Redis 和 Caffeine 的区别是什么?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
缓存架构理解:面试官不仅仅是想知道两者的功能差异,更是想考察你是否理解 "本地缓存" 与 "分布式缓存" 的本质区别,以及在系统架构中各自扮演的角色。
-
技术选型能力:考察你是否能够根据业务场景(数据量、一致性要求、性能需求)做出合理的技术选型,而不是盲目跟风。
-
实践经验:是否在实际项目中使用过这两种缓存,是否了解它们在生产环境中的坑和最佳实践。
核心答案
Redis 和 Caffeine 是两种不同类型的缓存,核心区别在于 存储位置 和 架构模式:
| 对比维度 | Redis | Caffeine |
|---|---|---|
| 缓存类型 | 分布式缓存 | 本地缓存(进程内缓存) |
| 存储位置 | 独立服务进程,可部署多节点 | 应用 JVM 进程内 |
| 访问速度 | 网络开销,毫秒级 | 直接内存访问,纳秒级 |
| 数据一致性 | 多节点共享,一致性好 | 各节点独立,存在不一致风险 |
| 容量限制 | 可配置大容量(GB 级别) | 受 JVM 堆内存限制 |
| 持久化 | 支持 RDB/AOF 持久化 | 进程重启数据丢失 |
| 数据结构 | 丰富(String、Hash、List、Set、ZSet 等) | 简单 KV 存储 |
| 集群支持 | 原生支持主从、哨兵、集群 | 单机,无集群概念 |
一句话总结:Redis 是分布式缓存,适合跨服务共享数据;Caffeine 是本地缓存,适合单节点高性能读取。
深度解析
一、架构模式对比

上图展示了 Redis 的分布式缓存架构。所有服务实例通过网络访问同一个 Redis 集群,实现数据共享。特点是:
- 数据共享:多个服务实例看到的是同一份数据,天然保证一致性
- 独立部署:Redis 作为独立服务,可横向扩展
- 网络开销:每次访问都需要网络通信,存在毫秒级延迟
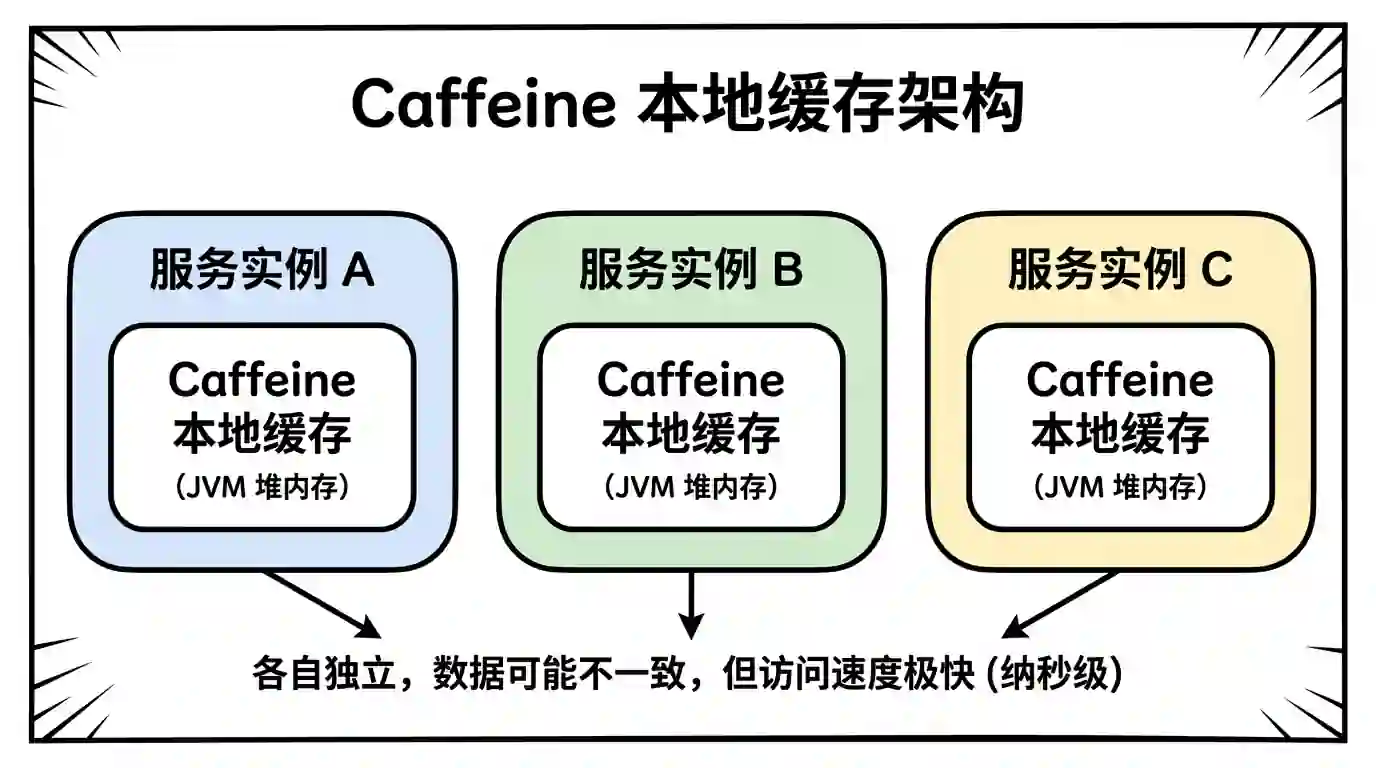
上图展示了 Caffeine 的本地缓存架构。每个服务实例都有自己独立的 Caffeine 缓存,存储在各自的 JVM 堆内存中。特点是:
- 数据隔离:各实例缓存独立,可能存在数据不一致
- 极速访问:直接内存读取,纳秒级响应
- 容量受限:受 JVM 堆内存大小限制
二、性能对比
| 场景 | Redis | Caffeine | 性能差距 |
|---|---|---|---|
| 单次读取 | ~1ms(网络 + 反序列化) | ~100ns | 10000 倍 |
| 单次写入 | ~1ms | ~100ns | 10000 倍 |
| 高并发读取 | 受网络带宽限制 | 仅受 CPU 限制 | 差距明显 |
三、典型使用场景
Redis 适合的场景:
// 1. 分布式 Session 存储
// 2. 跨服务共享的配置数据
// 3. 分布式锁
// 4. 消息队列(延迟队列)
// 5. 排行榜、计数器
// 6. 需要持久化的缓存数据
@Autowired
private StringRedisTemplate redisTemplate;
// 分布式锁示例
public boolean tryLock(String key, String value, long expireTime) {
return Boolean.TRUE.equals(
redisTemplate.opsForValue().setIfAbsent(key, value, expireTime, TimeUnit.SECONDS)
);
}
Caffeine 适合的场景:
// 1. 热点数据的本地缓存(如配置、字典数据)
// 2. 高频读取、低频更新的数据
// 3. 对一致性要求不高的场景
// 4. 单机应用或无需跨服务共享的数据
// Caffeine 配置示例
Cache<String, User> userCache = Caffeine.newBuilder()
.maximumSize(10000) // 最大缓存数量
.expireAfterWrite(10, TimeUnit.MINUTES) // 写入后 10 分钟过期
.refreshAfterWrite(5, TimeUnit.MINUTES) // 写入后 5 分钟异步刷新
.recordStats() // 开启统计
.build();
// 获取缓存(不存在则加载)
User user = userCache.get(userId, id -> userService.getById(id));
四、生产最佳实践:两级缓存架构
实际项目中,通常采用 L1(本地)+ L2(分布式)两级缓存 架构:

两级缓存的协同工作流程:
- 读取流程:先查 L1(Caffeine),未命中再查 L2(Redis),最后查数据库
- 写入流程:更新数据库后,同时删除 L1 和 L2 缓存
- 一致性保障:通过 Redis Pub/Sub 或消息队列通知各节点清除本地缓存
// Spring Cache + Caffeine + Redis 两级缓存示例
@Service
public class UserService {
@Cacheable(cacheNames = "user", key = "#id") // 自动两级缓存
public User getById(Long id) {
return userMapper.selectById(id);
}
@CacheEvict(cacheNames = "user", key = "#user.id") // 自动清除两级缓存
public void update(User user) {
userMapper.updateById(user);
}
}
五、常见误区
| 误区 | 说明 |
|---|---|
| "本地缓存更快,全部用 Caffeine" | 多实例部署时数据不一致问题严重,适合只读或容忍不一致的场景 |
| "Redis 够用了,不需要本地缓存" | 对于 QPS 极高的热点数据,Redis 网络开销可能成为瓶颈 |
| "两级缓存太复杂,维护成本高" | Spring Cache 已提供良好抽象,配置简单,收益明显 |
面试高频追问
-
两级缓存如何保证一致性?
- 延迟双删 + Redis Pub/Sub 通知各节点清除本地缓存
- 设置合理的过期时间兜底
- 使用 Canal 监听数据库 binlog 主动刷新
-
Caffeine 的淘汰策略是什么?
- W-TinyLFU 算法,结合了 LRU 和 LFU 的优点
- 高频 + 最近访问的数据优先保留
-
Redis 缓存穿透、击穿、雪崩怎么解决?
- 穿透:布隆过滤器、空值缓存
- 击穿:互斥锁、热点数据永不过期
- 雪崩:过期时间加随机值、多级缓存
常见面试变体
- "本地缓存和分布式缓存的区别?"
- "为什么要有两级缓存?"
- "Caffeine 和 Guava Cache 的区别?"
- "如何设计一个高可用的缓存架构?"
记忆口诀
选型口诀:单机高频用本地,分布式共享用 Redis,极致性能两结合。
架构口诀:L1 快但各自飞,L2 慢但大家看,两级配合性能王。
总结
Redis 是分布式缓存,适合跨服务数据共享、需要持久化、复杂数据结构的场景;Caffeine 是本地缓存,适合单节点高频读取、对一致性要求不高的场景。生产环境推荐 两级缓存架构:Caffeine 作为 L1 缓存提供极速响应,Redis 作为 L2 缓存保证数据一致性,通过消息机制同步各节点本地缓存。