Set 如何保证元素不重复的?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
底层实现理解:面试官不仅仅是想知道 "Set 不重复" 这个结论,更是想知道你是否了解
HashSet底层是用HashMap实现的这一经典设计。 -
判断机制掌握:考察你是否理解判断元素重复的完整逻辑:先比
hashCode(),再比equals(),以及为什么要这样设计。 -
不同实现对比:是否了解
HashSet、TreeSet、LinkedHashSet保证不重复的不同机制。
核心答案
以最常用的 HashSet 为例,它底层基于 HashMap 实现,元素作为 HashMap 的 key 存储,利用 key 的唯一性来保证元素不重复:
| Set 实现类 | 底层结构 | 判重机制 | 特点 |
|---|---|---|---|
HashSet |
HashMap |
hashCode() + equals() |
无序,查询 O(1) |
LinkedHashSet |
LinkedHashMap |
hashCode() + equals() |
保持插入顺序 |
TreeSet |
TreeMap |
compareTo() 或 Comparator |
有序,查询 O(log n) |
一句话总结:HashSet 利用 HashMap 的 key 唯一性,通过 "hashCode 相同 + equals 返回 true" 判断重复,重复元素不会被插入。
深度解析
一、HashSet 底层结构
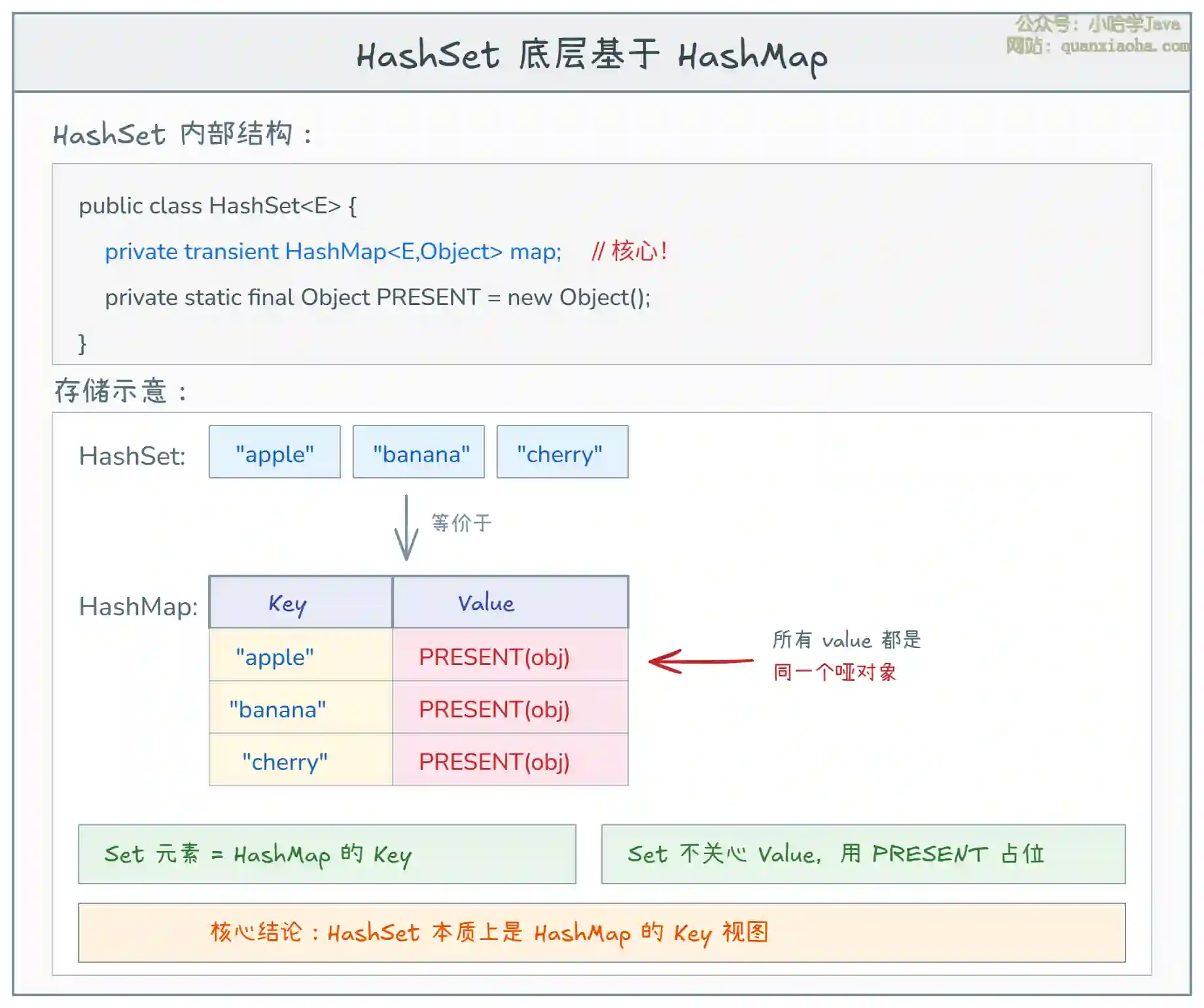
上图揭示了 HashSet 的核心设计。关键点:
- 组合而非继承:HashSet 内部持有一个
HashMap实例,所有操作都委托给它 - 哑对象 PRESENT:因为 HashMap 需要 key-value 对,但 Set 只需要 key,所以 value 用一个共享的
Object占位 - 设计模式:这是 "装饰器模式" 或 "委托模式" 的典型应用
二、add() 方法判重流程
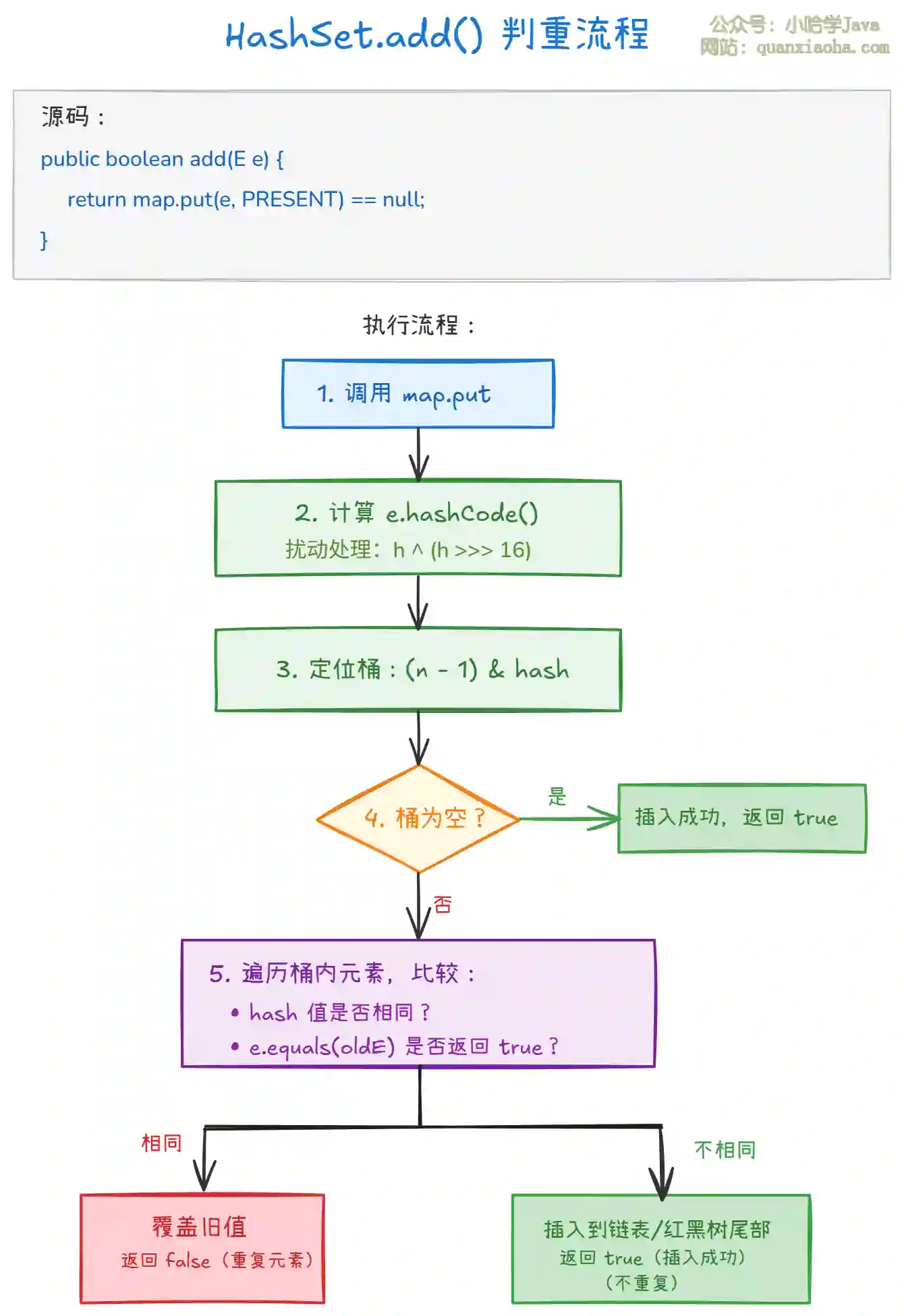
上图展示了 add() 方法的完整判重流程。核心逻辑:
-
返回值含义:
true:元素不重复,插入成功false:元素已存在,插入失败(但不会报错)
-
两步判断:
- 先比较
hashCode():快速筛选,hash 不同则一定不重复 - 再调用
equals():hash 相同时,确认是否真的相等
- 先比较
-
为什么两步?
hashCode()是整数比较,速度快;equals()可能涉及复杂逻辑,放后面减少调用。
三、核心源码解析
// ==================== HashSet 源码 ====================
public class HashSet<E> extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
// 底层存储:HashMap
private transient HashMap<E,Object> map;
// 哑对象:所有 value 都用这个
private static final Object PRESENT = new Object();
// 构造函数
public HashSet() {
map = new HashMap<>();
}
// add 方法:委托给 HashMap.put()
public boolean add(E e) {
// put 返回旧值,null 表示之前不存在
return map.put(e, PRESENT) == null;
}
// contains 方法:委托给 HashMap.containsKey()
public boolean contains(Object o) {
return map.containsKey(o);
}
// remove 方法:委托给 HashMap.remove()
public boolean remove(Object o) {
return map.remove(o) == PRESENT;
}
// size 方法
public int size() {
return map.size();
}
}
四、TreeSet 的不同机制

上图展示了 TreeSet 的不同判重机制。关键点:
- 基于比较器:TreeSet 用
compareTo()或compare()判断相等,而非hashCode()+equals() - 排序特性:TreeSet 的主要目的是排序,元素自动按顺序排列
- 一致性风险:如果
compareTo()返回 0 但equals()返回 false,会导致 Set 语义混乱
五、三种 Set 实现对比
| 特性 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
| 底层结构 | HashMap | LinkedHashMap | TreeMap |
| 判重机制 | hashCode + equals | hashCode + equals | compareTo/compare |
| 是否有序 | ❌ 无序 | ✅ 插入顺序 | ✅ 排序顺序 |
| 查询效率 | O(1) | O(1) | O(log n) |
| 插入效率 | O(1) | O(1) | O(log n) |
| 是否允许 null | ✅ 一个 null | ✅ 一个 null | ❌ 不允许(比较会 NPE) |
| 线程安全 | ❌ 不安全 | ❌ 不安全 | ❌ 不安全 |
// 使用示例
Set<String> hashSet = new HashSet<>(); // 无序,最快
Set<String> linkedHashSet = new LinkedHashSet<>(); // 保持插入顺序
Set<String> treeSet = new TreeSet<>(); // 自动排序
hashSet.add("c");
hashSet.add("a");
hashSet.add("b");
// 输出可能是:a, c, b(顺序不确定)
linkedHashSet.add("c");
linkedHashSet.add("a");
linkedHashSet.add("b");
// 输出一定是:c, a, b(插入顺序)
treeSet.add("c");
treeSet.add("a");
treeSet.add("b");
// 输出一定是:a, b, c(自然排序)
面试高频追问
-
HashSet 允许添加 null 吗?
- 允许!最多一个 null(因为 HashMap 允许一个 null key)
- null 的 hashCode() 会被特殊处理,返回 0
-
如果只重写 equals() 不重写 hashCode() 会怎样?
- HashSet 判重失效!相同内容的对象可能被当作不同元素
- 因为 hashCode 不同,会进入不同桶,equals() 根本不会被调用
-
HashSet 和 ArrayList 的 contains() 性能差异?
HashSet.contains():O(1),基于 hash 直接定位ArrayList.contains():O(n),需要遍历全部元素- 频繁查找时用 HashSet
常见面试变体
- "HashSet 的底层实现原理是什么?"
- "HashSet 如何判断两个元素是否重复?"
- "HashSet、LinkedHashSet、TreeSet 的区别?"
- "为什么重写 equals() 必须重写 hashCode()?"
记忆口诀
HashSet 原理:底层就是 HashMap,元素当 key,PRESENT 当 value。
判重逻辑:先比 hash 快速筛,再比 equals 确认,都相同才算重复。
三种 Set:HashSet 无序最快,LinkedHashSet 保序,TreeSet 排序。
总结
HashSet 保证元素不重复的核心机制是:底层基于 HashMap 实现,元素作为 key 存储,利用 HashMap 的 key 唯一性。判断重复时,先比较 hashCode(),相同再调用 equals(),都返回 true 才认为是重复元素。TreeSet 则不同,使用 compareTo() 或 Comparator 判断相等。记住:Set 元素必须正确实现 hashCode() 和 equals()。