Redis 事务和 Lua 脚本的区别是什么?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅是想知道
MULTI/EXEC和EVAL的语法区别,更是想知道你是否清楚 Redis 事务的本质(命令排队、不支持回滚)以及 Lua 脚本的原子性保证。 -
原理理解深度:考察你是否知道 Redis 事务在执行过程中某条命令失败 不会回滚 已执行的命令,以及 Lua 脚本为什么能保证原子性(单线程执行)。
-
方案选型能力:能否在 "事务"、"Lua 脚本"、"Pipeline" 三者之间做出正确区分,并在实际业务中选择合适的方案。
核心答案
| 对比维度 | Redis 事务(MULTI/EXEC) |
Lua 脚本(EVAL) |
|---|---|---|
| 原子性 | ✅ 命令排队一次性执行,中间不被打断 | ✅ 整个脚本原子执行 |
| 逻辑控制 | ❌ 不支持条件判断和循环 | ✅ 完整的编程语言(if/for/while) |
| 命令失败行为 | ❌ 某条命令失败不回滚,继续执行后续命令 | ❌ 运行时错误不回滚,但会 立即中断脚本 |
| 读取中间结果 | ❌ 事务中无法读取上一条命令的结果 | ✅ 可以读取中间结果做条件判断 |
| 性能 | 一次性发送多条命令,减少 RTT | 一次发送脚本,减少 RTT |
| 复杂度 | 简单,适合 2~3 条命令 | 可编写复杂业务逻辑 |
一句话结论:简单场景用 事务,需要条件判断或读取中间结果用 Lua 脚本。生产环境优先选择 Lua 脚本,因为它既保证原子性又支持复杂逻辑。
深度解析
一、Redis 事务机制
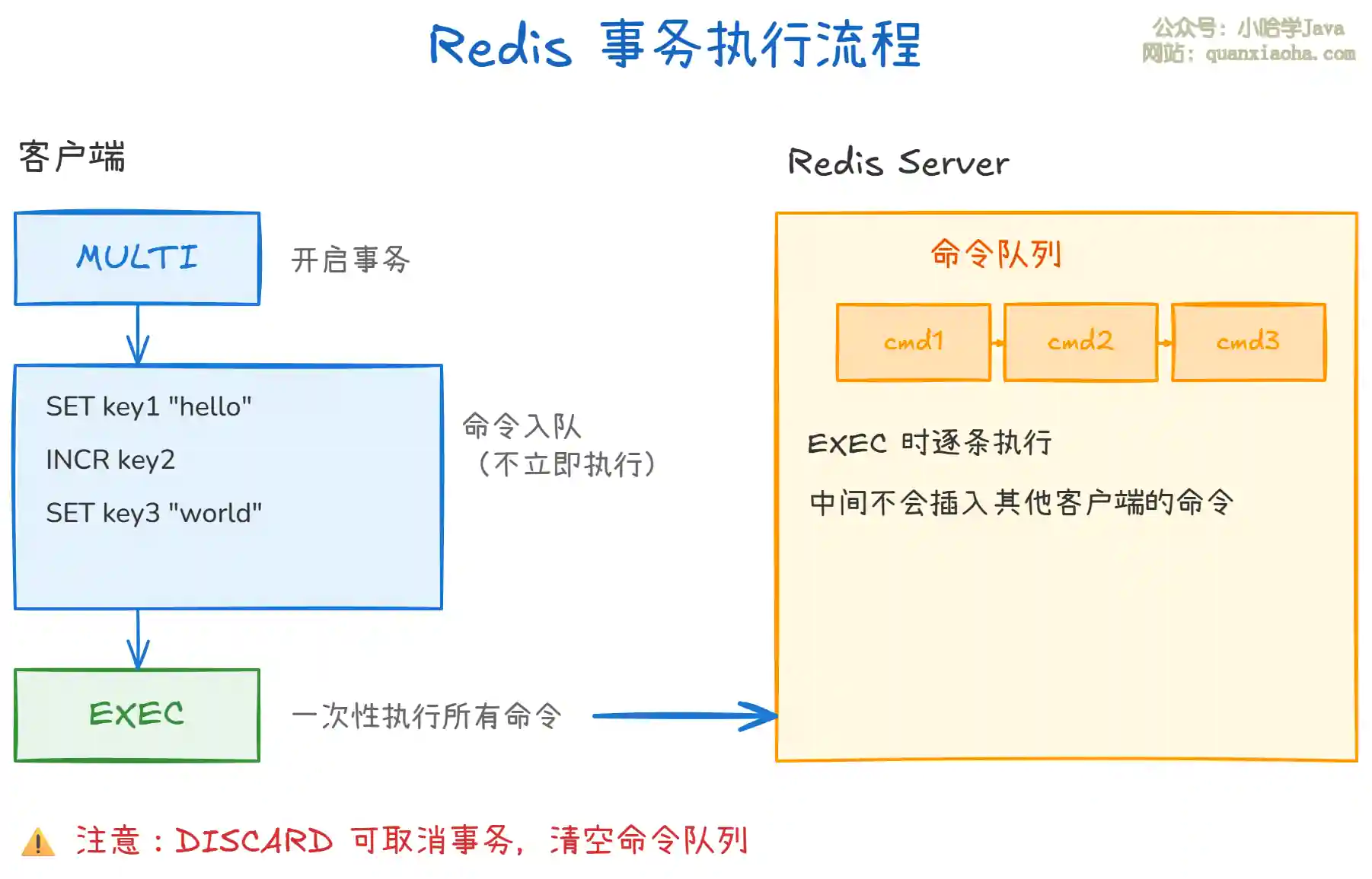
上图展示了 Redis 事务的基本流程:
MULTI:标记事务开始,之后的所有命令不会立即执行,而是进入一个 命令队列。- 命令入队:后续的写命令依次进入队列,Redis 返回
QUEUED表示入队成功。 EXEC:一次性执行队列中的所有命令。在EXEC执行期间,Redis 不会插入其他客户端的命令。DISCARD:取消事务,清空命令队列,放弃执行。
二、Redis 事务的致命缺陷:不支持回滚
这是面试中最常被追问的点。Redis 事务 不是数据库意义上的 ACID 事务。

上图展示了 Redis 事务不支持回滚的核心问题:
- 在事务执行过程中,如果某条命令失败了(比如对字符串执行
INCR),已执行的命令不会回滚,后续命令也会继续执行。 - Redis 官方认为,命令失败通常是因为 编程错误(类型错误、语法错误),应该在开发阶段就被发现,不需要运行时的回滚机制。这种设计哲学使得 Redis 保持简单高效。
Redis 事务还有另一个局限:无法读取中间结果。
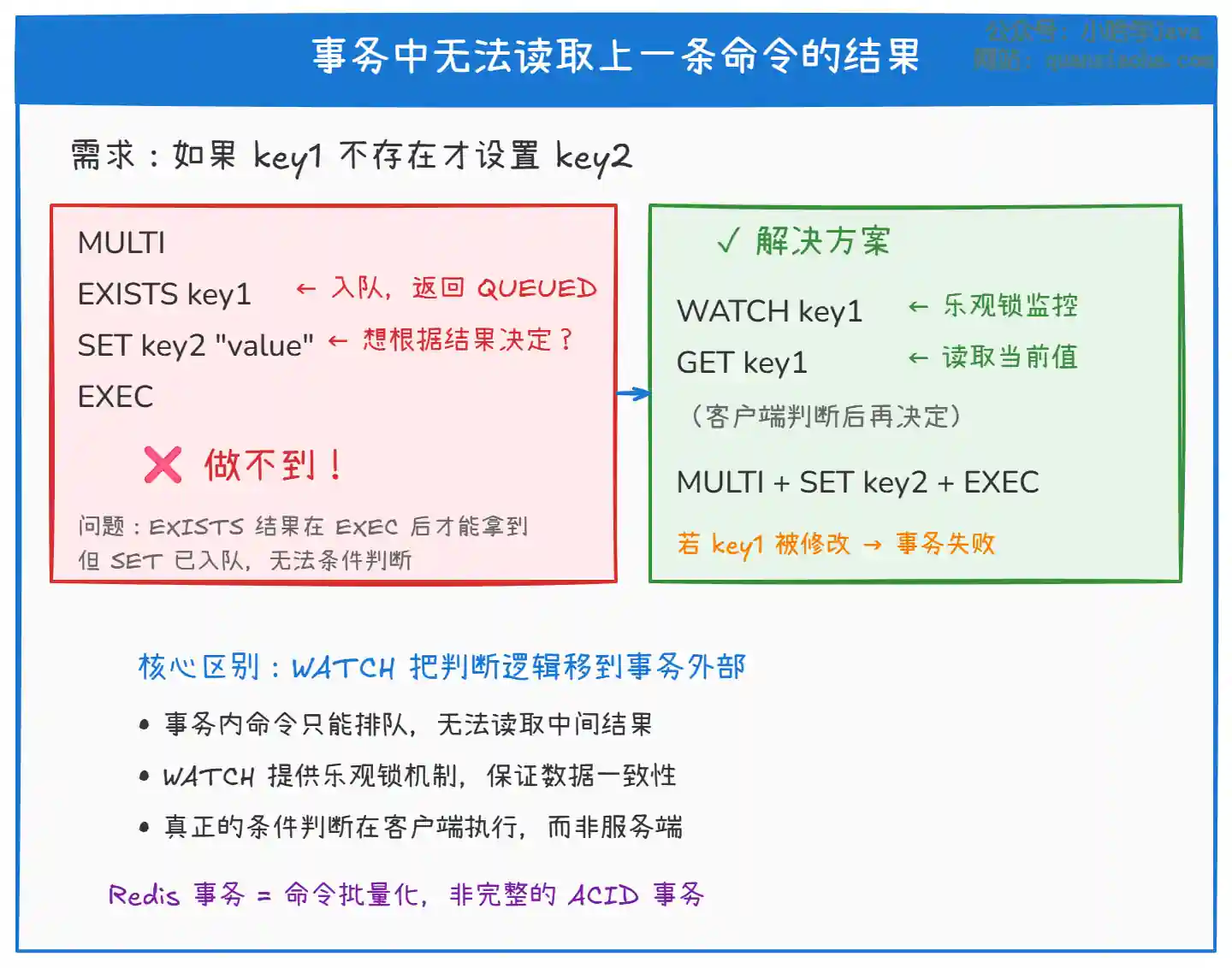
上图展示了 Redis 事务中无法读取中间结果的问题:
- 事务中的所有命令在
EXEC之前只是入队,不会执行。所以你无法在事务中根据上一条命令的结果来决定下一条命令怎么写。 WATCH可以实现 乐观锁:在事务开启前监控某个 Key,如果这个 Key 在事务执行前被其他客户端修改了,整个事务会自动失败。但这仍然无法实现 "根据条件动态决定执行哪些命令"。
三、Lua 脚本:更强大的原子操作方案
Lua 脚本可以完美解决事务无法读取中间结果的问题。
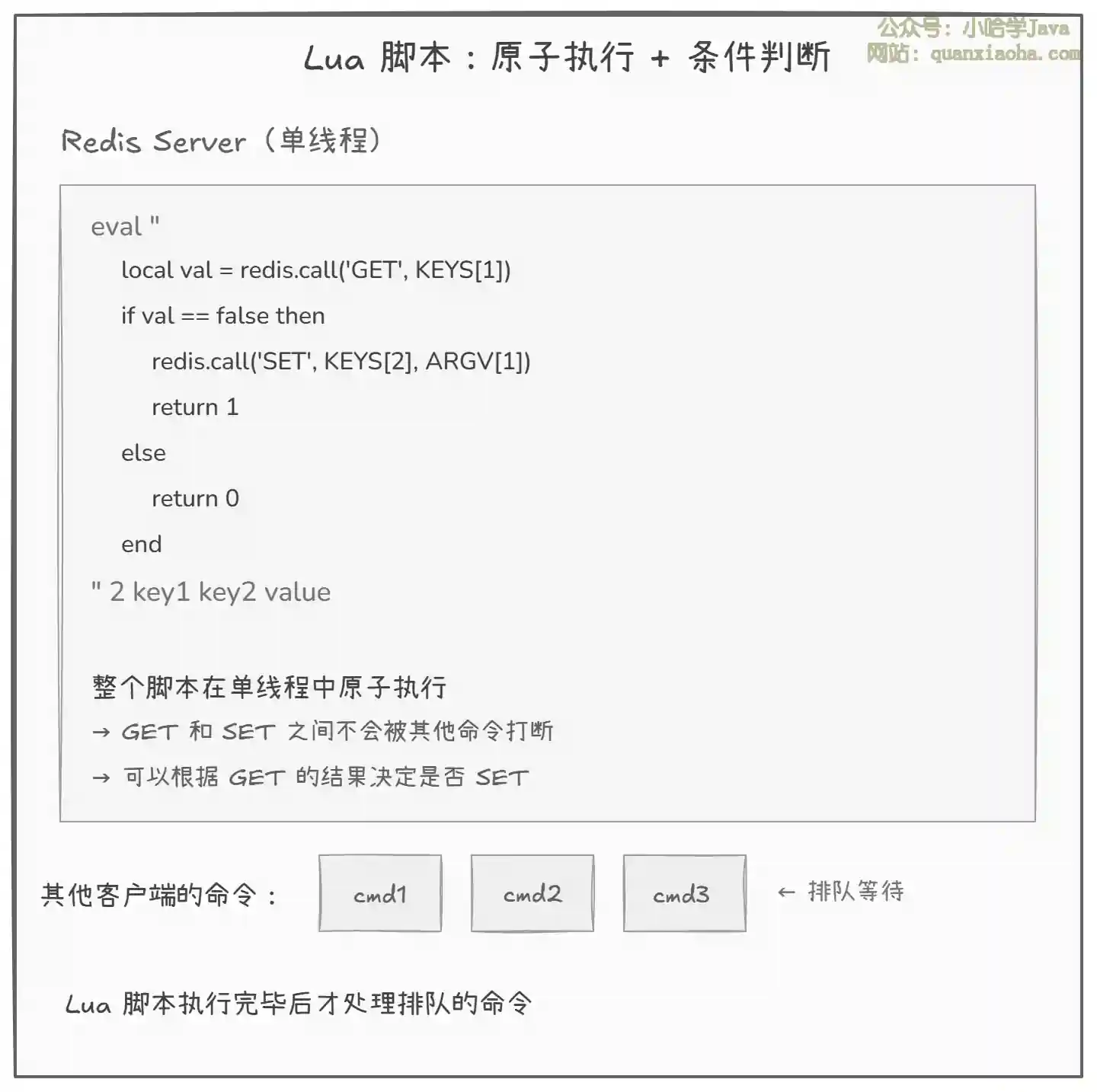
上图展示了 Lua 脚本的执行机制:
- Redis 使用 单线程 处理命令。当执行 Lua 脚本时,整个脚本在单线程中 原子执行,不会被其他客户端的命令打断。
- 脚本内部可以 读取中间结果,根据条件决定后续操作,这是事务做不到的。
- 其他客户端的命令在脚本执行期间排队等待,脚本执行完毕后才逐条处理。
Lua 脚本常用语法速查:
-- 1. 调用 Redis 命令
redis.call('SET', 'key', 'value')
local val = redis.call('GET', 'key')
-- 2. 条件判断
if val == false then
redis.call('SET', 'key', 'default')
end
-- 3. 循环
for i = 1, #KEYS do
redis.call('DEL', KEYS[i])
end
-- 4. 返回值
return val
-- 5. 日志调试(开发时用)
redis.log(redis.LOG_WARNING, "debug message")
Java 中使用 Lua 脚本的示例:
// 分布式锁的原子释放
String luaScript =
"if redis.call('get', KEYS[1]) == ARGV[1] then " +
" return redis.call('del', KEYS[1]) " +
"else " +
" return 0 " +
"end";
Long result = (Long) jedis.eval(
luaScript,
Collections.singletonList("lock"), // KEYS
Collections.singletonList(lockValue) // ARGV
);
if (result == 1L) {
System.out.println("释放锁成功");
}
四、Pipeline 又是什么?别搞混了
面试时经常把 Pipeline 和事务搞混,需要区分清楚。
| 对比维度 | Pipeline | 事务(MULTI/EXEC) | Lua 脚本 |
|---|---|---|---|
| 网络优化 | ✅ 多条命令一次性发送 | ✅ 一次性发送 | ✅ 一次发送脚本 |
| 原子性 | ❌ 各命令独立执行 | ✅ 命令排队原子执行 | ✅ 脚本整体原子执行 |
| 条件判断 | ❌ 不支持 | ❌ 不支持 | ✅ 支持 |
| 中间结果 | ✅ 客户端可拿到 | ❌ 事务中拿不到 | ✅ 脚本内可读取 |
| 适用场景 | 批量操作、减少 RTT | 简单原子操作 | 复杂原子操作 |
- Pipeline:纯粹为了 减少网络往返(RTT),把多条命令打包一次性发送。各命令独立执行,不保证原子性。适合批量
SET、批量GET等场景。 - 事务:保证命令的 原子执行(中间不被打断),但不支持回滚和条件判断。
- Lua 脚本:既保证原子性,又支持条件判断和读取中间结果,是最灵活的方案。
五、Lua 脚本的注意事项
Lua 脚本虽然强大,但生产使用时需要注意以下几点:
- 执行时间不能太长:Lua 脚本在 Redis 主线程中执行,长时间运行会阻塞所有客户端。Redis 默认限制脚本执行时间为 5 秒(
lua-time-limit),超时后其他客户端可以接受请求但仍需等待脚本结束。 - 脚本缓存:Redis 会缓存 Lua 脚本的 SHA1 摘要。可以用
EVALSHA代替EVAL,只发送 SHA1 而不是整个脚本,减少网络传输。 - ⚠️ 不保证回滚(极其重要!):Lua 脚本中
redis.call()调用的命令如果发生运行时错误(比如对字符串执行INCR),脚本会 立即中断并返回错误,后续命令不再执行。但中断前已经成功执行的命令 不会被撤销。也就是说,Lua 脚本既没有事务的ROLLBACK语义,也不像 Java 中异常回滚那样自动恢复状态。举个例子:脚本先SET key1 val1成功,再INCR key1失败,此时脚本立即中断,key1 的值已经被修改为val1了,但不会恢复到脚本执行前的状态。所以 务必在脚本内部做好参数校验和错误处理,确保业务逻辑的正确性。 - 集群兼容性:Redis Cluster 中,Lua 脚本操作的所有 Key 必须在 同一个 slot 上,否则会报错。可以使用
{hash_tag}强制 Key 路由到同一 slot。
面试高频追问
-
追问一:Redis 事务支持回滚吗?为什么不支持?
不支持。Redis 官方的态度是:命令失败通常是 编程错误(比如对字符串执行
INCR),这类错误应该在开发测试阶段就被发现并修复,而不是在运行时通过回滚来处理。去掉回滚机制使得 Redis 的实现更简单、性能更高。如果你需要回滚能力,应该使用关系型数据库。 -
追问二:
WATCH命令是什么?解决了什么问题?WATCH是 Redis 的 乐观锁 机制。在事务开启前用WATCH监控一个或多个 Key,如果在EXEC执行前这些 Key 被其他客户端修改了,整个事务会自动取消(返回 nil)。它解决了 "读-改-写" 竞态条件的问题。但WATCH只能保证事务不被并发修改,无法实现条件判断式的动态操作。 -
追问三:生产环境中 Lua 脚本和事务怎么选?
- 2~3 条简单命令,不需要条件判断 → 用事务(
MULTI/EXEC),简单直观。 - 需要根据中间结果做判断(如分布式锁的判断 + 删除)→ 用 Lua 脚本。
- 只是批量操作减少网络开销 → 用 Pipeline。
- 生产环境的大部分原子操作场景,Lua 脚本是首选方案。
- 2~3 条简单命令,不需要条件判断 → 用事务(
常见面试变体
- 变体一:"Redis 事务和 MySQL 事务有什么区别?"
- 变体二:"Redis Lua 脚本为什么是原子的?"
- 变体三:"Redis Pipeline 和事务的区别?"
- 变体四:"如何在 Redis 中实现 CAS(Compare-And-Swap)?"
记忆口诀
事务:排队执行,不回滚,不读中间结果 —— "排队买票,不许反悔,不许看前面的人买了啥"。
Lua 脚本:原子执行 + 条件判断 + 读中间结果 —— "一个人包场,想看啥看啥,想买啥买啥"。
Pipeline:只管打包发送,不管原子性 —— "快递打包,一次寄出,各走各的"。
选型:简单排队用事务,复杂逻辑用 Lua,批量操作用 Pipeline。
总结
Redis 事务(MULTI/EXEC)和 Lua 脚本都能保证命令的原子执行,但事务 不支持回滚、无法读取中间结果、不支持条件判断。Lua 脚本在单线程模型下原子执行,支持完整的编程逻辑(条件、循环、读取中间结果),是更灵活强大的方案。生产环境推荐优先使用 Lua 脚本处理需要原子性的复杂操作,Pipeline 用于纯批量操作减少网络开销。