amount);
SELECT user_id, status, amount FROM orders WHERE user_id = 100;
-- 不需要回表!
-- 4. 前缀索引节省空间
CREATE INDEX idx_url_prefix ON web_logs(url(20));
-- ❌ 不好的索引设计
-- 1. 在低区分度列建索引
CREATE INDEX idx_gender ON user(gender); -- 只有 男/女/未知
-- 2. 频繁更新的列
CREATE INDEX idx_update_time ON user(update_time); -- 每次更新都要改索引
-- 3. 小表的全部列
CREATE INDEX idx_all ON tiny_table(col1, col2, col3); -- 表太小,全表扫描更快
面试高频追问
-
为什么 InnoDB 推荐使用自增主键?
- 聚簇索引按主键顺序存储,自增主键是顺序写入,减少页分裂
- 避免随机 I/O,提升写入性能
- 二级索引存储主键值,整数主键占用空间小(4 字节 vs UUID 36 字节)
-
什么是覆盖索引?有什么好处?
- 查询的列都在索引中,不需要回表查聚簇索引
- 减少一次 B+Tree 查找,降低 I/O
- 可以通过
EXPLAIN看到Using index
-
联合索引 (a, b, c),哪些查询能走索引?
- ✅
WHERE a = 1 - ✅
WHERE a = 1 AND b = 2 - ✅
WHERE a = 1 AND b = 2 AND c = 3 - ❌
WHERE b = 2(缺少最左列) - ❌
WHERE c = 3(缺少最左列) - ✅
WHERE a = 1 AND c = 3(a 走索引,c 不走)
- ✅
-
什么情况下索引会失效?
LIKE以%开头:WHERE name LIKE '%abc'- 对索引列做运算:
WHERE YEAR(create_time) = 2024 - 隐式类型转换:
WHERE phone = 13800138000(phone 是 VARCHAR) OR条件中有非索引列!=、<>、NOT IN、IS NOT NULL(不一定,看优化器)
常见面试变体
- "聚簇索引和非聚簇索引有什么区别?"
- "什么是回表?如何避免?"
- "联合索引的最左前缀原则是什么?"
- "为什么主键推荐用自增 ID 而不是 UUID?"
记忆口诀
聚簇存数据,二级存主键; 回表多一次,覆盖来优化。 联合看最左,前缀省空间; 自增主键好,UUID 乱顺序。
总结
InnoDB 物理上只有 聚簇索引(主键,存完整数据)和 二级索引(非主键,存主键值)两种结构。功能上分为主键索引、唯一索引、普通索引、联合索引、前缀索引、全文索引等。核心优化思路是:减少回表(覆盖索引)、遵循最左前缀(联合索引)、选择高区分度列、使用自增主键。