为什么 RAG 要用向量数据库?其他数据库不行吗?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
语义检索的本质理解:你到底懂不懂 RAG 的检索环节是在做什么?它不是在做关键词匹配,而是在做 "语义相似度" 计算——这是选用向量数据库的根本原因。
-
数据库选型的判断力:能不能区分向量数据库、关系型数据库、搜索引擎各自的适用场景?面试官想看的是你的技术选型思维,而不是 "大家都用所以我也用"。
-
对行业融合趋势的感知:2025-2026 年,传统数据库和搜索引擎都在往向量能力靠拢(如 Elasticsearch 原生支持 kNN、PostgreSQL 有
pgvector插件)。能不能聊到这个趋势,是区分 "了解" 和 "关注前沿" 的标志。
核心答案
一句话:RAG 要做的是语义检索,不是关键词匹配。向量数据库是专门为语义相似度搜索设计的,传统数据库做不到这件事。
打个比方:用户问 "怎么退货",传统数据库会去搜包含 "怎么" 和 "退货" 这两个关键词的文档;但如果你的知识库里写的是 "退换货政策" 或 "商品返还流程",传统数据库就搜不到了。而向量数据库能把 "怎么退货" 和 "退换货政策" 理解为语义相近的内容,即使它们没有一个字相同。
这就是根本原因 —— RAG 的检索核心是 "找到语义相关的文档",而向量数据库天生就是干这个的。
深度解析
一、不同数据库的检索方式对比
先看一张对比图,把几种数据库的检索方式放在一起,区别一目了然:

上图展示了三种数据库在检索方式上的本质差异:
-
关系型数据库(MySQL 等):基于精确匹配或模糊匹配(
LIKE)。它要的是 "字面上一样",哪怕意思完全相同,只要字不一样就搜不到。适合结构化数据的 CRUD 操作,不适合语义检索 -
搜索引擎(Elasticsearch):基于倒排索引 + BM25 算法做关键词检索。比关系型数据库强不少,支持分词、同义词扩展、权重打分,但它本质上还是在做关键词匹配,不理解 "语义"。搜 "怎么退货" 找不到 "商品返还流程",因为它们共享的关键词太少
-
向量数据库(Milvus 等):把文本编码成高维向量,通过计算向量之间的距离(余弦相似度、欧氏距离等)来判断语义相似度。它关注的是 "意思相近",而不是 "字面一样"。这正是 RAG 需要的能力
二、为什么传统数据库搞不定语义检索?
关键在于 "怎么表示语义" 这个问题。
传统数据库存储的是原始文本。你说 "怎么退货",它就在文档里找 "怎么" 和 "退货" 这几个字。它不理解这句话的意思。
向量数据库的思路完全不同。它先用 Embedding 模型把文本编码成一个高维向量(比如 1536 维的浮点数数组)。这个向量就是这段文本的 "语义指纹"——语义相近的文本,它们的向量在空间中的距离也相近。
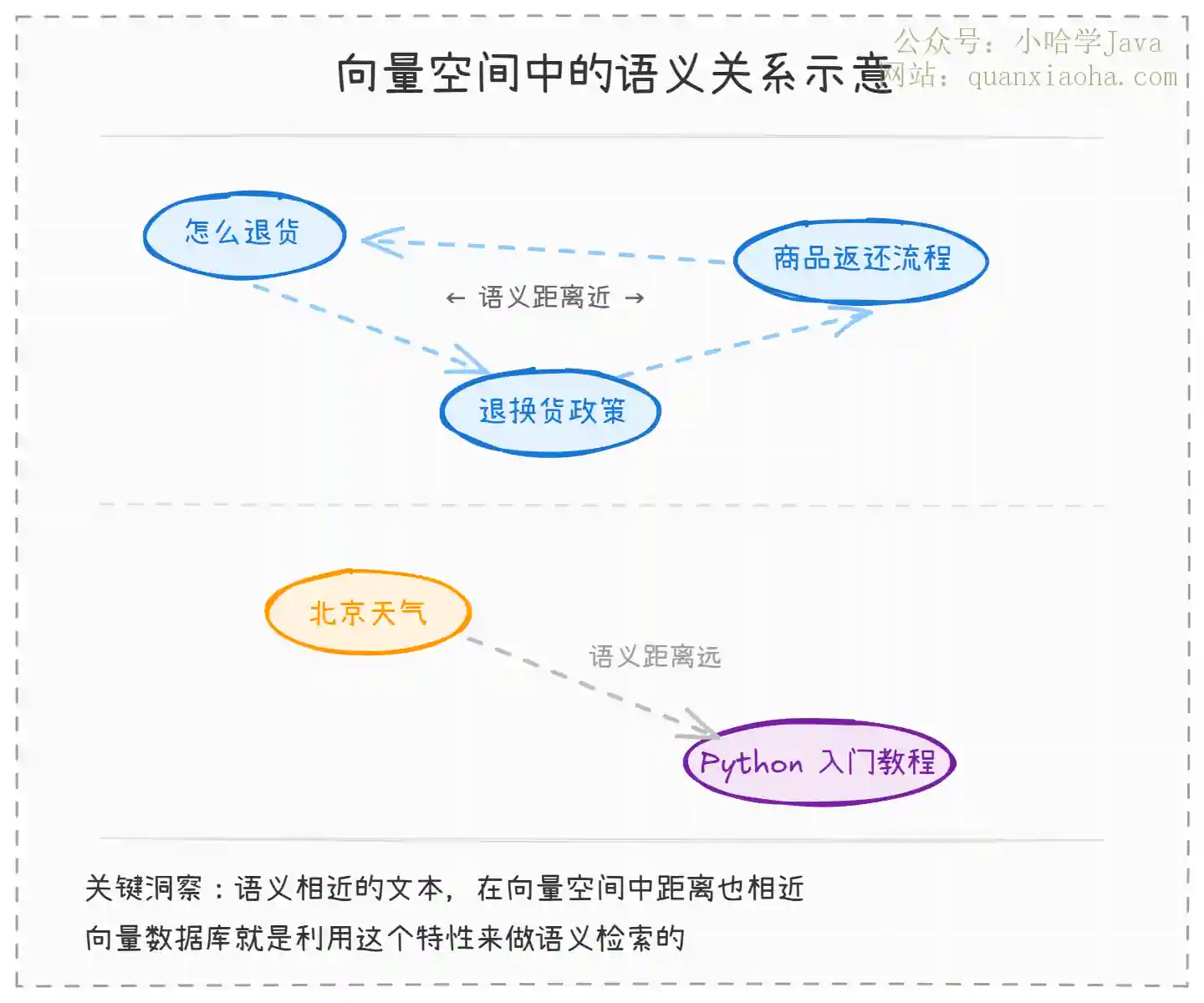
上图展示了向量空间中的语义关系:
- "怎么退货"、"退换货政策"、"商品返还流程" 这三句话字面上差异很大,但意思相近,所以它们的向量在空间中距离很近。向量数据库能轻松把它们关联起来
- "北京天气" 和 "Python 入门教程" 语义完全不相关,向量距离远,自然不会被一起检索出来
这种 "语义距离 → 空间距离" 的映射,是 Embedding 模型的功劳,不是数据库本身的能力。但向量数据库专门针对这种高维向量的相似度检索做了极致的优化——索引算法(HNSW、IVF、PQ)、距离计算(余弦、L2、内积)、分布式扩展等,这些都是传统数据库不具备的。
三、向量数据库的核心技术优势
光说 "能做语义检索" 还不够,面试官可能追问 "那向量数据库具体快在哪里?" 这时候你需要知道几个关键技术点:
| 技术特性 | 说明 |
|---|---|
| ANN 索引算法 | HNSW(分层导航小世界图)、IVF(倒排文件索引)等算法,能在亿级向量中实现毫秒级检索。暴力遍历计算所有向量的距离?那得算到猴年马月 |
| 多种距离度量 | 支持余弦相似度、欧氏距离(L2)、内积(IP)等多种度量方式,适配不同的 Embedding 模型和业务场景 |
| 高维向量优化 | 专门优化了高维浮点数组的存储和计算,比在传统数据库里用 BLOB 存向量再自己写距离计算函数高效得多 |
| 分布式扩展 | Milvus 等原生支持分布式部署,数据量从百万级到亿级可以平滑扩展 |
| 元数据过滤 | 支持在向量检索的同时做标量过滤(比如 "只搜 2025 年的文档"),这在 RAG 场景中非常实用 |
四、等等,其他数据库真的完全不行吗?
说实话,也不全是。2025-2026 年有一个明显的趋势:传统数据库和搜索引擎都在 "卷" 向量能力。
- Elasticsearch 8.x:原生支持
dense_vector字段和 kNN 搜索,可以同时做 BM25 关键词检索和向量语义检索。如果你的数据量不大(百万级以内),完全可以用 Elasticsearch 一站式搞定 Hybrid Search,不需要额外部署向量数据库 - PostgreSQL + pgvector:PostgreSQL 通过
pgvector插件支持向量存储和检索。对于已经有 PG 的团队,这是个低成本的入门方案 - Redis:通过
RedisSearch模块支持向量检索。Spring AI有原生的RedisVectorStore支持,适合中小规模场景
那面试时怎么答?我觉得应该这样说:
"向量数据库是语义检索的最优解,但不是唯一解。" 选型要看具体场景:
| 场景 | 推荐方案 |
|---|---|
| 数据量大(千万级以上)、对检索性能要求高 | 专业向量数据库(Milvus、Qdrant) |
| 需要同时做全文搜索 + 向量检索 | Elasticsearch 8.x(Hybrid Search) |
| 数据量小、想低成本验证 | PGVector / Redis / Chroma |
| 已有基础设施、不想引入新组件 | 用现有数据库的向量扩展能力 |
生产环境中最常见的方案其实是 Hybrid Search——向量数据库做语义检索,Elasticsearch 做关键词检索,两路结果融合后 Rerank。取长补短,效果最好。
五、Spring AI 中切换向量数据库有多简单?
Spring AI 通过 VectorStore 接口抽象了向量存储的操作,切换数据库基本只需要改依赖和配置。
// VectorStore 是统一接口,底层实现可随时切换
public interface VectorStore extends DocumentWriter, Closeable {
// 添加文档(自动 Embedding + 存储)
void add(List<Document> documents);
// 语义检索:根据用户问题检索相似的文档片段
List<Document> similaritySearch(String query);
// 带条件检索:支持相似度阈值、Top-K、过滤表达式
List<Document> similaritySearch(SearchRequest request);
}
切换到不同的向量数据库,只需要改 Maven 依赖和配置文件:
# 方案一:用 Milvus(大规模生产环境)
spring.ai.vectorstore.milvus:
client:
host: localhost
port: 19530
collection-name: rag_docs
embedding-dimension: 1536
# 方案二:用 Redis(中小规模,利用已有基础设施)
spring.ai.vectorstore.redis:
uri: redis://localhost:6379
index: rag_docs
prefix: "doc:"
# 方案三:用 Elasticsearch(需要 Hybrid Search)
spring.ai.vectorstore.elasticsearch:
connection-url: http://localhost:9200
index-name: rag_docs
dimensions: 1536
Java 代码层面完全不用改。这就是接口抽象的好处——你的 RAG 业务逻辑和底层向量存储解耦了,选型可以随时调整。
面试高频追问
-
追问一:向量数据库的索引算法有哪些?
主流的有 HNSW(基于图的索引,召回率高,内存占用大)、IVF(基于聚类的倒排索引,可控制精度和速度的平衡)、PQ(乘积量化,用牺牲一定精度换取内存压缩)。生产环境用得最多的是 HNSW,综合性能最好。
-
追问二:余弦相似度、欧氏距离、内积有什么区别?选哪个?
余弦相似度关注向量方向(角度),适合文本语义相似度;欧氏距离关注绝对位置差异,受向量长度影响;内积同时考虑方向和长度。文本语义检索一般选余弦相似度。如果 Embedding 模型输出的向量已经归一化(长度为 1),内积和余弦等价。
-
追问三:Elasticsearch 8.x 已经支持向量检索了,还需要 Milvus 吗?
看数据规模和性能要求。百万级以内、需要同时做全文搜索 + 向量检索的场景,ES 完全够用。千万级以上、纯向量检索为主、对延迟敏感的场景,Milvus 更有优势。两个也不是非此即彼,生产环境经常组合使用。
常见面试变体
- "向量数据库和传统数据库有什么区别?"
- "RAG 的检索环节为什么要用 Embedding + 向量检索,而不是直接用 Elasticsearch?"
- "你在项目中是怎么选向量数据库的?考虑了哪些因素?"
- "什么是 Hybrid Search?为什么生产环境推荐混合检索?"
记忆口诀
选数据库看检索方式:精确匹配用 MySQL,关键词检索用 ES,语义检索用向量库。RAG 核心是语义检索,所以用向量数据库。记住 "意思相近比字面相同更重要"。
总结
RAG 用向量数据库的根本原因是——RAG 的检索核心是语义相似度搜索,而不是关键词精确匹配。向量数据库通过高维向量 + ANN 索引算法,能高效地找到 "意思相近" 的文档片段,这是传统数据库和搜索引擎做不到的。不过 2025-2026 年的 trend 是融合:Elasticsearch 加了向量能力,PostgreSQL 有 pgvector,选型时不必死磕专业向量数据库,看场景选最合适的方案就行。