MySQL binlog、redolog 和 undolog 日志的区别是什么?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
日志体系理解:面试官不仅仅是想知道三种日志的名字和定义,更是想知道你是否理解 MySQL 的日志体系架构,以及每种日志在整个事务生命周期中扮演的角色。
-
崩溃恢复机制:考察你是否清楚 MySQL 如何通过 redo log 保证持久性(D)、通过 undo log 保证原子性(A)和实现 MVCC,以及 binlog 在主从复制中的作用。
-
两阶段提交原理:是否理解 redo log 和 binlog 的 "两阶段提交" 机制,为什么需要这个机制来保证数据一致性。
核心答案
MySQL 中这三种日志各司其职,核心区别如下:
| 对比维度 | redo log | undo log | binlog |
|---|---|---|---|
| 归属层级 | InnoDB 引擎层 | InnoDB 引擎层 | MySQL Server 层 |
| 核心作用 | 崩溃恢复,保证持久性 | 事务回滚、MVCC,保证原子性 | 主从复制、数据备份 |
| 写入方式 | 循环写,空间固定 | 按事务写入 | 追加写,文件可配置 |
| 内容形式 | 物理日志(在某某页修改了什么) | 逻辑日志(反向 SQL) | 逻辑日志(SQL 语句或行变更) |
| 事务关联 | 事务提交时刷盘 | 事务执行中持续写 | 事务提交时一次性写入 |
一句话总结:redo log 是 "崩溃恢复的救命稻草",undo log 是 "后悔药的原料",binlog 是 "主从复制的信使"。
深度解析
一、三种日志的架构位置
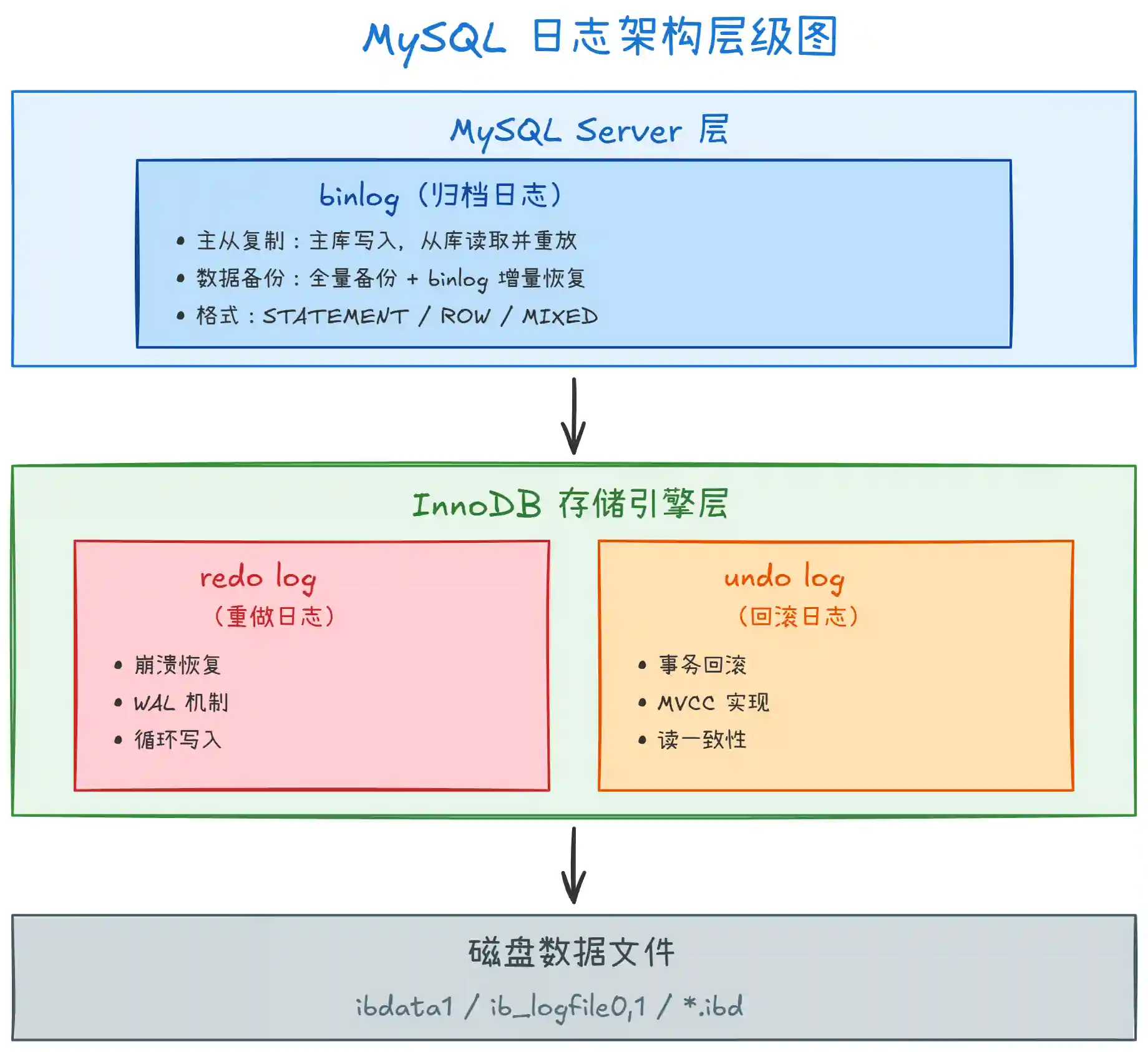
上图展示了 MySQL 三种日志的架构层级关系:
-
binlog:位于 Server 层,所有存储引擎都可以使用。它是 MySQL 的 "归档日志",主要用于主从复制和数据备份恢复。以事件形式记录所有修改数据的 SQL 语句或行变更。
-
redo log 和 undo log:位于 InnoDB 引擎层,是 InnoDB 特有的。redo log 用于崩溃恢复,采用 WAL(Write-Ahead Logging)机制;undo log 用于事务回滚和 MVCC 实现。
-
层级分离的意义:正因为 binlog 在 Server 层,redo log 在引擎层,才需要 "两阶段提交" 来保证两者的一致性。
二、redo log 详解
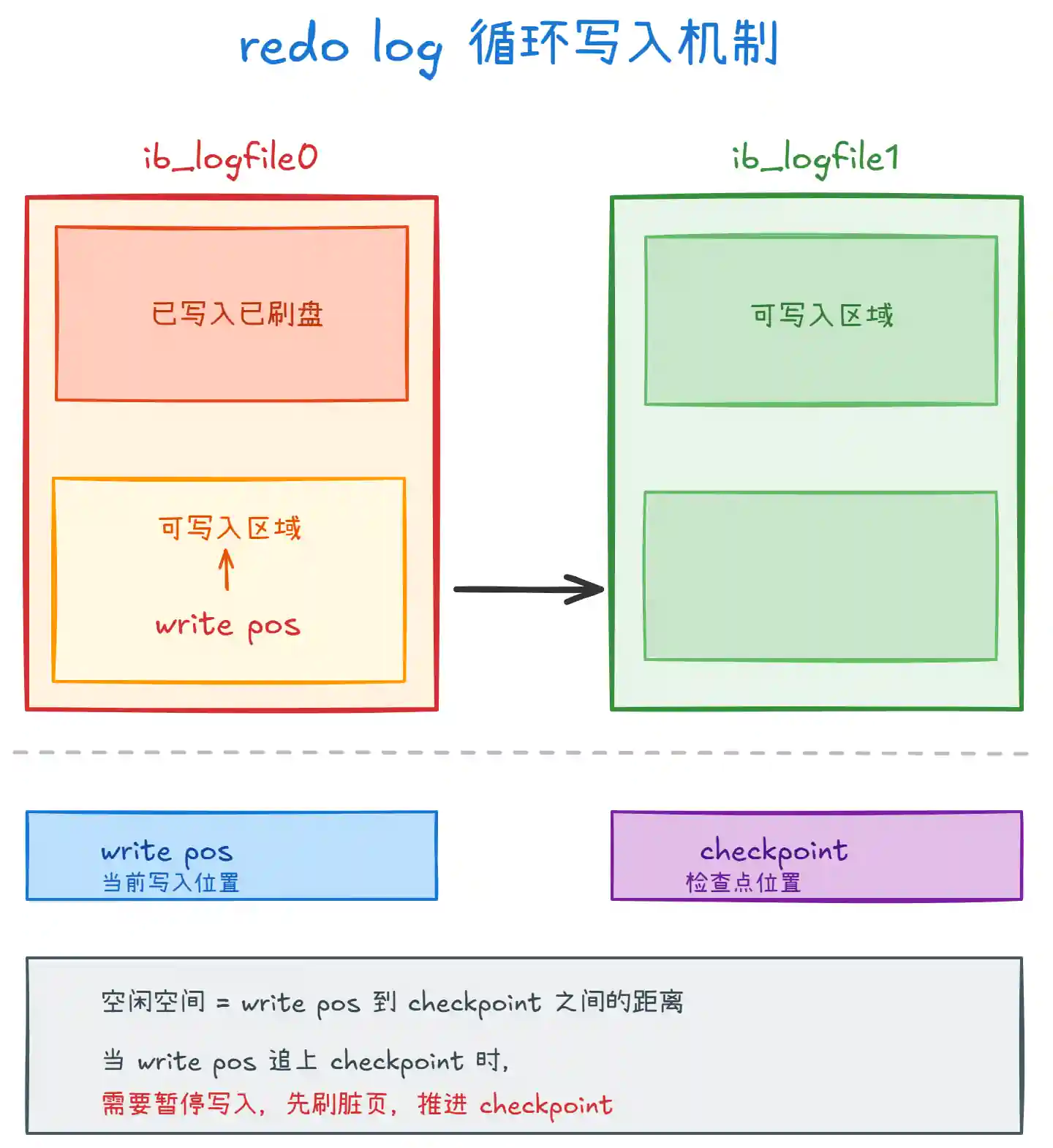
上图展示了 redo log 的循环写入机制:
-
循环写入:redo log 不是无限追加的,而是固定大小(默认两个文件各 1GB)循环使用。
write pos记录当前写入位置,checkpoint记录检查点位置。 -
WAL 机制:事务提交时,先写 redo log(顺序 I/O),再异步刷脏页到数据文件(随机 I/O)。这样即使数据库崩溃,也可以通过 redo log 恢复未刷盘的数据。
-
刷盘时机:
- 事务提交时(
innodb_flush_log_at_trx_commit=1,最安全) - 后台线程定时刷
- redo log 空间不足时
- 事务提交时(
关键配置:
-- 查看 redo log 配置
SHOW VARIABLES LIKE 'innodb_log%';
-- innodb_log_file_size:单个日志文件大小(默认 48MB,建议 1-2GB)
-- innodb_log_files_in_group:日志文件数量(默认 2)
-- innodb_flush_log_at_trx_commit:刷盘策略(0/1/2,建议 1)
三、undo log 详解
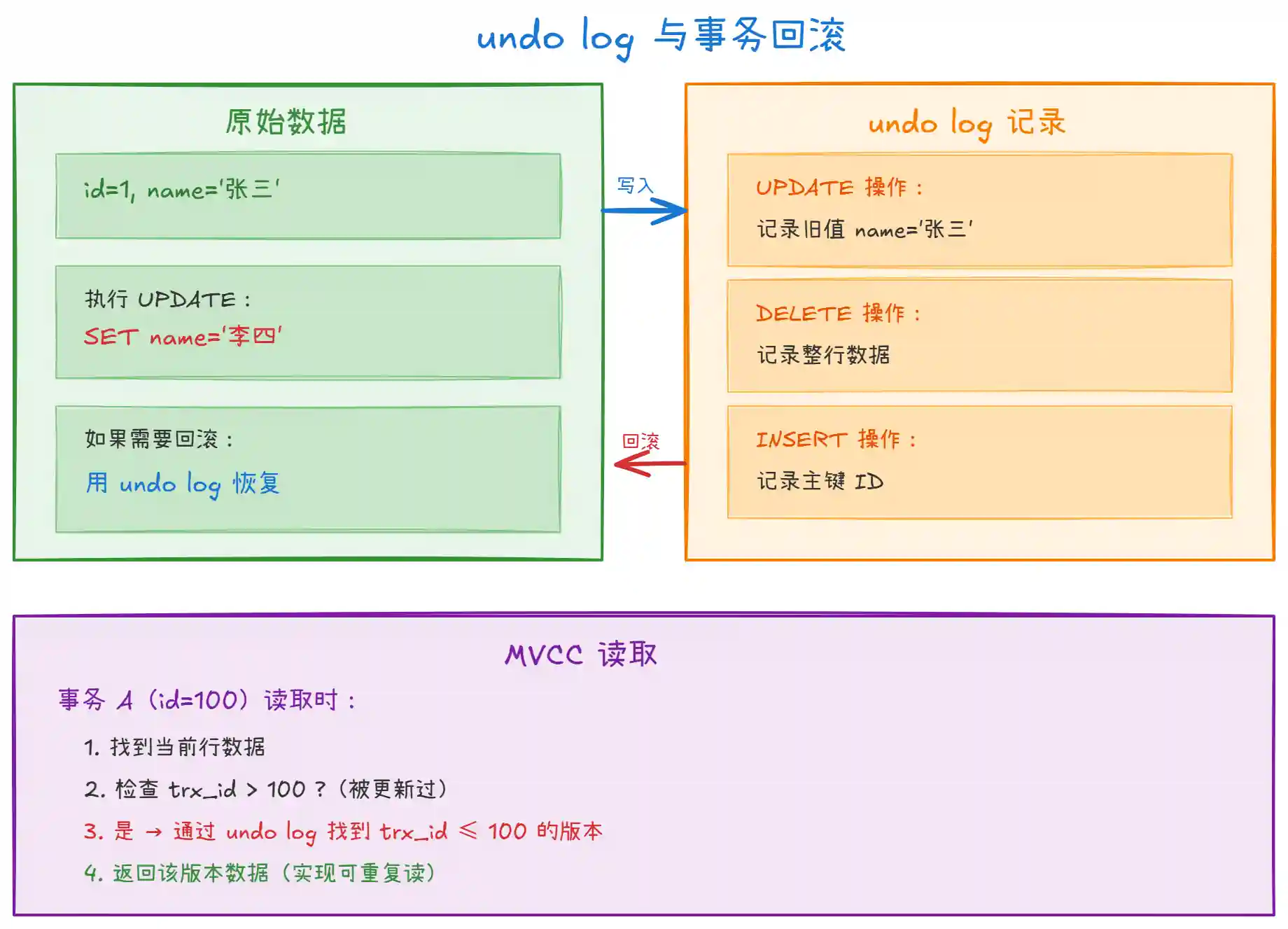
上图展示了 undo log 的两大核心作用:
-
事务回滚:记录数据的 "反向操作"。
UPDATE记录旧值,DELETE记录整行,INSERT记录主键。当事务回滚时,用 undo log 中的信息恢复数据。 -
MVCC 实现:每行数据都有隐藏列
trx_id(事务 ID)和roll_pointer(回滚指针)。通过roll_pointer找到 undo log 中的旧版本,实现 "读已提交" 和 "可重复读" 隔离级别。
undo log 存储位置:
-- MySQL 5.6 之前:存储在共享表空间 ibdata1
-- MySQL 5.6+:可配置独立的 undo 表空间
SHOW VARIABLES LIKE 'innodb_undo%';
-- innodb_undo_tablespaces:undo 表空间数量
-- innodb_max_undo_log_size:undo 表空间最大值
-- innodb_undo_log_truncate:是否自动截断
四、binlog 详解
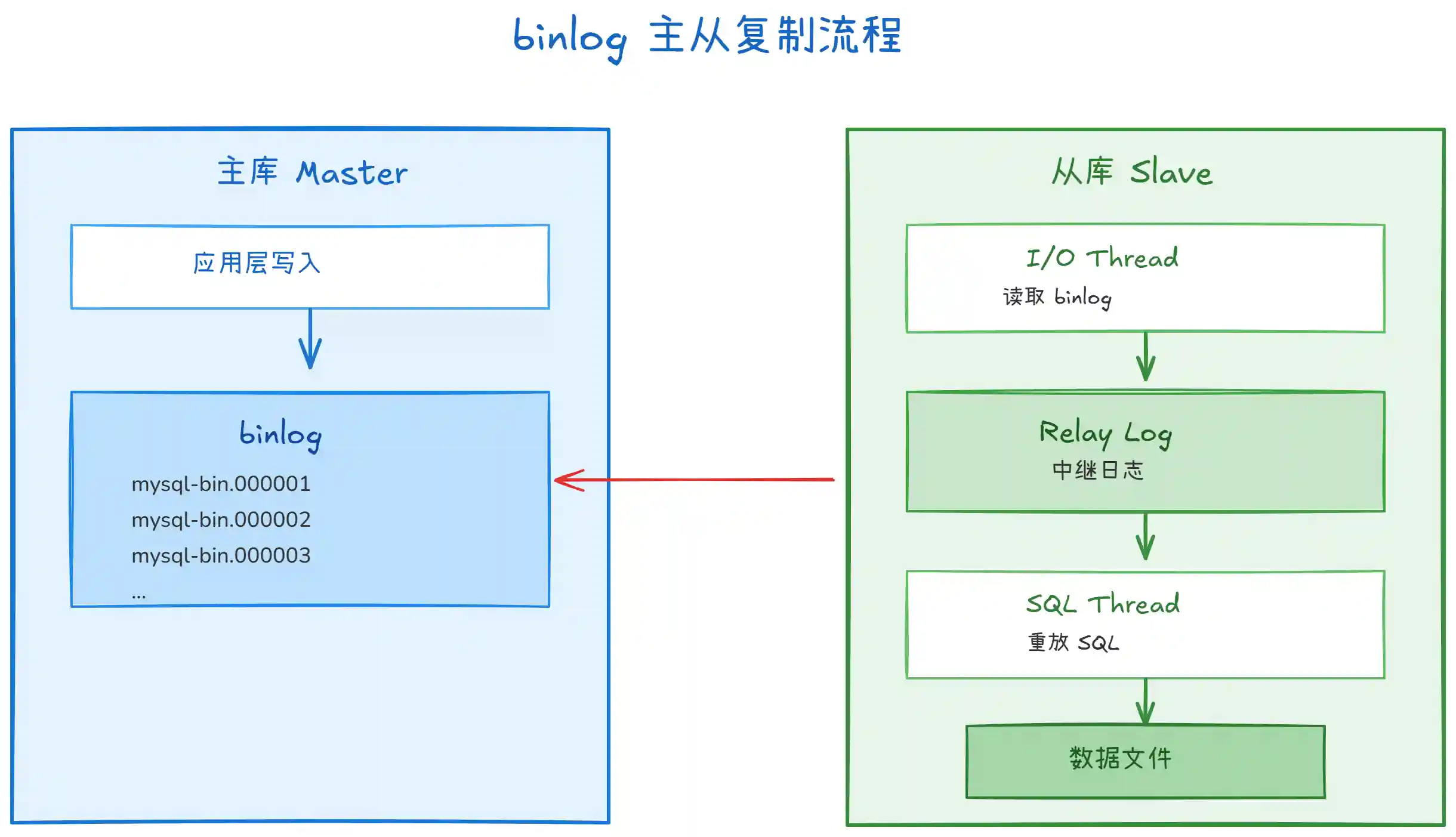
上图展示了 binlog 在主从复制中的作用:
-
主库写入:事务提交时,将修改操作写入 binlog(追加写入,文件可配置滚动)
-
从库同步:
- I/O Thread:连接主库,读取 binlog,写入本地的 Relay Log(中继日志)
- SQL Thread:读取 Relay Log,重放 SQL 语句,保持与主库数据一致
binlog 三种格式:
| 格式 | 记录内容 | 优点 | 缺点 |
|---|---|---|---|
STATEMENT |
SQL 语句本身 | 日志量小 | 不确定函数可能导致不一致 |
ROW |
行数据变更 | 数据一致性最好 | 日志量大 |
MIXED |
混合模式 | 兼顾两者 | 复杂场景可能仍有问题 |
-- 查看 binlog 配置
SHOW VARIABLES LIKE '%binlog%';
-- binlog_format:日志格式(推荐 ROW)
-- binlog_cache_size:事务缓存大小
-- sync_binlog:刷盘策略(1 = 每次提交都刷盘,最安全)
五、两阶段提交
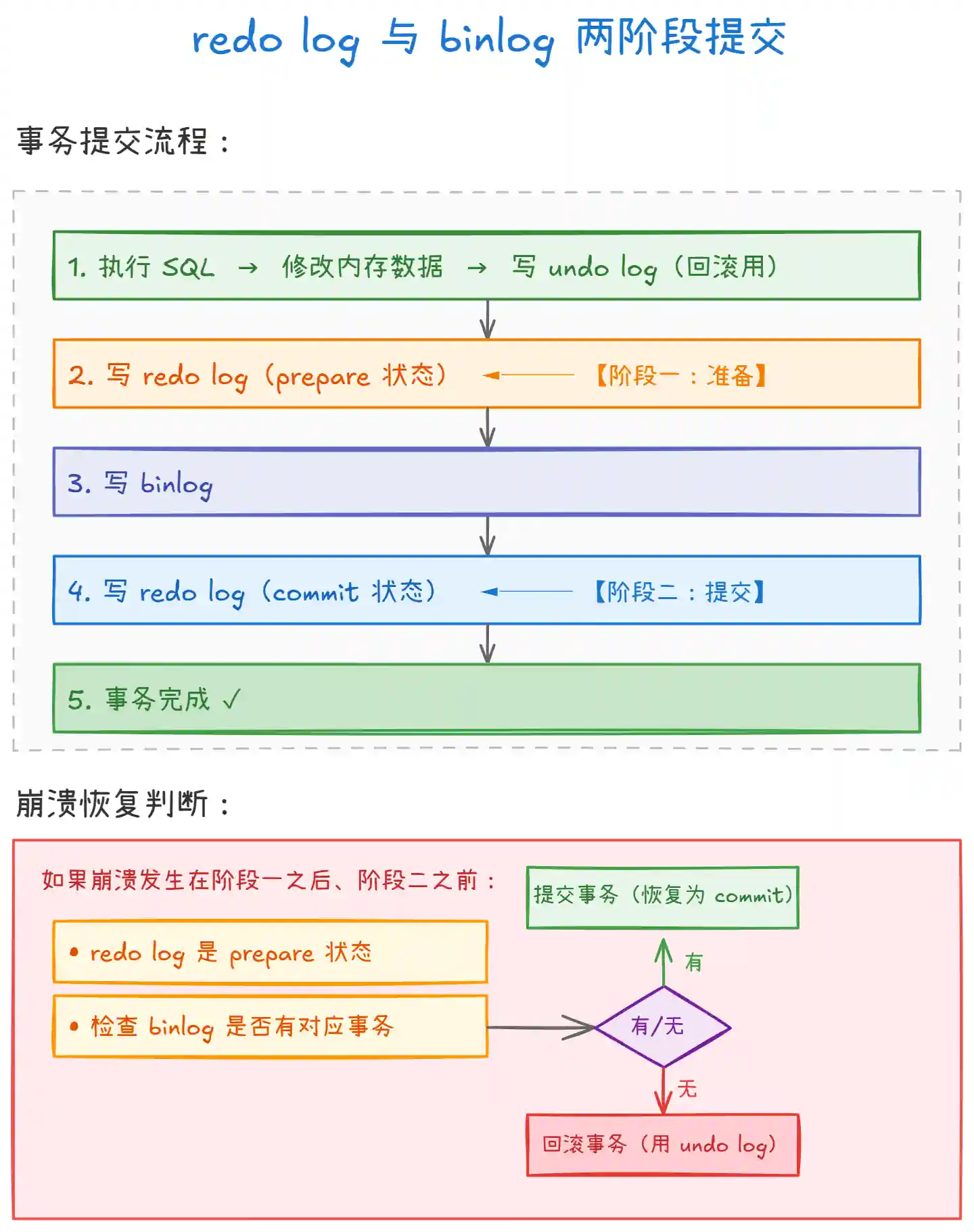
上图展示了 redo log 和 binlog 的两阶段提交流程:
-
为什么需要两阶段提交:因为 redo log 和 binlog 是两个独立的日志系统,如果不协调,可能出现:
- redo log 写了但 binlog 没写 → 主库恢复后数据丢失,从库没收到
- binlog 写了但 redo log 没写 → 主库恢复后数据回滚,从库却收到了
-
两阶段提交流程:
- Prepare 阶段:写 redo log,标记为
prepare状态 - Commit 阶段:写 binlog,然后写 redo log 标记为
commit状态
- Prepare 阶段:写 redo log,标记为
-
崩溃恢复:如果崩溃时 redo log 处于
prepare状态,通过检查 binlog 是否完整来决定提交还是回滚。
面试高频追问
-
追问一:redo log 为什么采用循环写而不是追加写?
循环写的目的是空间复用。redo log 只需要保留 "从检查点到当前" 的数据,更早的日志对应的数据已经刷盘,可以覆盖。追加写会导致磁盘空间无限增长,不现实。
-
追问二:
innodb_flush_log_at_trx_commit设为 0/1/2 有什么区别?值 行为 安全性 性能 0每秒刷盘一次 ❌ 可能丢 1 秒数据 最高 1每次提交都刷盘 ✅ 不丢数据(最安全) 较低 2每次提交写入 OS 缓存,每秒刷盘 ⚠️ 可能丢 1 秒数据 中等 生产环境强烈推荐设为
1。 -
追问三:为什么 binlog 不能代替 redo log 做崩溃恢复?
- binlog 是逻辑日志(SQL 或行变更),恢复时需要重新执行,效率低
- redo log 是物理日志(页修改),恢复时直接应用,效率高
- binlog 是追加写,没有记录 "哪些页已刷盘" 的信息,无法精确恢复
-
追问四:undo log 什么时候会被删除?
undo log 不会在事务提交后立即删除,因为可能还有其他事务在用它做 MVCC 读。只有当所有活跃事务都不再需要这个 undo log 时,才会被 purge 线程清理。
常见面试变体
- "MySQL 是如何保证事务的 ACID 特性的?"
- "redo log 和 binlog 有什么区别?为什么要两阶段提交?"
- "MVCC 是怎么实现的?undo log 在其中扮演什么角色?"
- "数据库崩溃后如何恢复数据?"
记忆口诀
三大日志定位:
- redo log:引擎层,循环写,崩溃恢复保持久
- undo log:引擎层,反向记,回滚 MVCC 都靠它
- binlog:Server 层,追加写,主从复制做备份
两阶段提交:先 prepare 后 commit,中间写 binlog,崩溃查状态
总结
redo log、undo log、binlog 是 MySQL 的三大核心日志。redo log 在 InnoDB 引擎层,采用循环写的 WAL 机制,保证崩溃恢复时的持久性;undo log 记录反向操作,支持事务回滚和 MVCC 实现;binlog 在 Server 层,追加写入,用于主从复制和数据备份。三者通过 "两阶段提交" 保证一致性,是 MySQL 高可用架构的基石。