MySQL 中 count(1)、count(*) 与 count(列名) 的区别?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
SQL 基础理解:面试官不仅仅是想知道 "有什么区别",更是想考察你是否理解
COUNT()函数的语义——统计的是 行数 还是 非 NULL 值的数量。 -
NULL 值处理:考察你是否清楚
count(列名)会忽略 NULL 值,而count(*)和count(1)不会,这是很多面试者容易踩的坑。 -
性能优化意识:考察你是否了解不同写法在 MySQL 不同版本中的执行效率差异,以及 InnoDB 对
count(*)的优化机制。
核心答案
三种 COUNT 方式的语义对比:
| 写法 | 统计内容 | NULL 值处理 | 执行效率 |
|---|---|---|---|
count(*) |
统计 总行数 | 不忽略 NULL | ⭐⭐⭐⭐⭐ 最优(MySQL 优化) |
count(1) |
统计 总行数 | 不忽略 NULL | ⭐⭐⭐⭐ 等同于 count(*) |
count(列名) |
统计 该列非 NULL 的行数 | 忽略 NULL | ⭐⭐⭐ 需要判断列值 |
一句话总结:count(*) 和 count(1) 效果相同,统计所有行;count(列名) 只统计该列 非 NULL 的行数。推荐使用 count(*)。
深度解析
一、核心区别:NULL 值处理
这是三种写法最本质的区别:
-- 测试表
CREATE TABLE user (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT
);
INSERT INTO user VALUES (1, 'Alice', 25);
INSERT INTO user VALUES (2, 'Bob', NULL); -- age 为 NULL
INSERT INTO user VALUES (3, NULL, 30); -- name 为 NULL
INSERT INTO user VALUES (4, NULL, NULL); -- 两个都是 NULL
-- 查询对比
SELECT count(*) FROM user; -- 结果:4(统计所有行)
SELECT count(1) FROM user; -- 结果:4(统计所有行)
SELECT count(name) FROM user; -- 结果:2(只有 Alice、Bob 的 name 非 NULL)
SELECT count(age) FROM user; -- 结果:2(只有 Alice、Carol 的 age 非 NULL)
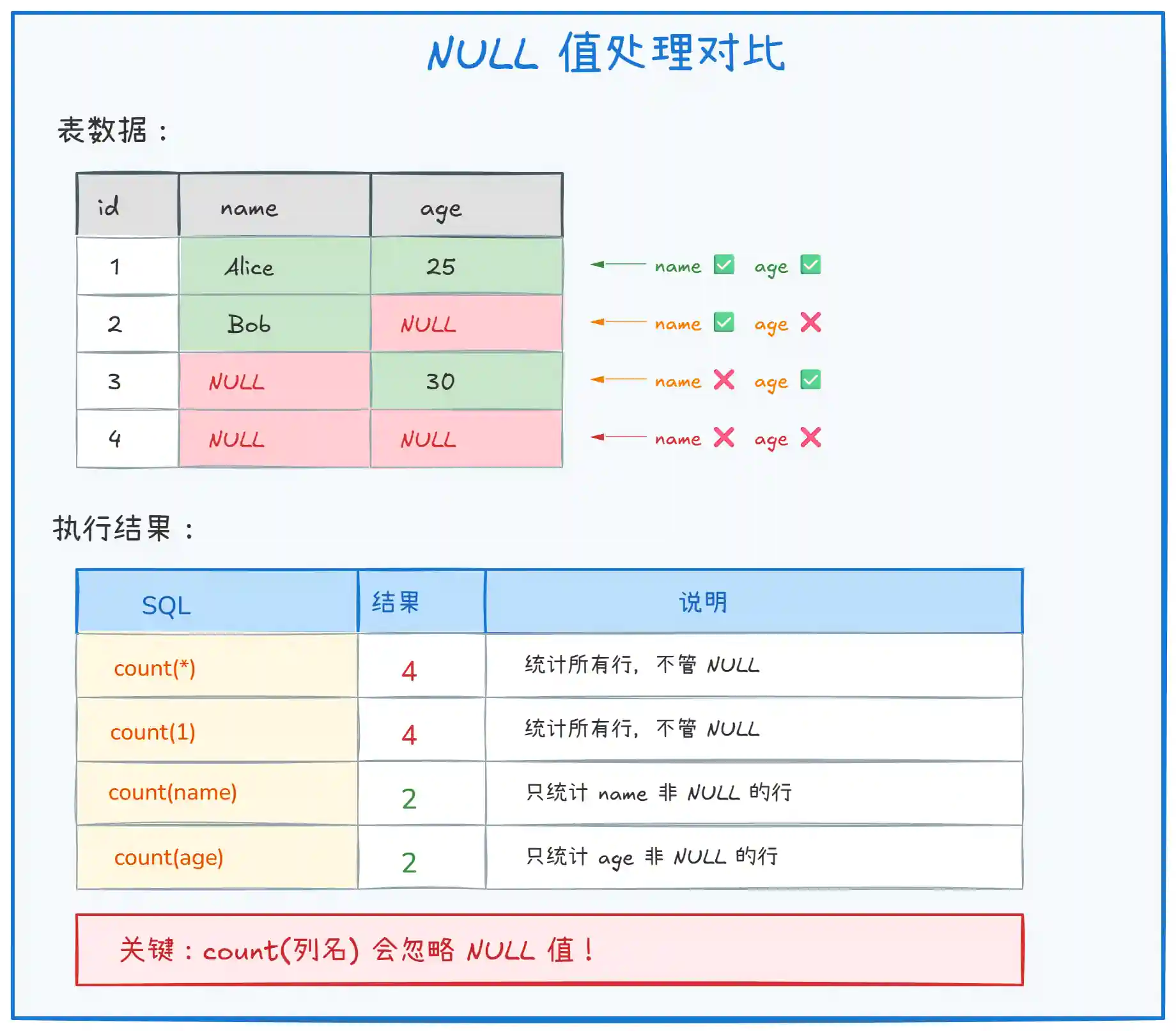
上图展示了三种 COUNT 方式对 NULL 值的处理差异。核心要点:
count(*):统计表的 总行数,不管列值是否为 NULLcount(1):语义上是 "统计每一行 1 这个表达式非 NULL 的数量",实际上 MySQL 会优化成和count(*)一样count(列名):统计该列 非 NULL 值的行数,会跳过 NULL 值
二、执行效率对比
流传的误区:很多人认为 count(1) 比 count(*) 快,因为 count(*) 会扫描所有列。
实际情况:在现代 MySQL(5.7+)中,两者效率 完全相同,甚至 count(*) 更优。

为什么 count(*) 更快?
- MySQL 专门优化:InnoDB 对
count(*)做了特殊优化,会自动选择 最小的辅助索引 进行扫描 - 不扫描全部列:
count(*)不会读取所有列数据,只统计行数 count(1)会被优化成count(*),两者执行计划完全相同
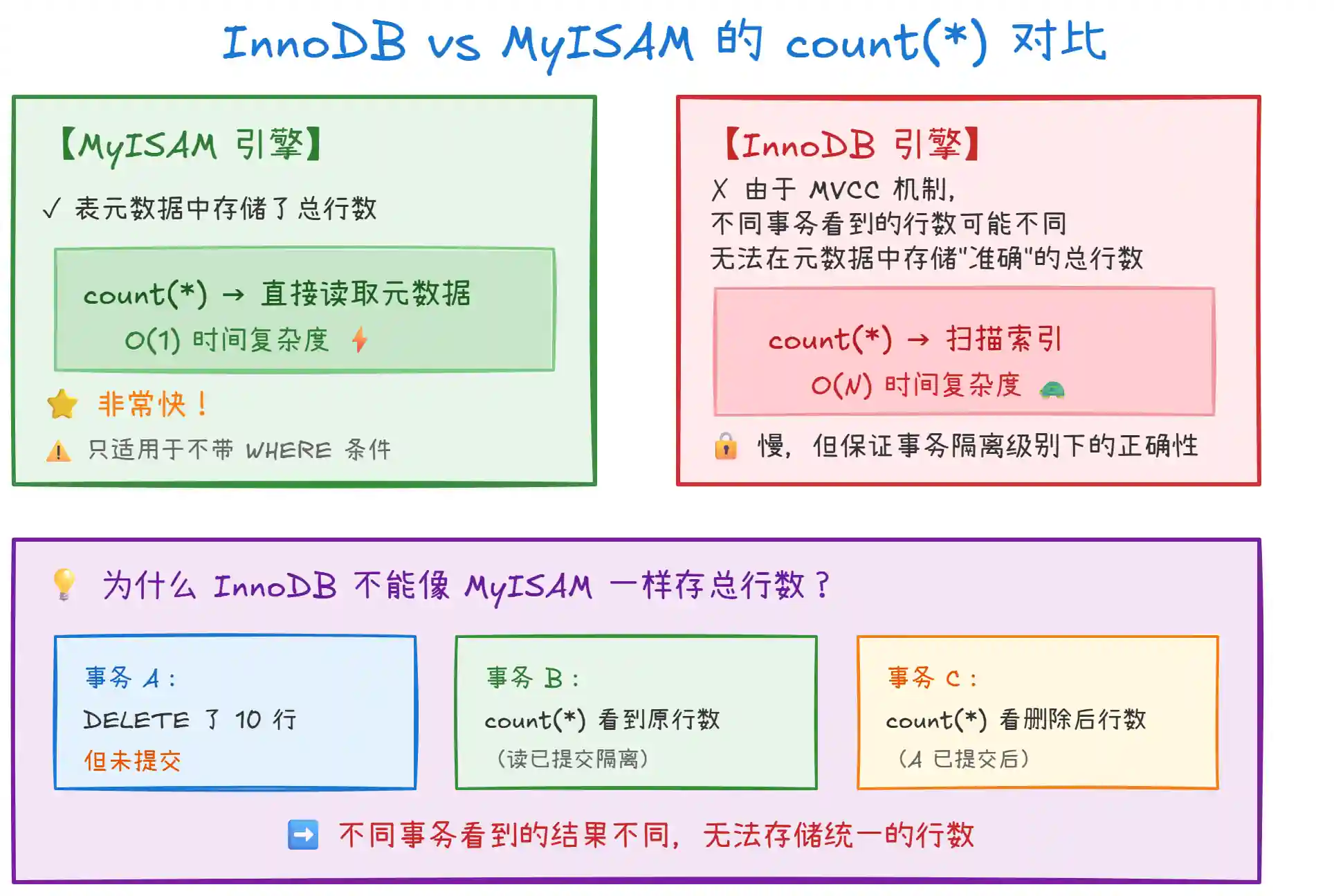
三、为什么 InnoDB 的 count(*) 这么慢?
很多人发现 InnoDB 的 count(*) 比 MyISAM 慢很多,这是因为:
四、大表 count 优化方案
对于 InnoDB 大表的 count 查询,可以考虑以下优化方案:
方案一:使用缓存
// 使用 Redis 缓存总数
public long getUserCount() {
String count = redis.get("user:count");
if (count != null) {
return Long.parseLong(count);
}
// 缓存不存在,查询数据库并缓存
long cnt = userMapper.selectCount(null);
redis.set("user:count", String.valueOf(cnt), 300); // 缓存 5 分钟
return cnt;
}
方案二:维护计数表
-- 创建计数表
CREATE TABLE table_counts (
table_name VARCHAR(50) PRIMARY KEY,
row_count BIGINT
);
-- 通过触发器或业务代码维护计数
INSERT INTO table_counts VALUES ('user', 0);
UPDATE table_counts SET row_count = row_count + 1 WHERE table_name = 'user';
方案三:估算(不要求精确)
-- 使用 EXPLAIN 估算
EXPLAIN SELECT * FROM user;
-- 查看 rows 列,是估算值
-- 适用于不要求精确计数的场景
五、使用场景建议
| 场景 | 推荐写法 | 原因 |
|---|---|---|
| 统计总行数 | count(*) |
语义清晰、MySQL 优化、推荐写法 |
| 统计某列非空数量 | count(列名) |
语义明确,会忽略 NULL |
| 联合统计 | count(DISTINCT 列名) |
统计去重后的非 NULL 数量 |
| 条件统计 | SUM(CASE WHEN 条件 THEN 1 ELSE 0 END) |
更灵活的条件统计 |
-- 推荐写法
SELECT count(*) FROM user; -- 统计总行数
SELECT count(*) FROM user WHERE age > 18; -- 条件统计
-- 特定场景
SELECT count(email) FROM user; -- 统计有邮箱的用户数
SELECT count(DISTINCT age) FROM user; -- 统计不同年龄的数量
-- 复杂条件统计
SELECT
count(*) as total,
SUM(CASE WHEN age > 18 THEN 1 ELSE 0 END) as adult,
SUM(CASE WHEN gender = 'F' THEN 1 ELSE 0 END) as female
FROM user;
面试高频追问
-
追问一:为什么 InnoDB 的
count(*)比 MyISAM 慢?- 答:MyISAM 在表元数据中存储了总行数,
count(*)直接读取即可,O(1) 复杂度;InnoDB 由于 MVCC 机制,不同事务看到的行数可能不同,无法存储统一的计数,需要扫描索引统计,O(N) 复杂度。
- 答:MyISAM 在表元数据中存储了总行数,
-
追问二:
count(id)和count(*)哪个快?- 答:
count(*)更快。因为count(*)会选择最小的辅助索引扫描;而count(id)虽然主键上有索引,但 MySQL 不一定会选择它(除非它是最小的索引)。而且count(id)还需要判断 NULL 值。
- 答:
-
追问三:如何优化大表的
count(*)查询?- 答:1)使用 Redis 缓存计数结果;2)维护独立的计数表;3)使用估算(EXPLAIN 的 rows);4)确保有合适的辅助索引供 MySQL 选择。
常见面试变体
- "
count(*)和count(1)哪个效率高?" - "为什么
count(列名)结果比count(*)少?" - "如何优化 InnoDB 大表的 count 查询?"
- "
count(DISTINCT 列名)是什么意思?"
记忆口诀
COUNT 三剑客:
- 星号统计行:
count(*)统计所有行,MySQL 优化最快 - 数字效果同:
count(1)等同于count(*) - 列名忽略空:
count(列名)只统计非 NULL 值
总结
count(*) 和 count(1) 效果相同,统计所有行数,MySQL 5.7+ 会将两者优化成相同的执行计划,推荐使用语义更清晰的 count(*);count(列名) 只统计该列 非 NULL 的行数。InnoDB 由于 MVCC 机制无法像 MyISAM 一样存储精确行数,大表 count 需要通过缓存或计数表优化。