说说 HashMap 的扩容机制?如何扩容的?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道 "会扩容" 这个事实,更是想知道你是否理解扩容的触发条件、扩容阈值计算、以及扩容时元素如何重新分布。
-
源码理解深度:考察你是否读过
resize()方法的源码,是否理解 JDK 1.8 中 "高低位链表" 的优化设计,以及为什么扩容后元素要么在原位置,要么在 "原位置 + 原容量" 的位置。 -
版本演进意识:JDK 1.7 和 JDK 1.8 的扩容机制有显著差异(头插法 vs 尾插法),考察你是否了解这些变化以及背后的原因(死循环问题)。
核心答案
HashMap 的扩容机制可以概括为:当元素数量超过 容量 × 负载因子 时,容量翻倍,并重新分配所有元素。
| 关键点 | 说明 |
|---|---|
| 默认初始容量 | 16 |
| 默认负载因子 | 0.75 |
| 扩容阈值 | capacity × loadFactor(首次为 12 = 16 × 0.75) |
| 扩容方式 | 容量翻倍(newCap = oldCap << 1) |
| 触发条件 | size > threshold 且当前桶位置非空 |
| 元素重分布 | 根据新增的最高位判断:原位置 或 原位置 + 原容量 |
深度解析
一、扩容触发时机
扩容发生在调用 putVal() 方法插入元素后,满足以下两个条件时触发:
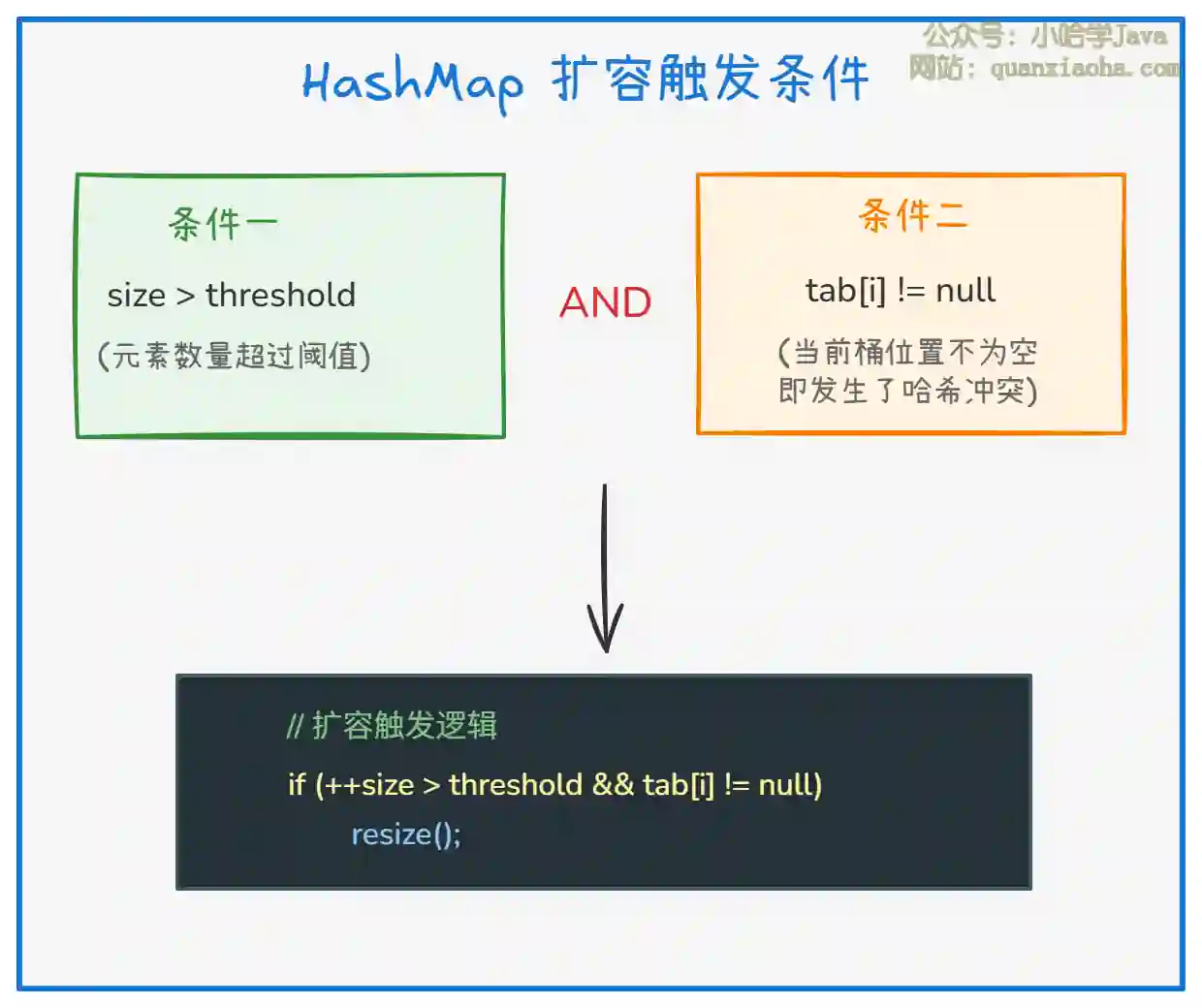
上图展示了扩容的两个必要条件。这里有几个关键点需要理解:
-
为什么需要两个条件? 这是一个性能优化。如果当前桶为空,直接放入即可,不需要立即扩容。只有当发生哈希冲突时,才考虑扩容以减少冲突概率。
-
threshold 的计算:
threshold = capacity × loadFactor。默认情况下,首次扩容阈值为 12(16 × 0.75)。 -
负载因子为什么是 0.75? 这是时间和空间的权衡:
- 太大(如 1.0):空间利用率高,但哈希冲突多,查询效率低
- 太小(如 0.5):哈希冲突少,查询效率高,但空间浪费
- 0.75 是经过数学计算得出的平衡值,来自泊松分布
二、扩容核心流程
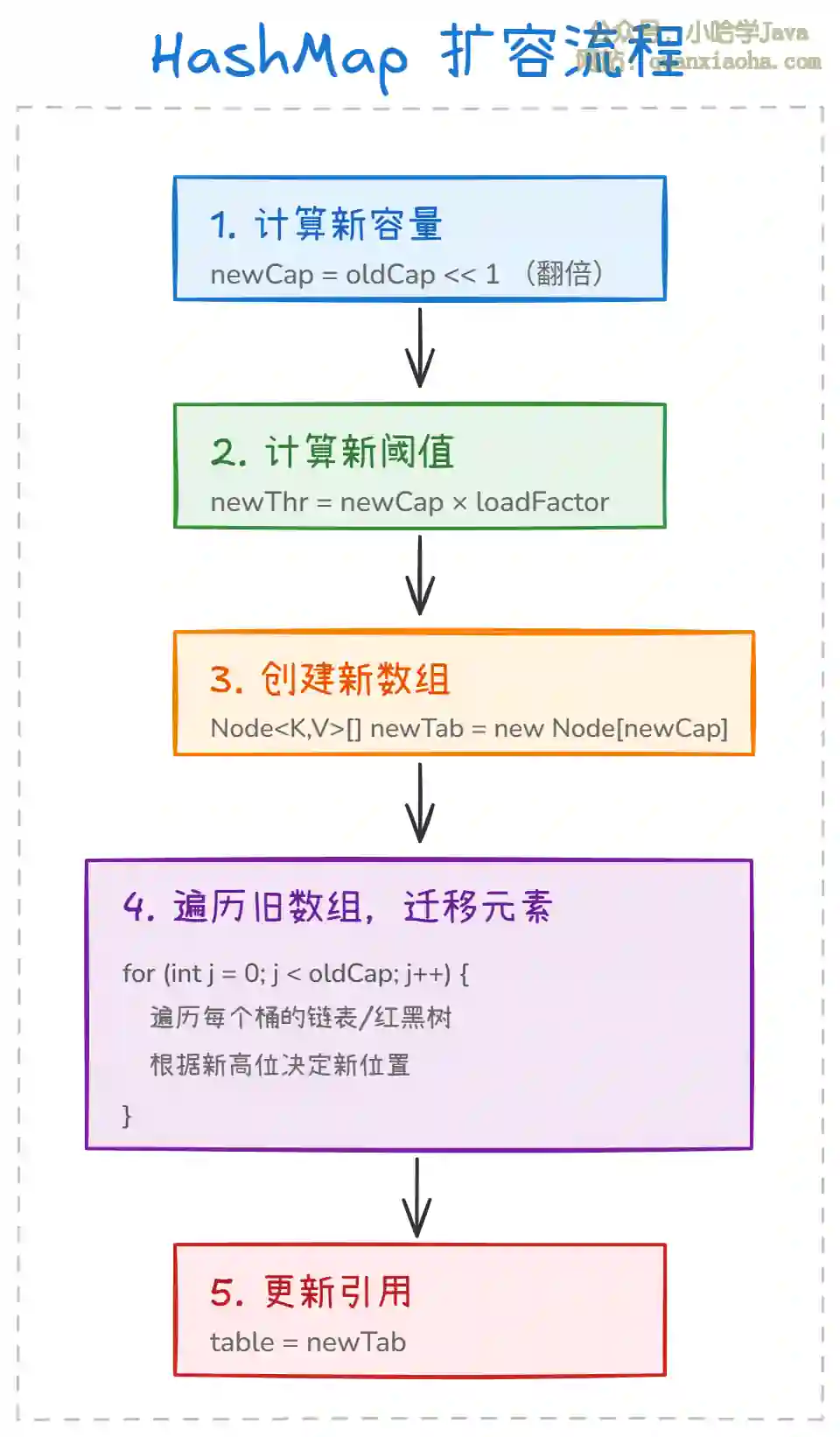
上图展示了 HashMap 扩容的完整流程。整个过程分为 5 个关键步骤:
-
步骤一 - 计算新容量:使用位运算
oldCap << 1实现翻倍,效率极高。容量始终保持 2 的幂次方,这是为了让(n - 1) & hash能够均匀分布。 -
步骤二 - 计算新阈值:新阈值也需要翻倍,保持负载因子的约束。
-
步骤三 - 创建新数组:在堆中分配一个新的
Node数组,大小为新容量。 -
步骤四 - 迁移元素:这是最核心的步骤,需要遍历旧数组的每个桶,将链表或红黑树中的元素重新分配到新数组中。
-
步骤五 - 更新引用:将
table指向新数组,完成扩容。
三、元素重分布原理(核心!)
这是面试中最重要的考点。JDK 1.8 中,扩容后元素的位置分布有一个巧妙的规律:
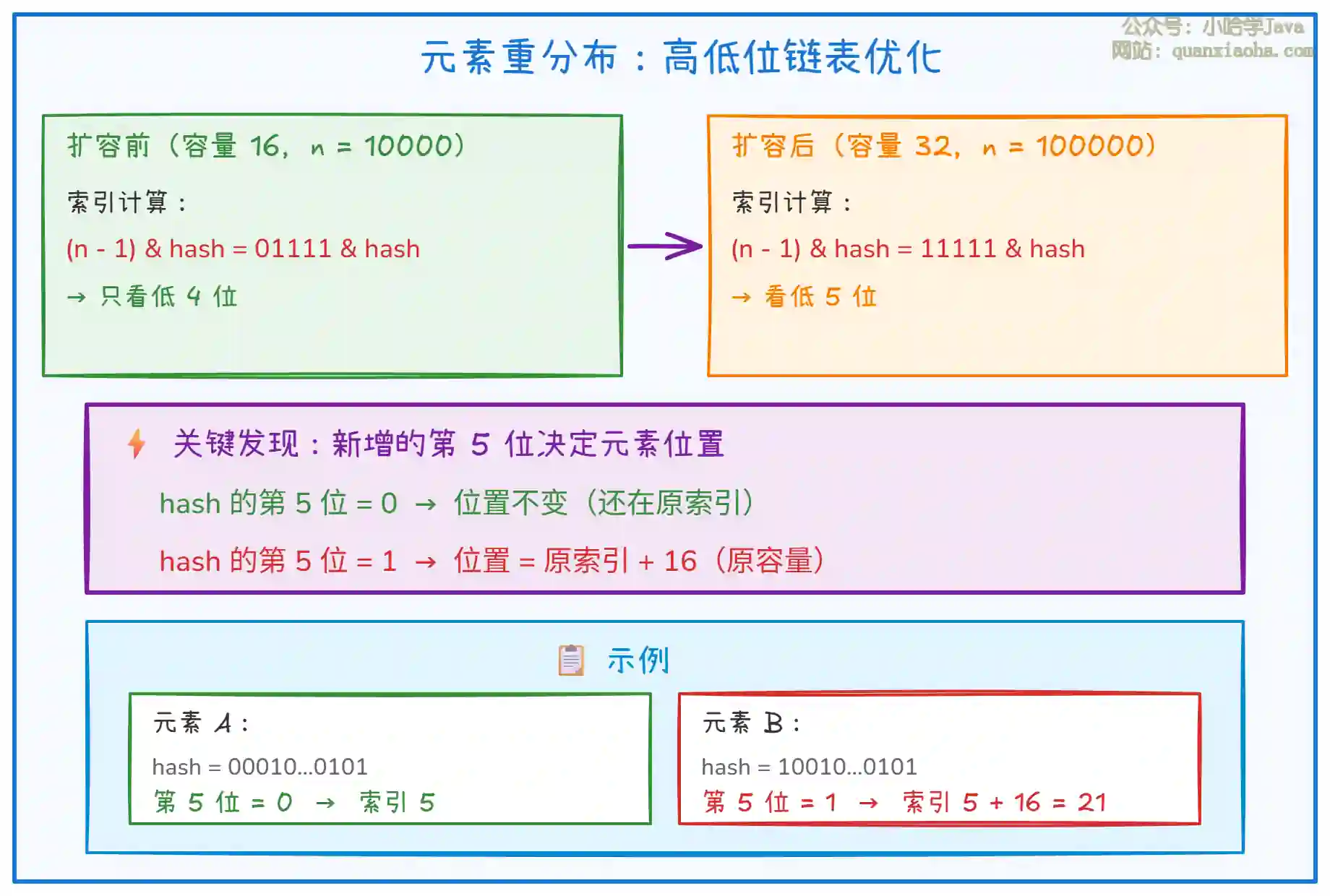
上图揭示了 JDK 1.8 扩容的核心优化。让我详细解释这个精妙的设计:
-
为什么是两种可能? 因为容量从 2^n 变成 2^(n+1),掩码只多了一位。这一位要么是 0,要么是 1,所以元素的新位置只有两种可能。
-
低位链表(loHead/loTail):第 n 位为 0 的元素,扩容后索引不变,组成 "低位链表"。
-
高位链表(hiHead/hiTail):第 n 位为 1 的元素,扩容后索引 = 原索引 + 原容量,组成 "高位链表"。
-
为什么用
(e.hash & oldCap) == 0判断? 这里不是用n-1,而是直接用oldCap(如 16 = 10000)。只有 hash 的第 5 位为 0 时,hash & 16才等于 0。
四、源码核心片段
// JDK 1.8 resize() 方法核心逻辑
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// 1. 计算新容量和新阈值
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) { // 已达最大容量,不再扩容
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && // 容量翻倍
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // 阈值翻倍
}
// ... 省略其他分支
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 2. 遍历旧数组,迁移元素
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null; // 帮助 GC
if (e.next == null)
// 单个节点,直接计算新位置
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 红黑树拆分
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// 3. 链表拆分:高低位链表
Node<K,V> loHead = null, loTail = null; // 低位链表
Node<K,V> hiHead = null, hiTail = null; // 高位链表
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
// 低位:索引不变
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
// 高位:索引 = 原索引 + 原容量
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 4. 将拆分后的链表放到新数组
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead; // 低位放原位置
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead; // 高位放原位置+原容量
}
}
}
}
}
return newTab;
}
五、JDK 1.7 vs JDK 1.8 扩容对比
| 对比项 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 链表插入方式 | 头插法 | 尾插法 |
| 扩容后顺序 | 链表元素顺序反转 | 链表元素顺序保持不变 |
| 元素位置计算 | 重新计算 h & (length-1) |
高低位链表优化,无需重新计算 |
| 并发问题 | 多线程扩容可能导致死循环 | 死循环问题已解决 |
| 红黑树 | 无 | 链表 ≥ 8 且容量 ≥ 64 时转红黑树 |
JDK 1.7 死循环问题原因:

上图解释了 JDK 1.7 的经典死循环问题。关键点:
- 头插法:新元素总是插到链表头部
- 并发场景:两个线程同时扩容,一个暂停,另一个完成
- 顺序反转:线程 2 完成后,链表顺序从 A→B 变成 B→A
- 形成环:线程 1 继续执行时,基于旧的 next 指针操作,导致 A 和 B 互指
- JDK 1.8 解决:改用尾插法,顺序保持不变,避免了这个问题
面试高频追问
-
为什么容量必须是 2 的幂次方?
- 让
(n - 1) & hash等价于hash % n,位运算效率更高 - 保证散列均匀,避免空间浪费
- 让
-
扩容时每个元素都需要重新计算 hash 吗?
- 不需要!只需判断新增的高位是 0 还是 1,用
(e.hash & oldCap) == 0即可
- 不需要!只需判断新增的高位是 0 还是 1,用
-
HashMap 是线程安全的吗?扩容时会有什么问题?
- 不是线程安全的。JDK 1.7 并发扩容可能死循环,JDK 1.8 可能数据丢失
- 推荐使用
ConcurrentHashMap
-
负载因子可以修改吗?什么场景需要调整?
- 可以,构造函数可指定
loadFactor - 内存紧张时可调高(如 0.85),查询频繁时可调低(如 0.5)
- 可以,构造函数可指定
常见面试变体
- "HashMap 的负载因子为什么是 0.75?"
- "JDK 1.7 和 1.8 的 HashMap 扩容有什么区别?"
- "为什么 JDK 1.8 改用尾插法?解决了什么问题?"
- "扩容时元素如何重新分配?为什么只有两种可能?"
记忆口诀
扩容三要素:容量翻倍、阈值翻倍、高低位分家
位置判断:新位为 0 留原地,新位为 1 加原容((hash & oldCap) == 0 → 低位链表,否则高位链表)
总结
HashMap 扩容在 size > threshold 时触发,容量翻倍(<< 1),使用高低位链表优化元素重分布——根据 hash 新增位的值,元素要么留在原位置,要么移动到 "原位置 + 原容量"。JDK 1.8 改用尾插法解决了 JDK 1.7 并发扩容的死循环问题。记住:负载因子 0.75、容量 2 的幂、高低位分家。