什么是 RAG?为什么需要 RAG?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
概念理解:面试官不仅仅是想听你背出 RAG 的全称,更想知道你是否理解它的本质——RAG 不是模型自身的能力增强,而是一种 "外挂知识库" 的架构模式。
-
问题意识:你能不能说清楚大模型到底有哪些硬伤?为什么不能直接让它回答所有问题?这块考察的是你对 LLM 局限性的理解深度。
-
方案选型思维:知道有哪些解决大模型局限性的方案(RAG、微调、长上下文等),能说清楚为什么选 RAG,而不是上来就 "我会用 RAG"。
核心答案
RAG(Retrieval-Augmented Generation,检索增强生成) 的核心思路就一句话:让大模型在回答问题之前,先去外部知识库里检索相关资料,然后基于这些资料来生成回答。
打个比方,大模型就像一个学生参加开卷考试——与其死记硬背所有知识(预训练),不如带着参考书进场,需要的时候翻一翻。RAG 就是给大模型配的这本 "参考书"。
那为什么需要 RAG? 直接让大模型回答不行吗?还真不太行,因为大模型有几个绕不开的硬伤:
| 大模型的硬伤 | 具体表现 | RAG 如何解决 |
|---|---|---|
| 幻觉问题 | 一本正经地胡说八道,编造不存在的事实 | 基于检索到的真实文档生成回答,有据可依 |
| 知识截止 | 训练数据有截止日期,不知道最新的信息 | 知识库可以随时更新,突破时间限制 |
| 领域知识不足 | 对企业内部文档、专业知识了解有限 | 接入企业私有数据,补齐领域短板 |
| 无法溯源 | 不知道回答的依据是什么,无法验证 | 可以追溯引用来源,提供文档出处 |
深度解析
一、大模型为什么 "不够用"?
先聊聊大模型的几个核心痛点,这样你才能真正理解 RAG 的价值。
痛点一:幻觉(Hallucination)
这是大模型最被诟病的问题。大模型的本质是 "接龙"——基于上文预测下一个最可能的 Token。它并不真正 "理解" 事实,只是在做概率预测。所以当它不确定的时候,它会编一个看起来很合理的答案,而不是老老实实说 "我不知道"。
这块幻觉问题当年坑了不少人。早期很多团队直接拿 GPT-3.5 做企业客服,结果模型一本正经地给客户推荐了不存在的产品,场面一度非常尴尬。
痛点二:知识截止(Knowledge Cutoff)
大模型的知识来源于训练数据,训练完就 "定格" 了。你问它 2025 年发生的新闻事件,它要么不知道,要么靠编。对于需要实时信息的场景(股价、新闻、政策更新),裸用大模型基本不可行。
痛点三:私有知识缺失
大模型的训练数据是公开的互联网语料。你们公司的内部文档、产品手册、客户 FAQ,它统统没见过。你让它回答 "我们公司 XX 产品的退货政策是什么",它只能瞎编。
痛点四:成本与可控性
微调模型来注入新知识?可以,但成本高、周期长,而且每次知识更新都得重新训练。对于频繁变化的知识场景,这显然不现实。
二、RAG 的核心流程
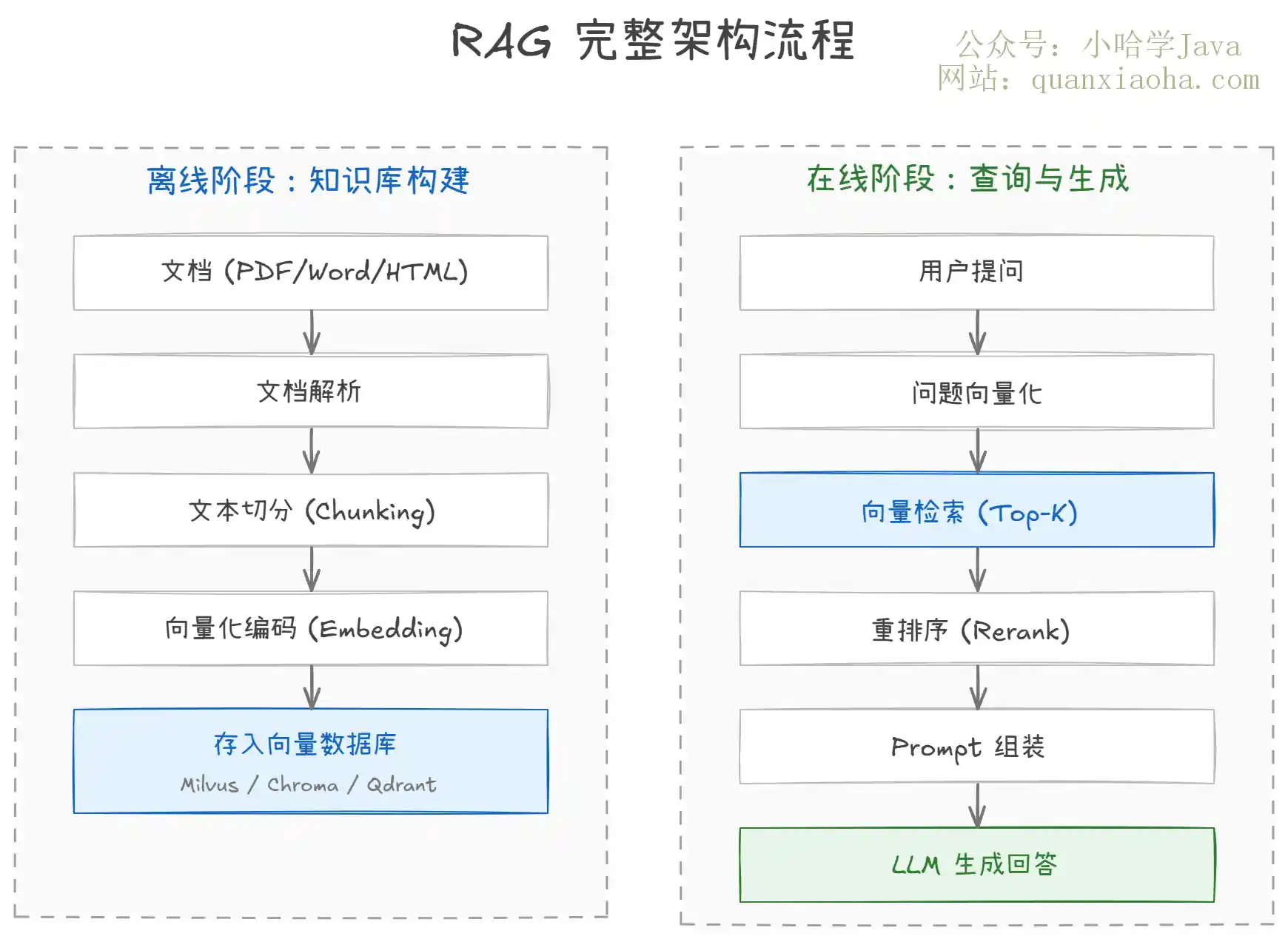
上图展示了 RAG 的完整架构,分为离线和在线两大阶段:
-
离线阶段(知识库构建):把各种格式的文档解析成纯文本,切成合适大小的片段(Chunk),用 Embedding 模型编码成向量,存入向量数据库。这一步是地基,文档解析质量、切分策略、Embedding 模型选型都会直接影响最终的检索效果。
-
在线阶段(查询与生成):用户提问后,把问题也编码成向量,在向量库里做相似度检索,找出最相关的几段文本。然后把这些文本塞进 Prompt 里,交给大模型生成最终回答。其中 Rerank(重排序)这一步很关键,用 Cross-Encoder 对初步检索结果做精排,能显著提升准确率。
三、RAG vs 微调 vs 长上下文——到底选谁?
很多人一听到 "给大模型补充知识",就只知道 RAG。但面试官可能追问:除了 RAG,还有别的方式吗?这时候你得知道怎么对比选型。
| 维度 | RAG | 微调(Fine-tuning) | 长上下文(Long Context) |
|---|---|---|---|
| 核心作用 | 注入外部知识 | 改变模型行为风格 | 扩大单次输入窗口 |
| 知识更新 | 随时更新知识库 | 需重新训练 | 更新输入内容即可 |
| 成本 | 低 | 中高(算力 + 数据) | 按 Token 计费,量大时成本高 |
| 幻觉控制 | 较好,有检索约束 | 一般 | 取决于上下文中的信息量 |
| 适用场景 | 知识密集型问答、企业知识库 | 特定格式输出、风格定制 | 全文分析、长文档摘要 |
| 响应延迟 | 多了检索环节,略高 | 无额外开销 | 输入越长延迟越高 |
| 典型代表 | LangChain + Chroma |
LoRA / QLoRA |
GPT-4o(128K)、Gemini(1M+) |
说句实话,这三者不是互斥的。实际项目中经常组合使用——比如先微调模型让它熟悉你业务的回答风格,再用 RAG 注入实时知识,长上下文则用于需要通篇理解的场景。
四、RAG 的前沿演进(2025-2026)
面试中如果能聊到 RAG 的最新发展趋势,绝对是加分项。2025 年以来,RAG 领域有几个重要的认知升级:
Agentic RAG(智能体化 RAG)
传统的 Naive RAG 是 "用户问 → 检索 → 生成" 的单次流程。而 Agentic RAG 引入了 Agent 的决策能力——模型可以自主判断需不需要检索、检索什么、检索结果够不够用、要不要换个策略再搜一遍。从被动检索变成了主动决策。
Graph-RAG(图检索增强)
传统 RAG 基于向量相似度检索,擅长找语义相近的内容,但不擅长处理实体之间的关联关系。Graph-RAG 结合知识图谱,能在实体和关系层面做更精准的推理。微软开源的 GraphRAG 框架在这方面做了很好的探索。
上下文工程(Context Engineering)
这是 2025 年 RAG 领域最重要的认知转变——RAG 的本质不是 "检索增强生成",而是 "上下文工程"。核心关注点从 "怎么检索到相关文档" 升级为 "怎么为模型构造最合适的上下文",包括上下文的选取、排序、压缩、冲突处理等。
面试高频追问
-
追问一:RAG 的检索效果不好怎么优化?
这道追问几乎是必问的。可以从以下几个层面回答:优化 Chunk 策略(语义切分替代固定长度切分)、加 Rerank 重排序、使用 Hybrid Search(稠密向量 + 稀疏关键词检索融合)、Query 改写(把用户的口语化问题改写成更适合检索的 Query)、升级 Embedding 模型。
-
追问二:RAG 和微调什么时候用哪个?能不能一起用?
简单口诀:"知识用 RAG,能力用微调"。知识频繁变化的场景选 RAG,需要改变模型行为风格的场景选微调。两者完全可以组合使用。
-
追问三:现在大模型上下文窗口越来越大了(比如
Gemini支持 100 万 Token),还需要 RAG 吗?好问题。长上下文确实能解决一部分问题,但 RAG 仍有独特优势:成本低(不用把所有文档都塞进去)、延迟低(检索几段比塞入整本文档快)、可溯源(知道答案来自哪段文档)。而且不是所有场景都需要通篇理解,很多时候只需要精准的几段话就够了。
常见面试变体
- "RAG 的全称是什么?核心思想是什么?"
- "大模型有哪些局限性?你用哪些技术手段来解决?"
- "你在项目中为什么选择 RAG 而不是微调?"
- "介绍一下你做过的 RAG 项目的架构和优化经验"
记忆口诀
为什么需要 RAG:幻觉编造、知识截止、领域缺失、难以溯源——四大硬伤,RAG 来救。记住 "外挂知识库,带着资料考试"。
RAG 流程:离线建库(解析 → 切分 → 向量化 → 入库),在线问答(提问 → 检索 → 重排 → 组装 → 生成)。
总结
RAG 的本质就是 "让大模型带着资料考试",解决的是大模型幻觉、知识截止和领域知识不足三大核心痛点。面试中先说清楚 "为什么需要",再讲 "怎么做",最后能聊到 Agentic RAG、Graph-RAG 等前沿趋势,基本就能让面试官眼前一亮。