RabbitMQ 如何实现消费端限流?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
QoS 机制:知不知道
basic.qos和prefetchCount是什么,怎么控制消费端的消息推送速率。 -
手动 ACK 配合:限流不是光设个参数就完事,得配合手动 ACK 才能生效。自动 ACK 下限流形同虚设。
-
参数细节:
prefetchCount设在 Channel 级别还是 Consumer 级别,global参数在 RabbitMQ 里的特殊含义。这些细节能区分出你是用过还是背过。
核心答案
RabbitMQ 通过 basic.qos 设置 prefetchCount 来实现消费端限流。原理很直接:Broker 一次性最多给消费者推送 prefetchCount 条未经 ACK 的消息。消费者处理完一条、回一个 ACK,Broker 才会再推一条。没 ACK 的消息数达到上限,Broker 就不再推了。
前提条件:必须关闭自动 ACK,改用手动 ACK。 自动 ACK 模式下,消息一推出去就算 "已确认",prefetchCount 根本起不了作用。
| 参数 | 含义 | 典型值 |
|---|---|---|
prefetchCount |
单个消费者同时最多持有的未确认消息数 | 1~100 |
prefetchSize |
单条消息大小上限(字节),0 表示不限 | 一般设 0 |
global |
是否对整个 Channel 生效 | RabbitMQ 中有特殊语义 |
深度解析
限流的工作机制
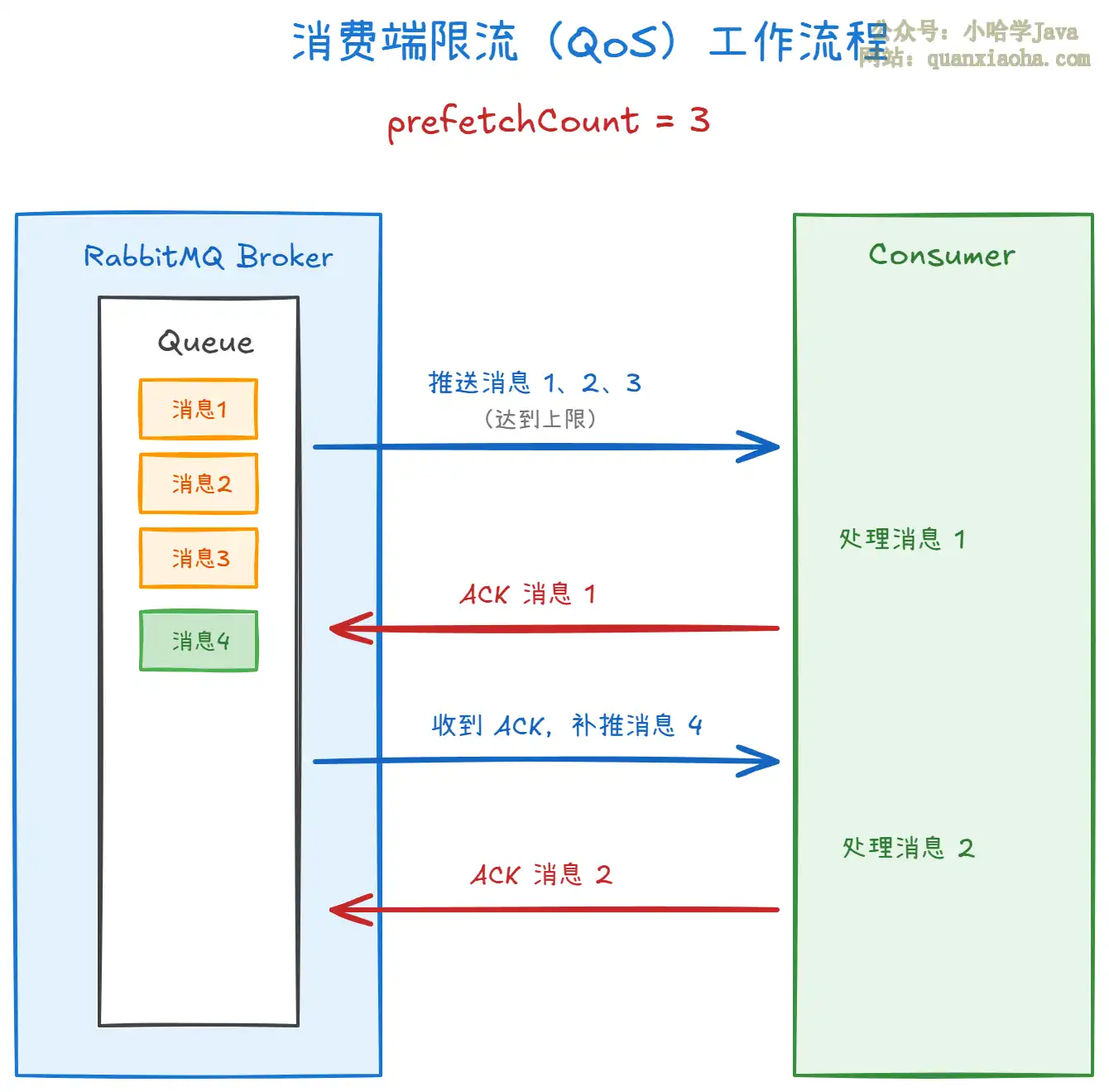
流程就是这样:
prefetchCount = 3意味着 Broker 最多同时给消费者推 3 条未确认的消息。- 消费者处理完消息 1,发一个 ACK 回去,Broker 才会补推消息 4。始终保持未确认消息数不超过 3。
- 如果消费者处理慢,ACK 回不来,Broker 就等着,不会继续推。消费者就不会被压垮。
prefetchCount 设多少合适?看业务。设太小(比如 1),吞吐量上不去;设太大,限流又没意义了。一般订单处理类业务 10~50,日志消费可以给到 100~500。生产环境建议压测调优。
代码示例
原生 RabbitMQ Java Client:
Channel channel = connection.createChannel();
// 关闭自动 ACK,第六个参数 false 表示手动确认
channel.basicConsume("order.queue", false, new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) {
try {
// 处理消息
processOrder(body);
// 手动确认
channel.basicAck(envelope.getDeliveryTag(), false);
} catch (Exception e) {
// 处理失败,拒绝并重新入队
channel.basicNack(envelope.getDeliveryTag(), false, true);
}
}
});
// 设置 QoS:prefetchCount = 10
channel.basicQos(10);
Spring Boot 配置更简单,改 application.yml:
spring:
rabbitmq:
listener:
simple:
acknowledge-mode: manual # 手动 ACK
prefetch: 10 # prefetchCount
global 参数的坑
basic.qos 有个 global 参数,很多人踩过坑。
// 只对当前 Channel 上后续新建的 Consumer 生效
channel.basicQos(10, false);
// 对整个 Channel 上所有 Consumer 生效
channel.basicQos(10, true);
但 RabbitMQ 的实现和 AMQP 协议规范不一样。在 AMQP 规范里,global = false 表示限定单个 Consumer,global = true 表示限定整个 Channel 上所有 Consumer 共享的总量。而 RabbitMQ 的实际行为是:
global 值 |
AMQP 规范含义 | RabbitMQ 实际行为 |
|---|---|---|
false |
单个 Consumer 的 prefetch | ✅ 一致,限定单个 Consumer |
true |
Channel 上所有 Consumer 共享 | ❌ 不一致,限定 Channel 上后续新建的 Consumer(独立计数) |
实际开发中,global 基本都设 false,按 Consumer 级别限流就够了。这个参数的细节面试官不一定知道,但你说出来就是加分项。
常见误区
- 误区一:以为设了
prefetchCount就万事大吉。别忘了关自动 ACK。自动 ACK 模式下消息推出去就确认了,限流根本不起作用。 - 误区二:
prefetchCount设得越大越好。设太大等于没限流,消费者还是会被压垮。设太小又浪费吞吐量。 - 误区三:把
prefetchCount理解成 "每秒推多少条"。不是的,它控制的是 "同时在途的未确认消息数",是个并发数,不是速率。
面试高频追问
-
prefetchCount设多少合适? 没有标准答案。消息处理快(几毫秒)可以给大一点,50~100;处理慢(调外部接口、写数据库)就小一点,5~20。上线前压测调。 -
Spring AMQP 里
prefetch默认值是多少? Spring AMQP 2.0 之前默认 1,之后默认 250。250 这个值对很多场景来说偏大了,建议根据自己的消费者处理能力显式配置。 -
如果多个消费者监听同一个队列,
prefetchCount怎么生效? 每个 Consumer 独立计数。Consumer A 的prefetchCount设 10,Consumer B 设 10,那 Broker 最多同时给 A 推 10 条、给 B 推 10 条,互不影响。
常见面试变体
- "RabbitMQ 消费者处理不过来怎么办?"
- "RabbitMQ 的 QoS 机制了解吗?"
- "
prefetchCount参数是干什么的?"
记忆口诀
限流三板斧:basicQos 设 prefetch、关自动 ACK 改手动、处理完一条 ACK 一条。prefetchCount 控的是 "同时在途数",不是 "每秒推多少"。
总结
消费端限流靠 basic.qos 的 prefetchCount 参数,控制 Broker 同时推给消费者的未确认消息数。配合手动 ACK 使用,消费者处理完一条、确认一条,Broker 才会补推。自动 ACK 下限流无效。prefetchCount 的值没有银弹,根据业务处理速度和压测结果来调。