Embedding 是什么?1536 维什么意思?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
概念理解深度:不仅仅是背定义,而是能不能用自己的话解释清楚——文本是怎么变成数字的?这些数字代表了什么?为什么能用数字的 "距离" 来衡量语义的 "远近"?
-
维度的直觉理解:1536 维到底什么意思?为什么不是 10 维或者 10 万维?维度和语义表达能力之间是什么关系?这块答不清楚,说明只是记了个数字。
-
工程实践意识:实际用 Embedding 的时候怎么选模型?维度对存储和计算有什么影响?面试官想知道你有没有在真实项目里踩过坑。
核心答案
Embedding(向量嵌入) 就是把一段文本转换成一个浮点数数组(向量),这个数组是这段文本的 "语义指纹"。
比如你输入 "今天天气真好",Embedding 模型会输出类似这样的结果:
[0.012, -0.034, 0.567, -0.189, 0.423, ..., 0.078] ← 共 1536 个浮点数
1536 维的意思是:这个浮点数数组有 1536 个元素。每个元素是一个 float 值,比如 0.012、-0.034。这 1536 个数共同编码了这段文本的语义信息。
核心逻辑:语义相近的文本,它们的向量在高维空间中距离也相近。 所以你可以通过计算两个向量的距离(余弦相似度)来判断两段文本在语义上有多相似——这就是 RAG 中向量检索的底层原理。
深度解析
一、从文本到向量——到底发生了什么?
很多人知道 "文本变向量",但具体怎么变的?来,我们一步步拆。
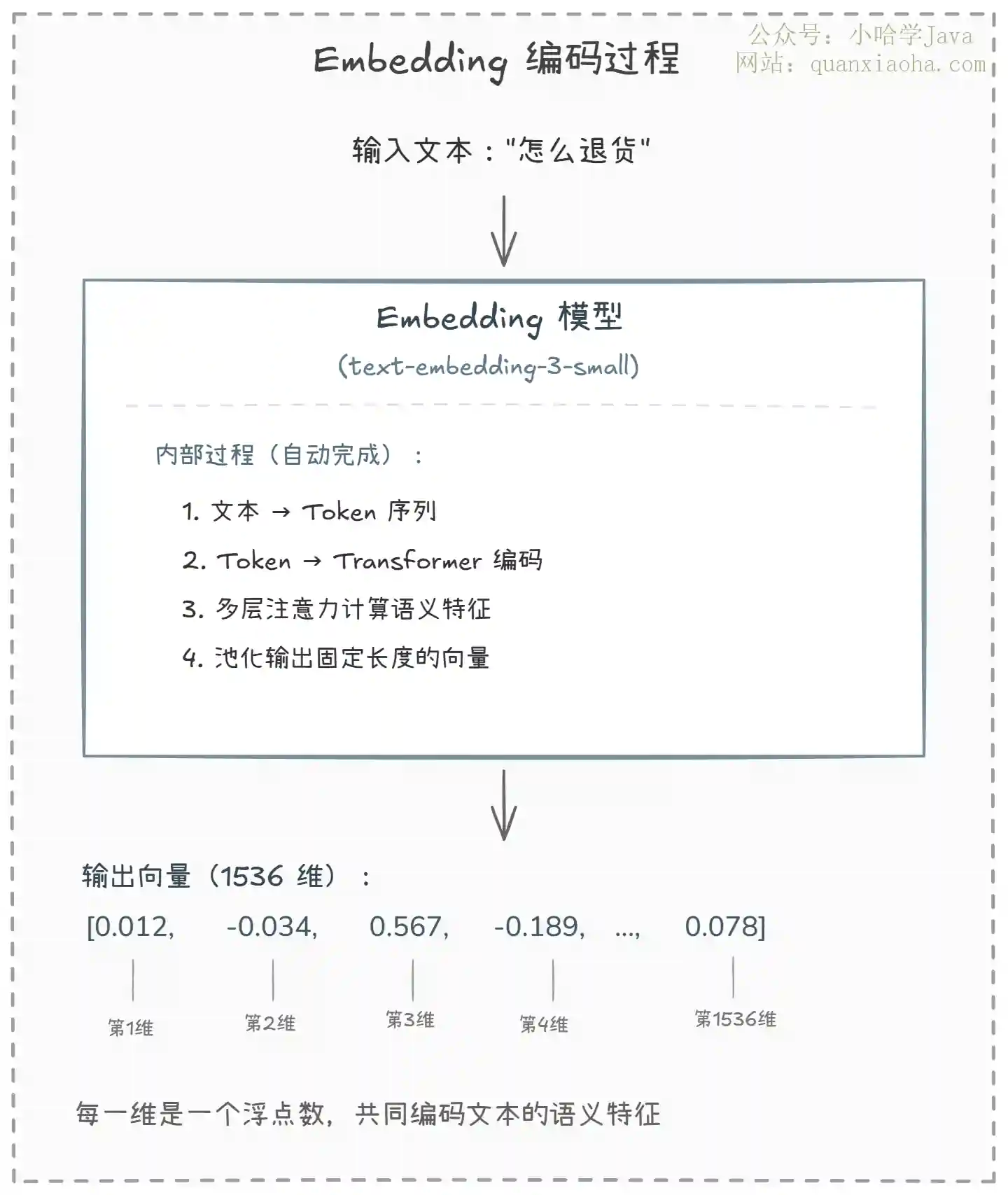
上图展示了 Embedding 的编码过程:
-
输入:一段文本(比如 "怎么退货"),送入 Embedding 模型
-
模型内部:文本先被切分成 Token 序列,然后经过 Transformer 编码器的多层注意力机制,逐层提取语义特征。这个过程是预训练好的,你不需要关心细节,只要调用 API 就行
-
输出:一个固定长度的浮点数数组。用 OpenAI 的
text-embedding-3-small模型,输出就是 1536 个浮点数
注意,你不需要手动去做这些操作。在实际开发中,不管是 Spring AI 还是 LangChain4j,调用 Embedding 模型就是一行代码的事。但理解这个过程有助于你明白为什么维度越高语义表达能力越强——因为更多的维度意味着模型能编码更多的语义特征。
二、1536 维——为什么是这个数字?
说实话,1536 这个数字本身没有特别的含义,它不是什么 "最优解",而是 OpenAI 在设计 text-embedding-ada-002 模型时选定的一个参数。后来 text-embedding-3-small 延续了这个维度。
但它背后的逻辑是有道理的:
| 维度 | 语义表达能力 | 存储成本 | 计算成本 | 适用场景 |
|---|---|---|---|---|
| 128~256 维 | 一般 | 低 | 低 | 简单分类、大规模初筛 |
| 768 维 | 较好 | 中 | 中 | BERT 系列、轻量级 RAG |
| 1024 维 | 好 | 中 | 中 | BGE-M3,多语言 RAG |
| 1536 维 | 很好 | 较高 | 较高 | 主流 RAG 系统 |
| 3072 维 | 极好 | 高 | 高 | 高精度场景 |
| 8192+ 维 | 极强 | 很高 | 很高 | 研究探索,极少生产使用 |
简单来说:维度越高,能编码的语义信息越丰富,但存储和计算成本也越高。 1536 维是当前 RAG 系统中性价比最好的选择之一。
举个直觉上的例子:假设用 3 维向量表示一个人 [身高, 体重, 年龄],只能编码很有限的信息。但如果用 100 维 [身高, 体重, 年龄, 收入, 学历, 兴趣1, 兴趣2, ...],就能更精确地区分不同的人。Embedding 的维度也是这个道理——1536 个维度就是 1536 个 "语义特征轴",足以精细地刻画文本的语义。
三、语义相似度怎么算?
有了向量之后,怎么判断两段文本是否语义相近?靠计算向量之间的距离。最常用的是余弦相似度。

上图展示了余弦相似度的计算逻辑:
- 文本 A "怎么退货" 和文本 B "退换货政策" 的余弦相似度是 0.96,说明语义非常接近。虽然字面差异很大,但 Embedding 模型理解了它们的语义是相同的
- 文本 A 和文本 C "北京天气预报" 的余弦相似度只有 0.12,说明语义不相关,不会被错误地检索到
除了余弦相似度,还有欧氏距离(L2)和内积(IP)等度量方式。文本语义检索场景一般用余弦相似度,因为它关注方向而不是绝对大小,对文本长度不敏感。
四、用 Spring AI 实际感受一下 Embedding
光说不练假把式,来一段 Spring AI 的代码,直接看看 Embedding 到底输出什么。
Maven 依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
配置 application.yml:
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
base-url: https://api.openai.com # 或换成国内代理地址
embedding:
options:
model: text-embedding-3-small # 输出 1536 维向量
Java 代码:
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.stereotype.Service;
@Service
public class EmbeddingDemoService {
private final EmbeddingModel embeddingModel;
public EmbeddingDemoService(EmbeddingModel embeddingModel) {
this.embeddingModel = embeddingModel;
}
/**
* 演示 Embedding 编码过程
*/
public void demo() {
// 1. 把文本编码成向量
String text1 = "怎么退货";
String text2 = "退换货政策";
String text3 = "北京天气预报";
float[] vector1 = embeddingModel.embed(text1);
float[] vector2 = embeddingModel.embed(text2);
float[] vector3 = embeddingModel.embed(text3);
// 2. 看看向量的维度和内容
System.out.println("向量维度:" + vector1.length); // 输出:1536
System.out.println("前5个值:" + java.util.Arrays.toString(
java.util.Arrays.copyOf(vector1, 5)));
// 输出示例:[0.012, -0.034, 0.567, -0.189, 0.423]
// 3. 计算余弦相似度
double sim12 = cosineSimilarity(vector1, vector2); // ≈ 0.96
double sim13 = cosineSimilarity(vector1, vector3); // ≈ 0.12
System.out.println("'怎么退货' vs '退换货政策' 相似度:" + sim12);
System.out.println("'怎么退货' vs '北京天气预报' 相似度:" + sim13);
}
/**
* 计算余弦相似度
*/
private double cosineSimilarity(float[] a, float[] b) {
double dotProduct = 0.0, normA = 0.0, normB = 0.0;
for (int i = 0; i < a.length; i++) {
dotProduct += a[i] * b[i];
normA += a[i] * a[i];
normB += b[i] * b[i];
}
return dotProduct / (Math.sqrt(normA) * Math.sqrt(normB));
}
}
运行结果大概是这样:
向量维度:1536
前5个值:[0.012, -0.034, 0.567, -0.189, 0.423]
'怎么退货' vs '退换货政策' 相似度:0.962
'怎么退货' vs '北京天气预报' 相似度:0.118
看到没?"怎么退货" 和 "退换货政策" 的相似度高达 0.96,虽然字面上差别很大,但 Embedding 模型理解了它们的语义是相同的。这就是向量检索比关键词检索强大的地方。
五、常见误区
这块有几个面试中常踩的坑,提前避一下:
误区一:"维度越高越好"
并不是。维度越高语义表达能力越强,但存储和计算成本也越高。1536 维的向量,每个 float 占 4 字节,一条就是 6KB。百万级文档就是 6GB 的纯向量数据。选择维度要在效果和成本之间找平衡点。
误区二:"Embedding 只能处理文本"
不是的。Embedding 是一个通用概念,文本、图片、音频、视频都可以做 Embedding。只不过在 RAG 场景下,我们主要用文本 Embedding。多模态 Embedding(如 CLIP)可以把图片和文本编码到同一个向量空间中,实现 "以图搜文" 或 "以文搜图"。
误区三:"所有 Embedding 模型输出都是 1536 维"
不是。不同模型的输出维度不同:BERT 输出 768 维,BGE-M3 输出 1024 维,text-embedding-3-small 输出 1536 维,text-embedding-3-large 输出 3072 维。而且 OpenAI 的新模型支持通过参数 "截断" 维度——比如把 3072 维截断为 512 维,牺牲一点精度换取更低的存储成本。Spring AI 中可以通过 dimensions 参数来控制。
六、Embedding 模型怎么选?
| 模型 | 维度 | 特点 | 适用场景 |
|---|---|---|---|
text-embedding-3-small(OpenAI) |
1536 | 性价比高,英文优秀 | 英文 RAG、快速验证 |
text-embedding-3-large(OpenAI) |
3072 | 语义表达最强,可截断 | 对精度要求高 |
bge-large-zh(BAAI) |
1024 | 中文优化,开源免费 | 中文 RAG 首选 |
bge-m3(BAAI) |
1024 | 多语言 + 多粒度 + 多功能 | 多语言混合场景 |
text-embedding-v3(通义千问) |
1024 | 中文优秀,阿里云 API | Spring AI Alibaba 项目 |
选型建议:中文场景用 bge 系列开源模型省钱又好用;项目已经在用 OpenAI API 的直接用 text-embedding-3-small 最方便;用 Spring AI Alibaba 的直接用通义千问 Embedding 最省事。
面试高频追问
-
追问一:余弦相似度和欧氏距离有什么区别?RAG 中一般用哪个?
余弦相似度关注向量方向(角度),不受向量长度影响;欧氏距离关注绝对位置差异,受向量长度影响。文本语义检索一般用余弦相似度,因为文本长度不应该影响语义相似度的判断。
-
追问二:Embedding 模型可以微调吗?什么时候需要微调?
可以,但大部分场景不需要。只有当通用 Embedding 模型在你的垂直领域表现不好(比如大量专业术语、行业黑话),才考虑微调。微调需要准备大量的 "相似文本对" 和 "不相似文本对" 作为训练数据。
-
追问三:向量维度可以降低吗?降低后效果差多少?
可以,OpenAI 的新模型支持通过
dimensions参数截断维度(Matryoshka 原理)。比如把 3072 维截断到 512 维,存储成本降低 6 倍,精度只下降几个百分点。对存储敏感、数据量大的场景可以考虑。
常见面试变体
- "什么是向量嵌入?为什么 RAG 需要它?"
- "Embedding 模型的维度越高越好吗?为什么?"
- "你知道哪些主流的 Embedding 模型?怎么选?"
- "余弦相似度和欧氏距离有什么区别?"
记忆口诀
Embedding 本质:文本变数字,数字表语义,语义近则距离近。记住 "文本 → 浮点数组 → 距离 = 相似度"。
1536 维:1536 个浮点数,就是 1536 个 "语义特征轴"。维度越高特征越精细,但成本也越高。记住 "维度 = 语义精度,和成本正相关"。
总结
Embedding 就是把文本编码成浮点数数组(向量),1536 维表示这个数组有 1536 个浮点数。语义相近的文本向量距离近,语义不同的距离远——这就是 RAG 向量检索的底层原理。维度越高语义表达越精细但成本越高,1536 维是当前主流的性价比之选。面试时如果能结合 Spring AI 的代码示例说明,会更有说服力。