RAG 的完整流程是什么?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
流程完整性:能不能把 RAG 从离线建库到在线生成完整走一遍?中间有遗漏环节(比如漏掉 Rerank)会被扣分。
-
每个环节的深度理解:文档解析有哪些难点?Chunk 策略怎么选?Embedding 模型选型依据是什么?向量检索的原理了解吗?每个环节面试官都可能追问细节。
-
生产实战经验:你搭建 RAG 系统的时候踩过什么坑?知道怎么优化效果吗?能结合实际项目讲才最有说服力。
核心答案
RAG 的完整流程分为两大阶段、六个核心环节:
离线阶段:文档解析 → 文本切分 → 向量化 → 存入向量库
在线阶段:向量检索 → 重排序 → LLM 生成
下面我把每个环节掰开揉碎地讲一遍。
深度解析
一、离线阶段:知识库构建
离线阶段的目标是把各种非结构化文档变成可检索的向量数据。这一步是整个 RAG 的地基,地基没打好,后面检索再怎么优化都是白搭。
1. 文档解析(Document Parsing)
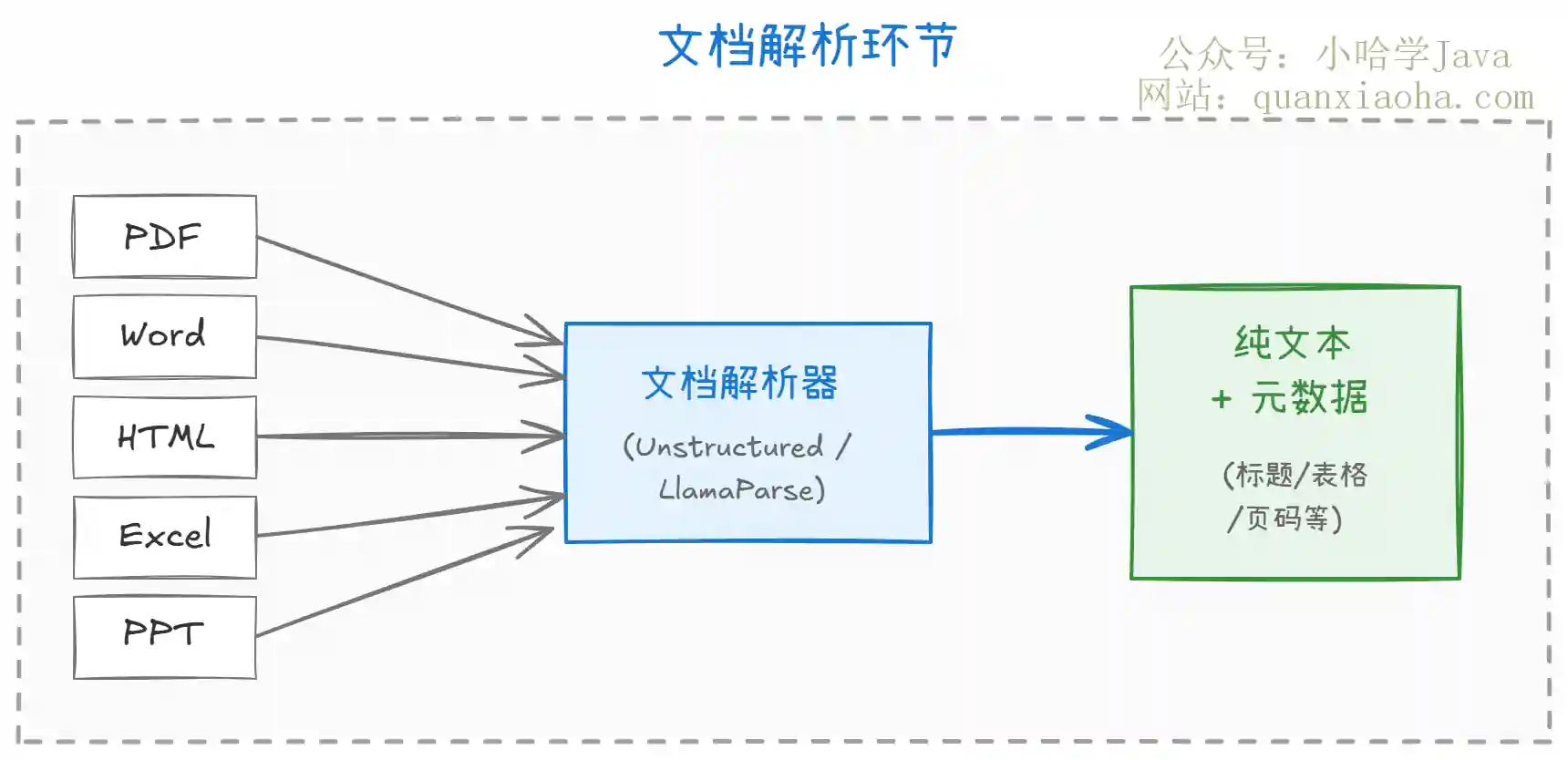
文档解析看着简单,实际是整个流程中最容易被低估的环节。它的任务是把 PDF、Word、HTML、Excel、PPT 等各种格式的文档,转换成结构化的纯文本。
常见的坑:
- 表格数据丢失:很多解析器遇到表格直接丢弃或变成乱序文本。表格里的数据往往是最有价值的(比如产品参数、定价信息),丢了就检索不到
- 图片中的文字:要不要做 OCR?做了准确率够不够?不做就丢失信息。这块需要根据业务场景权衡
- 公式提取:学术论文、技术文档中的数学公式,大部分解析器处理得不好
- 多栏排版:双栏论文解析后文字顺序经常错乱
生产环境推荐:
- 轻量级场景用 Apache Tika(Java 生态最成熟的文档解析库)就够了
- 复杂文档(特别是含表格、图片、公式的)建议用
LlamaParse、Marker等专业工具 - 国内也有一些不错的方案,比如
MinerU(开源的文档解析工具,对中文 PDF 支持较好)
2. 文本切分(Chunking)
文本切分是 RAG 效果的 "隐形杀手"——切得不好,后面所有环节都在为它买单。

常见的切分策略:
- 固定长度切分:按字符数或 Token 数切割,最简单但最粗暴。容易把一个完整的句子或段落从中间截断,破坏语义完整性
- 递归字符切分:按分隔符的优先级逐级尝试切分(先按
\n\n,再按\n,再按空格),尽量保留段落结构。Spring AI的TokenTextSplitter和LangChain4j的DocumentSplitters都支持这种模式 - 语义切分:用 Embedding 模型计算相邻文本的语义相似度,在语义断裂处切分。效果最好,但需要额外的模型调用,成本较高
- 基于文档结构的切分:利用文档的标题层级、段落标记等结构信息来切分。对 Markdown、HTML 这类结构化文档效果很好
实战经验值:
- Chunk 大小:200~500 tokens 是比较通用的范围。太大了检索不精准(一个 Chunk 里塞太多信息),太小了上下文不完整(一个关键信息被拆成两半)
- 重叠(Overlap):50~100 tokens。重叠的作用是防止关键信息恰好落在两个 Chunk 的边界上被截断
- 别忘了存元数据!每个 Chunk 要关联它的来源文档、页码、标题等元信息,方便后续溯源展示
2025 年以来,业界还出现了 Parent-Child Chunking(父子分块)策略:用小块做检索(精准),命中后返回对应的大块给 LLM(上下文完整)。这个思路很巧妙,面试时提一下绝对加分。
3. 向量化编码(Embedding)
把每个 Chunk 用 Embedding 模型编码成高维向量(通常是 768 维或 1536 维),这个向量就是这个 Chunk 的 "语义指纹"。
Embedding 模型选型参考:
| 模型 | 特点 | 适用场景 |
|---|---|---|
text-embedding-3-small/large(OpenAI) |
效果好,API 调用,英文为主 | 英文场景、快速验证 |
bge-large-zh(BAAI) |
中文优化,开源免费 | 中文场景首选 |
gte-large-zh(阿里) |
中文效果好,MTEB 排名靠前 | 中文场景备选 |
text-embedding-v3(通义千问) |
阿里云 API,中文优秀 | Spring AI Alibaba 项目首选 |
Cohere Embed v3 |
多语言支持好 | 多语言混合场景 |
选型原则:中文场景优先选中文优化的开源模型(bge、gte 系列);用 Spring AI Alibaba 的项目可以直接用通义千问的 Embedding API;注意 Embedding 模型的维度要和向量数据库的配置一致。
4. 存入向量数据库
向量数据库负责存储所有 Chunk 的向量,并在查询时做高效的相似度检索。
主流向量数据库对比:
| 数据库 | 特点 | 适用场景 |
|---|---|---|
Milvus |
分布式、高性能、功能丰富 | 大规模生产环境 |
Qdrant |
Rust 写的,性能好,轻量 | 中小规模、Docker 部署 |
Redis |
利用已有基础设施,Spring AI 原生支持 |
中小规模、已有 Redis 的团队 |
Elasticsearch |
支持稠密+稀疏混合检索,8.x 版本原生支持向量 | 需要同时做全文搜索和向量检索 |
Pinecone |
全托管,免运维 | 不想管基础设施的团队 |
Java 生态里,Spring AI 通过统一的 VectorStore 接口屏蔽了底层差异,切换向量数据库基本只需要改配置文件,非常方便。
二、在线阶段:查询与生成
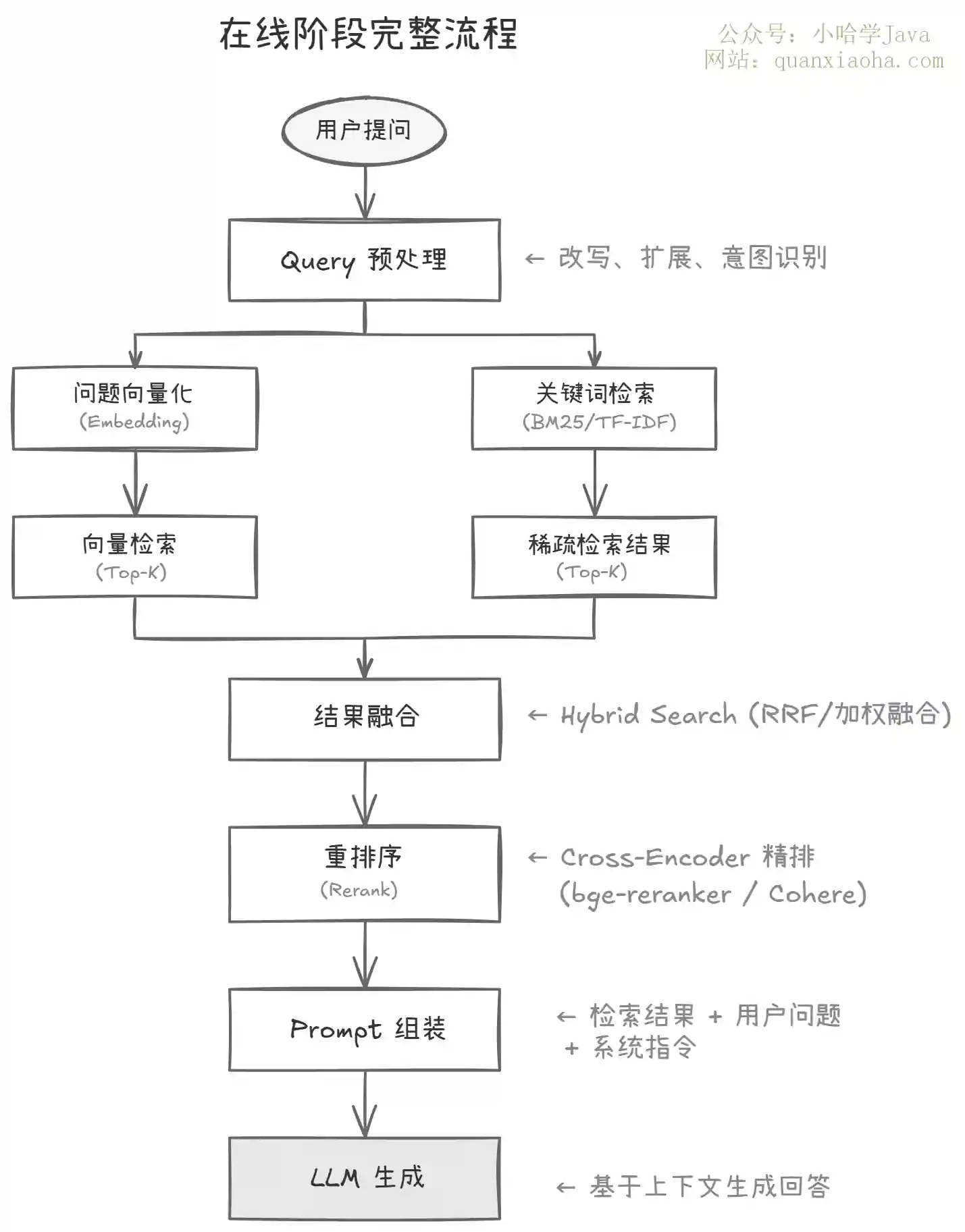
上图是在线阶段的完整流程。整体分为以下几个步骤:
-
Query 预处理:用户的原始问题可能表达模糊或口语化,直接拿去检索效果往往不好。常见的预处理包括 Query 改写(把口语化问题改写成更精确的检索 Query)、Query 扩展(生成多个同义 Query 扩大检索覆盖面)、意图识别(判断用户到底想问什么)。这一步很多人不做,但效果差异很明显
-
向量化 + 检索:把问题用同一个 Embedding 模型编码成向量,在向量数据库中做相似度检索,返回 Top-K 个最相似的 Chunk(通常 K=3~10)
-
Hybrid Search(混合检索):单纯靠向量检索会漏掉一些精确匹配的场景(比如用户搜特定的产品型号、专有名词)。生产环境推荐同时做向量检索(语义匹配)和关键词检索(精确匹配),然后把两路结果融合。融合方法常用 RRF(Reciprocal Rank Fusion)或加权打分
-
Rerank(重排序):用 Cross-Encoder 模型对检索结果做精排。向量检索用的是 Bi-Encoder(问题和文档分别编码再算相似度),速度快但精度有限;Rerank 用的 Cross-Encoder(问题和文档拼在一起编码),精度高但速度慢,所以只对 Top-K 候选做精排。这一步是提升 RAG 效果性价比最高的手段之一,很多团队跳过了 Rerank,检索准确率直接差了一个档次
-
Prompt 组装:把 Rerank 后的 Top-N 个 Chunk(通常 N=3~5)和用户问题一起组装成 Prompt。Prompt 模板设计也有讲究——要明确告诉 LLM "只能基于以下上下文来回答,如果上下文中没有相关信息就说不知道",这样能有效抑制幻觉
-
LLM 生成:大模型基于 Prompt 中的上下文生成最终回答。生成时可以要求模型标注引用来源(比如 "根据文档第 3 段..."),增强可信度
三、代码示例
Java 生态做 RAG 主要有两个主流框架:Spring AI 和 LangChain4j。下面分别展示两种实现方式。
方式一:Spring AI + Milvus
Spring AI 的优势在于和 Spring Boot 深度集成,通过 QuestionAnswerAdvisor 一行代码就能完成 RAG 检索+生成,非常适合 Java 工程师上手。
Maven 依赖:
<!-- Spring AI 核心 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<!-- Milvus 向量数据库 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store</artifactId>
</dependency>
配置文件 application.yml:
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
base-url: https://api.openai.com # 或换成国内代理地址
chat:
options:
model: gpt-4o
temperature: 0.7
embedding:
options:
model: text-embedding-3-small
vectorstore:
milvus:
client:
host: localhost
port: 19530
database-name: default
collection-name: rag_docs
embedding-dimension: 1536 # 要和 Embedding 模型维度一致
metric-type: COSINE
知识库构建(离线阶段):
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.FileSystemResource;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class KnowledgeBaseService {
private final VectorStore vectorStore;
public KnowledgeBaseService(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
/**
* 离线阶段:解析文档 → 切分 → 向量化 → 存入 Milvus
*/
public void buildKnowledgeBase(String filePath) {
// 1. 文档解析:读取文本文件
// 生产环境可用 Apache Tika 解析 PDF/Word/Excel 等
TextReader reader = new TextReader(new FileSystemResource(filePath));
List<Document> documents = reader.get();
// 2. 文本切分:按 Token 切分,每个 Chunk 最多 500 Token,重叠 50
TokenTextSplitter splitter = new TokenTextSplitter(
500, // defaultChunkSize:每个 Chunk 最大 Token 数
50, // overlap:重叠 Token 数,防止关键信息被截断
5, // minChunkSizeChars:最小 Chunk 字符数
10000, // maxNumChunks:最大 Chunk 数量
true // keepSeparator:是否保留分隔符
);
List<Document> chunks = splitter.apply(documents);
// 3 + 4. 向量化 + 存入向量库(Spring AI 自动处理)
// VectorStore.add() 内部会自动调用 Embedding 模型编码
vectorStore.add(chunks);
System.out.println("知识库构建完成,共 " + chunks.size() + " 个 Chunk");
}
}
RAG 查询(在线阶段):
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.QuestionAnswerAdvisor;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
@Service
public class RagQueryService {
private final ChatClient chatClient;
public RagQueryService(ChatClient.Builder builder, VectorStore vectorStore) {
// 构建 ChatClient,挂载 QuestionAnswerAdvisor 实现 RAG
// 核心就这一行:自动完成 "问题向量化 → 检索 → Prompt 组装 → LLM 生成"
this.chatClient = builder
.defaultAdvisors(
new QuestionAnswerAdvisor(
vectorStore,
// 检索配置:返回 Top-5 相似文档,相似度阈值 0.7
SearchRequest.builder()
.topK(5)
.similarityThreshold(0.7)
.build()
)
)
.build();
}
/**
* 在线阶段:用户提问 → 检索 → 生成回答
*/
public String ask(String question) {
return chatClient.prompt()
.user(question)
.call()
.content();
}
}
看到没?Spring AI 把整个 RAG 流程封装得非常简洁。QuestionAnswerAdvisor 内部自动完成了:问题向量化 → 向量检索 → 把检索结果拼到 Prompt 里 → 调用 LLM 生成。生产环境如果需要更细粒度的控制(比如 Hybrid Search、Rerank),可以使用 RetrievalAugmentationAdvisor 替代。
方式二:LangChain4j
LangChain4j 更灵活,适合需要深度定制 RAG 流程的场景。
Maven 依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.0.0-beta3</version>
</dependency>
<!-- 模型供应商(以 OpenAI 为例) -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>1.0.0-beta3</version>
</dependency>
<!-- 向量存储(以 Milvus 为例) -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-milvus</artifactId>
<version>1.0.0-beta3</version>
</dependency>
完整 RAG 示例:
import dev.langchain4j.data.document.Document;
import dev.langchain4j.data.document.DocumentParser;
import dev.langchain4j.data.document.DocumentSplitter;
import dev.langchain4j.data.document.parser.TextDocumentParser;
import dev.langchain4j.data.document.splitter.DocumentSplitters;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.openai.OpenAiEmbeddingModel;
import dev.langchain4j.rag.content.retriever.EmbeddingStoreContentRetriever;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;
import dev.langchain4j.store.embedding.milvus.MilvusEmbeddingStore;
import dev.langchain4j.service.AiServices;
import java.io.InputStream;
public class LangChain4jRagExample {
public static void main(String[] args) {
// ===== 1. 初始化模型 =====
ChatLanguageModel chatModel = OpenAiChatModel.builder()
.apiKey("your-api-key")
.modelName("gpt-4o")
.build();
EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder()
.apiKey("your-api-key")
.modelName("text-embedding-3-small")
.build();
// ===== 2. 初始化向量存储(Milvus) =====
EmbeddingStore<TextSegment> embeddingStore = MilvusEmbeddingStore.builder()
.host("localhost")
.port(19530)
.collectionName("rag_docs")
.dimension(1536)
.build();
// ===== 3. 离线阶段:文档解析 → 切分 → 向量化 → 入库 =====
// 使用 EmbeddingStoreIngestor 统一处理整个离线流程
DocumentSplitter splitter = DocumentSplitters.recursive(500, 50);
// 参数说明:500 = 每个 Chunk 最大 Token 数,50 = 重叠 Token 数
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(splitter)
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.build();
// 解析文档(这里用文本文件示例,生产环境可用 Apache Tika)
DocumentParser parser = new TextDocumentParser();
InputStream docStream = Thread.currentThread()
.getContextClassLoader()
.getResourceAsStream("产品手册.txt");
Document document = parser.parse(docStream);
// 一键完成:切分 → 向量化 → 入库
ingestor.ingest(document);
// ===== 4. 在线阶段:构建 RAG 服务 =====
// 创建内容检索器:问题向量化 → 在向量库中检索 Top-5
EmbeddingStoreContentRetriever retriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.maxResults(5) // 返回 Top-5 最相似的文档片段
.minScore(0.7) // 最低相似度阈值
.build();
// 使用 AiServices 自动组装 RAG 链
// LangChain4j 会自动:检索相关文档 → 拼入 Prompt → 调用 LLM 生成
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatModel)
.contentRetriever(retriever)
.build();
// 5. 提问
String answer = assistant.chat("产品的退换货政策是什么?");
System.out.println(answer);
}
/**
* 定义 Assistant 接口
* LangChain4j 会自动实现这个接口,注入 RAG 检索逻辑
*/
interface Assistant {
String chat(String userMessage);
}
}
两种框架怎么选?
| 维度 | Spring AI |
LangChain4j |
|---|---|---|
| 上手难度 | 更低,Spring Boot 开箱即用 | 稍高,需要手动组装组件 |
| 灵活性 | 中等,通过 Advisor 机制扩展 | 更高,每个组件可独立替换 |
| 生态集成 | 和 Spring 生态无缝集成 | 支持更多模型供应商和向量库 |
| 适合场景 | Spring Boot 项目、快速验证 | 需要深度定制的 RAG Pipeline |
| 国产模型 | Spring AI Alibaba 支持通义千问 |
支持通义千问、DeepSeek 等 |
如果是 Java 后端团队做 RAG,推荐用 Spring AI 快速起步,遇到需要深度定制的场景再切 LangChain4j。
四、Naive RAG → Advanced RAG → Agentic RAG 的演进
面试时如果能讲清楚 RAG 的三代演进,能体现出你对这个领域的持续关注。
| 代际 | 特点 | 关键技术 |
|---|---|---|
| Naive RAG | 基础的 "检索 → 生成" 流程 | 向量检索 + LLM 生成 |
| Advanced RAG | 在 Naive 基础上增加优化环节 | Hybrid Search、Rerank、Query 改写、Parent-Child Chunking |
| Agentic RAG | 引入 Agent 决策能力 | 自主判断是否检索、多轮检索、工具调用、反思评估 |
2025-2026 年的趋势是向 Agentic RAG 演进——RAG 不再是一个固定的 Pipeline,而是一个可以根据任务需要动态调整的智能体。模型可以自主决定 "这个问题我需不需要查资料"、"查到的资料够不够用"、"要不要换个角度再查一遍"。
面试高频追问
-
追问一:Chunk 策略怎么选?
看文档类型和业务场景。结构化文档(Markdown、HTML)优先用基于文档结构的切分;非结构化长文本用递归字符切分;对精度要求极高且预算充足可以用语义切分。Chunk 大小一般 200~500 tokens,重叠 50~100 tokens。可以多试几种策略,用评估指标来选最优的。
-
追问二:向量检索和关键词检索哪个好?为什么要做 Hybrid Search?
向量检索擅长语义匹配("怎么退货" 能匹配到 "退换货政策"),但对精确匹配不敏感(搜特定产品型号可能搜不到)。关键词检索(如 BM25)擅长精确匹配,但不理解语义。Hybrid Search 把两路结果融合,取长补短,是生产环境的标准做法。
-
追问三:Rerank 有必要做吗?用什么模型?
非常有必要。向量检索用的是 Bi-Encoder,问题和文档是独立编码的,精度有限。Rerank 用 Cross-Encoder 把问题和文档一起编码,精度显著提升。推荐
bge-reranker-v2-m3(开源中文)或Cohere Rerank(商业 API),性价比很高。 -
追问四:如何评估 RAG 系统的效果?
常用指标包括召回率(检索到了多少相关文档)、答案准确率(生成的答案是否正确)、幻觉率(答案中有多少是编造的)。推荐用
RAGAS框架做自动化评估,它提供了 Context Precision、Context Recall、Faithfulness 等指标,可以量化评估 RAG 各环节的效果。
常见面试变体
- "介绍一下 RAG 的离线阶段和在线阶段分别做什么?"
- "RAG 系统中的文本切分策略有哪些?各有什么优缺点?"
- "你用过 Spring AI 或 LangChain4j 做 RAG 吗?讲一下技术方案"
- "什么是 Hybrid Search?为什么要在 RAG 中使用混合检索?"
记忆口诀
离线四步:解析 → 切分 → 向量化 → 入库。口诀:"解析文本切小块,编码成量存入库"
在线六步:预处理 → 检索 → 融合 → 重排 → 组装 → 生成。口诀:"先改写再双路搜,融合之后做精排,塞进 Prompt 让模型来答"
总结
RAG 完整流程分两大阶段:离线阶段做知识库构建(文档解析 → 切分 → 向量化 → 入库),在线阶段做查询生成(Query 预处理 → 检索 → 融合 → Rerank → Prompt 组装 → LLM 生成)。Java 生态中 Spring AI 通过 QuestionAnswerAdvisor 一行代码搞定 RAG,LangChain4j 通过 AiServices 提供了更灵活的定制能力。面试中重点把每个环节的关键决策点讲清楚,再提一嘴 Hybrid Search 和 Rerank 这两个 "效果提升利器",基本就稳了。