MyBatis 如何执行批量操作?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
方案掌握度:面试官不仅仅是想知道你 "会用 foreach",更是想考察你是否了解 MyBatis 中批量操作的多种实现方式,以及各自的性能差异和适用场景。
-
性能优化意识:批量操作是高频场景,面试官想看你是否知道
<foreach>拼接 SQL 的长度限制问题,以及BatchExecutor的底层原理。 -
生产实践:看你能否结合实际经验,说出如何选择合适的批量方案,以及分片、事务控制等生产级注意事项。
核心答案
MyBatis 执行批量操作主要有 3 种方式:
| 方式 | 原理 | 性能 | 适用场景 |
|---|---|---|---|
<foreach> 拼接 SQL |
一条 SQL 插入多行数据 | ⭐⭐⭐ 高 | 数据量适中(几百到几千条) |
BatchExecutor |
JDBC addBatch + executeBatch |
⭐⭐ 中高 | 大批量数据(万级以上) |
循环 + SqlSession 批处理 |
手动控制批量提交 | ⭐⭐ 中高 | 需要精细控制提交时机 |
一句话结论:少量数据用 <foreach> 最简单高效,大量数据用 BatchExecutor 更稳妥,注意分片和事务控制。
深度解析
一、方式一:<foreach> 拼接 SQL(最常用)
通过 <foreach> 标签将多条数据拼接到一条 SQL 中,一次性发送给数据库执行:
<!-- 批量插入 -->
<insert id="batchInsert">
INSERT INTO t_user (username, email, status)
VALUES
<foreach collection="users" item="user" separator=",">
(#{user.username}, #{user.email}, #{user.status})
</foreach>
</insert>
<!-- 批量更新(CASE WHEN 方式) -->
<update id="batchUpdate">
UPDATE t_user
SET username =
<foreach collection="users" item="user" open="CASE id" close="END">
WHEN #{user.id} THEN #{user.username}
</foreach>
WHERE id IN
<foreach collection="users" item="user" open="(" separator="," close=")">
#{user.id}
</foreach>
</update>
<!-- 批量删除 -->
<delete id="batchDelete">
DELETE FROM t_user
WHERE id IN
<foreach collection="ids" item="id" open="(" separator="," close=")">
#{id}
</foreach>
</delete>
生成的 SQL 示例:
-- 批量插入:一条 SQL 搞定
INSERT INTO t_user (username, email, status)
VALUES ('张三', 'a@qq.com', 1), ('李四', 'b@qq.com', 1), ('王五', 'c@qq.com', 1);
优点:SQL 简单直观,网络开销小(只发一条 SQL),数据库执行效率高。
致命问题——SQL 长度限制:
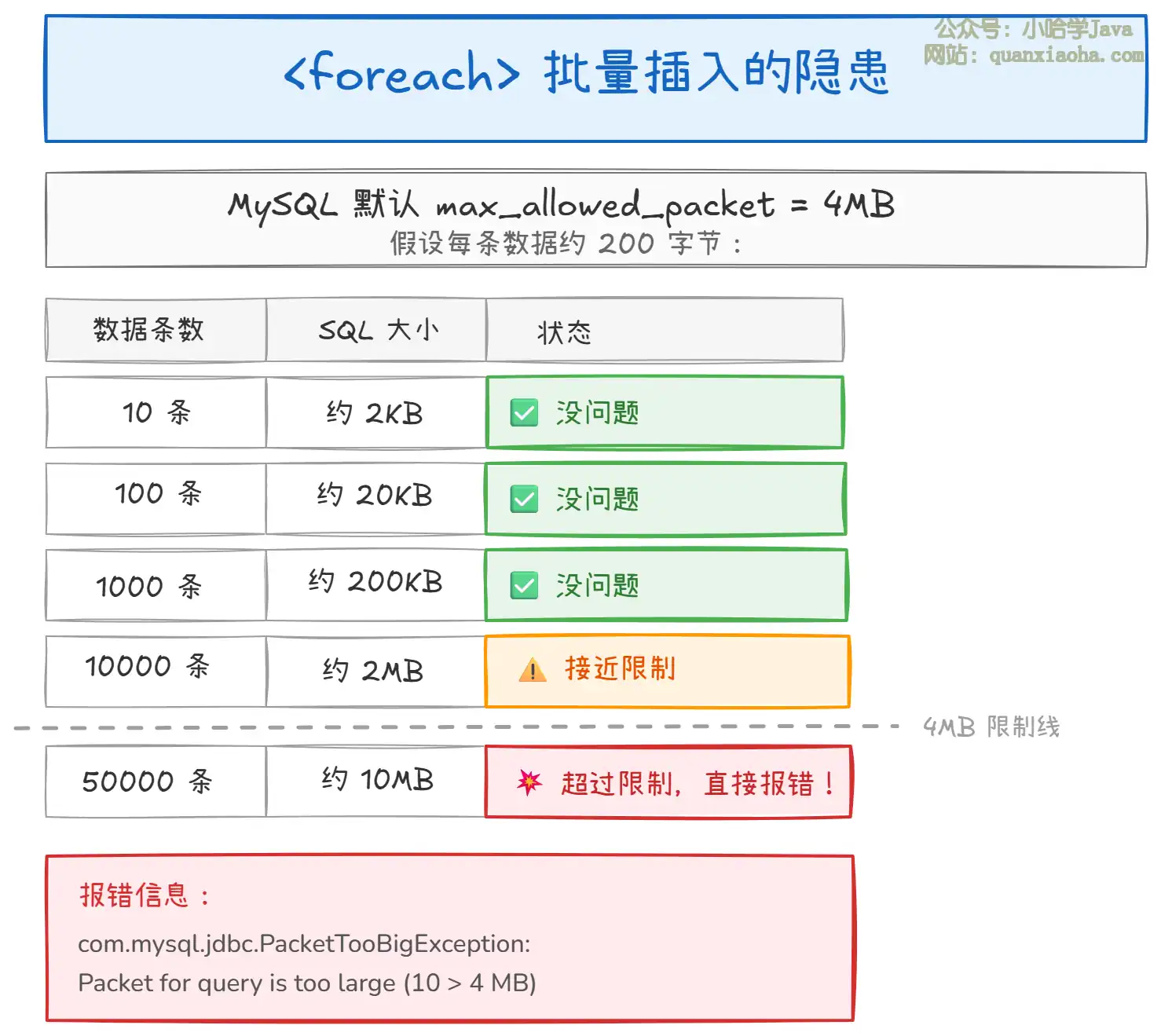
MySQL 的 max_allowed_packet 参数限制了单个 SQL 包的大小(默认 4MB)。当 <foreach> 拼接的数据量过大时,生成的 SQL 会超过这个限制导致报错。
解决方案——分片执行:
// 分片批量插入:每 1000 条执行一次
private static final int BATCH_SIZE = 1000;
public void batchInsert(List<User> users) {
// 使用 List.subList 分片
for (int i = 0; i < users.size(); i += BATCH_SIZE) {
int end = Math.min(i + BATCH_SIZE, users.size());
List<User> subList = users.subList(i, end);
userMapper.batchInsert(subList);
}
}
二、方式二:BatchExecutor(推荐大批量场景)
MyBatis 内置了 BatchExecutor,底层使用 JDBC 的 addBatch() + executeBatch() 机制:
// 方式一:通过 SqlSessionFactory 创建批量 SqlSession
SqlSession batchSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
try {
UserMapper mapper = batchSession.getMapper(UserMapper.class);
for (User user : userList) {
mapper.insert(user);
// 注意:此时 SQL 并没有真正执行,只是添加到批次中
}
// 统一执行所有批次中的 SQL
batchSession.commit(); // 提交(内部调用 executeBatch)
batchSession.flushStatements(); // 或者手动刷盘
} finally {
batchSession.close();
}
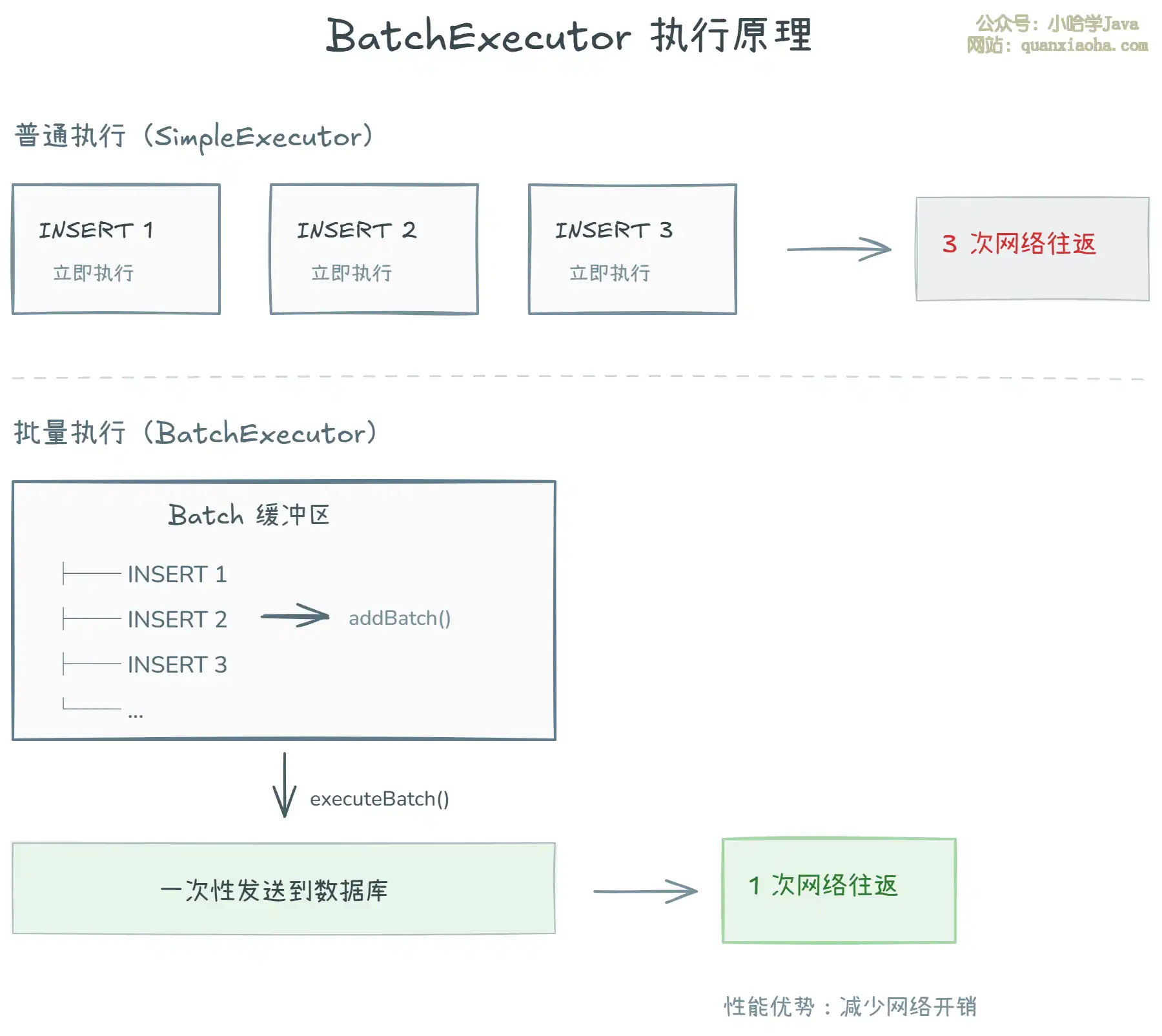
两种执行器的核心差异在于网络交互方式:
SimpleExecutor:每次调用insert()方法,就立即向数据库发送一条 SQL 并执行。插入 1000 条数据,就有 1000 次网络往返。BatchExecutor:每次调用insert()方法,只是通过addBatch()将 SQL 添加到 JDBC 的批次缓冲区中,并不立即执行。调用commit()或flushStatements()时,才通过executeBatch()一次性将所有 SQL 发送到数据库执行。1000 条数据只需要 1 次网络往返。
注意:BatchExecutor 默认会在内存中缓存所有 PreparedStatement,如果数据量特别大(几十万条),需要分批刷盘:
SqlSession batchSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
try {
UserMapper mapper = batchSession.getMapper(UserMapper.class);
for (int i = 0; i < users.size(); i++) {
mapper.insert(users.get(i));
// 每 1000 条刷盘一次,防止内存溢出
if ((i + 1) % 1000 == 0) {
batchSession.flushStatements();
batchSession.clearCache();
}
}
// 最后刷盘剩余数据
batchSession.flushStatements();
batchSession.commit();
} finally {
batchSession.close();
}
三、方式三:Spring 整合中的批量操作
在 Spring 整合环境下,可以使用 SqlSessionTemplate 配合批量执行:
// 注入批量 SqlSessionTemplate
@Autowired
@Qualifier("batchSqlSessionTemplate")
private SqlSession batchSqlSession;
public void batchInsert(List<User> users) {
try {
UserMapper mapper = batchSqlSession.getMapper(UserMapper.class);
for (User user : users) {
mapper.insert(user);
}
batchSqlSession.flushStatements();
} finally {
// SqlSessionTemplate 会自动关闭
}
}
// 批量 SqlSessionTemplate 的配置
@Configuration
public class MyBatisBatchConfig {
@Bean("batchSqlSessionTemplate")
public SqlSessionTemplate batchSqlSessionTemplate(SqlSessionFactory sqlSessionFactory) {
// 使用 BATCH 类型的 Executor
return new SqlSessionTemplate(sqlSessionFactory, ExecutorType.BATCH);
}
}
四、MyBatis-Plus 的批量操作(加分项)
如果项目使用了 MyBatis-Plus,批量操作更简单:
// MyBatis-Plus 批量插入
userService.saveBatch(userList, 1000); // 每 1000 条执行一次
// MyBatis-Plus 批量更新
userService.updateBatchById(userList, 1000);
MyBatis-Plus 的 saveBatch() 底层实际使用的是 SqlSession 的 BATCH 模式 + 分片提交,还支持配置 rewriteBatchedStatements=true 让 MySQL 驱动将多条 INSERT 重写为一条多值 INSERT,性能接近 <foreach> 方式。
五、三种方式对比总结
| 对比维度 | <foreach> |
BatchExecutor |
MyBatis-Plus |
|---|---|---|---|
| SQL 形式 | 一条多值 INSERT | 多条单值 INSERT | 取决于配置 |
| 网络开销 | 最小(1 次) | 小(1 次批量提交) | 小 |
| 内存占用 | SQL 字符串可能很长 | 缓存 Statement | 自动分片 |
| 数据量限制 | 受 max_allowed_packet 限制 |
理论无限制 | 自动分片 |
| 代码复杂度 | 低 | 中 | 最低 |
| 性能 | ⭐⭐⭐ | ⭐⭐(可优化到 ⭐⭐⭐) | ⭐⭐⭐ |
| 推荐场景 | 数据量 ≤ 5000 | 数据量 > 5000 | 使用 MP 的项目 |
六、常见误区
- 误区一:"
<foreach>插入 10 万条数据没问题"- 大概率会报错。10 万条数据生成的 SQL 可能超过 20MB,远超 MySQL 默认的 4MB 限制。必须分片执行,每批 500~1000 条。
- 误区二:"
BatchExecutor比<foreach>快"- 不一定。
BatchExecutor底层是多次INSERT INTO ... VALUES (...)单条插入,而<foreach>是一条INSERT INTO ... VALUES (...), (...), (...)多值插入。默认情况下<foreach>更快。但 MySQL 连接 URL 加上rewriteBatchedStatements=true后,驱动会将BatchExecutor的多条 INSERT 重写为多值 INSERT,性能就差不多了。
- 不一定。
- 误区三:"批量操作不需要事务"
- 批量操作必须在事务中执行。如果不在事务中,每条 INSERT 都是自动提交的,一条失败不会回滚前面的,导致数据不一致。
面试高频追问
- 追问一:MySQL 的
rewriteBatchedStatements=true有什么作用?- 这个参数让 MySQL JDBC 驱动在调用
executeBatch()时,将多条INSERT INTO ... VALUES (...)重写为一条INSERT INTO ... VALUES (...), (...), (...)的多值 INSERT,大幅提升批量插入性能。对于UPDATE语句,会将多条合并为一条多CASE WHEN的更新。
- 这个参数让 MySQL JDBC 驱动在调用
- 追问二:批量更新怎么做最高效?
- 取决于场景。少量数据用
<foreach>+CASE WHEN方式(一条 SQL 搞定);大量数据用BatchExecutor+rewriteBatchedStatements=true。如果是全字段更新,也可以先删后插。
- 取决于场景。少量数据用
- 追问三:批量操作中部分失败怎么办?
- 在同一个事务中,任何一条失败都会回滚整个批次。如果需要 "成功几条算几条",需要手动捕获异常,按条提交或使用分片策略(每片独立事务)。
常见面试变体
- 变体一:"MyBatis 批量插入有几种方式?哪种性能最好?"
- 变体二:"
<foreach>拼接的 SQL 太长怎么办?" - 变体三:"MyBatis 的
BatchExecutor和SimpleExecutor有什么区别?"
记忆口诀
foreach 拼接最常用,注意 SQL 长度要分片;BatchExecutor 缓冲提交,rewriteBatchedStatements 加速;少量用 foreach,大量用 Batch,分片 + 事务保安全。
总结
MyBatis 批量操作有三种主要方式:<foreach> 拼接 SQL(适合少量数据)、BatchExecutor(适合大量数据)、MyBatis-Plus saveBatch(最省心)。<foreach> 要注意 SQL 长度限制,必须分片执行;BatchExecutor 配合 rewriteBatchedStatements=true 可以获得接近多值 INSERT 的性能。无论哪种方式,都必须在事务中执行。