RAG vs 微调 vs 提示工程,什么时候用哪个?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
技术边界认知:面试官想知道你是否清楚每种方法的能力边界——提示工程解决不了知识更新问题,RAG 解决不了风格定制问题,微调解决不了实时性问题。如果连边界都分不清,项目一定会走弯路。
-
选型决策能力:给你一个具体场景,能不能快速判断该用哪种方案?或者用哪几种方案的组合?这是架构师的核心能力。
-
实践深度:有没有真正在项目里用过这三种方案?各自踩过什么坑?这块能直接区分 "看过文章" 和 "做过项目"。
核心答案
一句话结论:先试提示工程,搞不定上 RAG,RAG 还不够再加微调,实际项目中三者经常组合使用。
| 维度 | 提示工程(Prompt Engineering) | RAG(检索增强生成) | 微调(Fine-tuning) |
|---|---|---|---|
| 做什么 | 优化输入提示词,不改模型 | 从外部知识库检索相关内容,增强上下文 | 在领域数据上继续训练模型权重 |
| 知识来源 | 模型自带知识 + 上下文窗口 | 外部知识库(向量数据库) | 训练数据内化为模型参数 |
| 知识更新 | 受限于上下文窗口大小 | 随时更新知识库即可 | 需重新训练,成本高 |
| 适用场景 | 通用任务、快速原型 | 知识密集型问答、企业知识库 | 风格定制、领域专业化、特定格式输出 |
| 成本 | 最低(只消耗 Token) | 中等(向量库 + Embedding + LLM) | 最高(GPU 训练 + 数据标注) |
| 技术门槛 | 低 | 中 | 高 |
| 延迟 | 最低 | 较高(多了检索环节) | 推理快(无需检索) |
深度解析
一、三者本质区别:你在改什么?
很多人搞不清楚这三者的本质差异,其实核心就一句话:你到底在改模型的哪个部分?
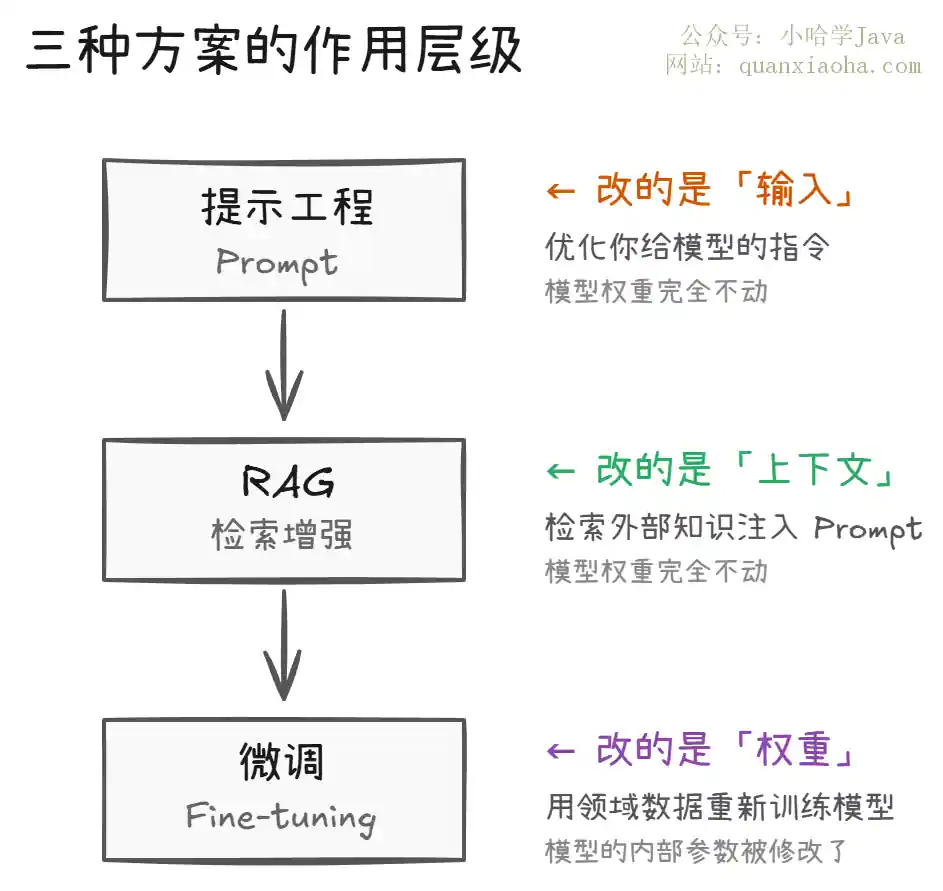
上图清楚地展示了三种方案的作用层级:
-
提示工程在最外层,你只改变输入内容,模型本身纹丝不动。这是最轻量的方式,任何模型都能用,零成本试错。
-
RAG 在中间层,你通过检索外部知识库来丰富输入的上下文信息,模型权重依然不变。相当于 "开卷考试"——让模型带着参考资料答题。
-
微调在最深层,直接修改模型的内部参数。相当于让模型 "内化" 了领域知识,答题时不需要翻书了,但学新东西就得重新 "上课"。
二、决策框架:什么时候用哪个?
别急,我给你一个实战决策流程,照着走基本不会选错:
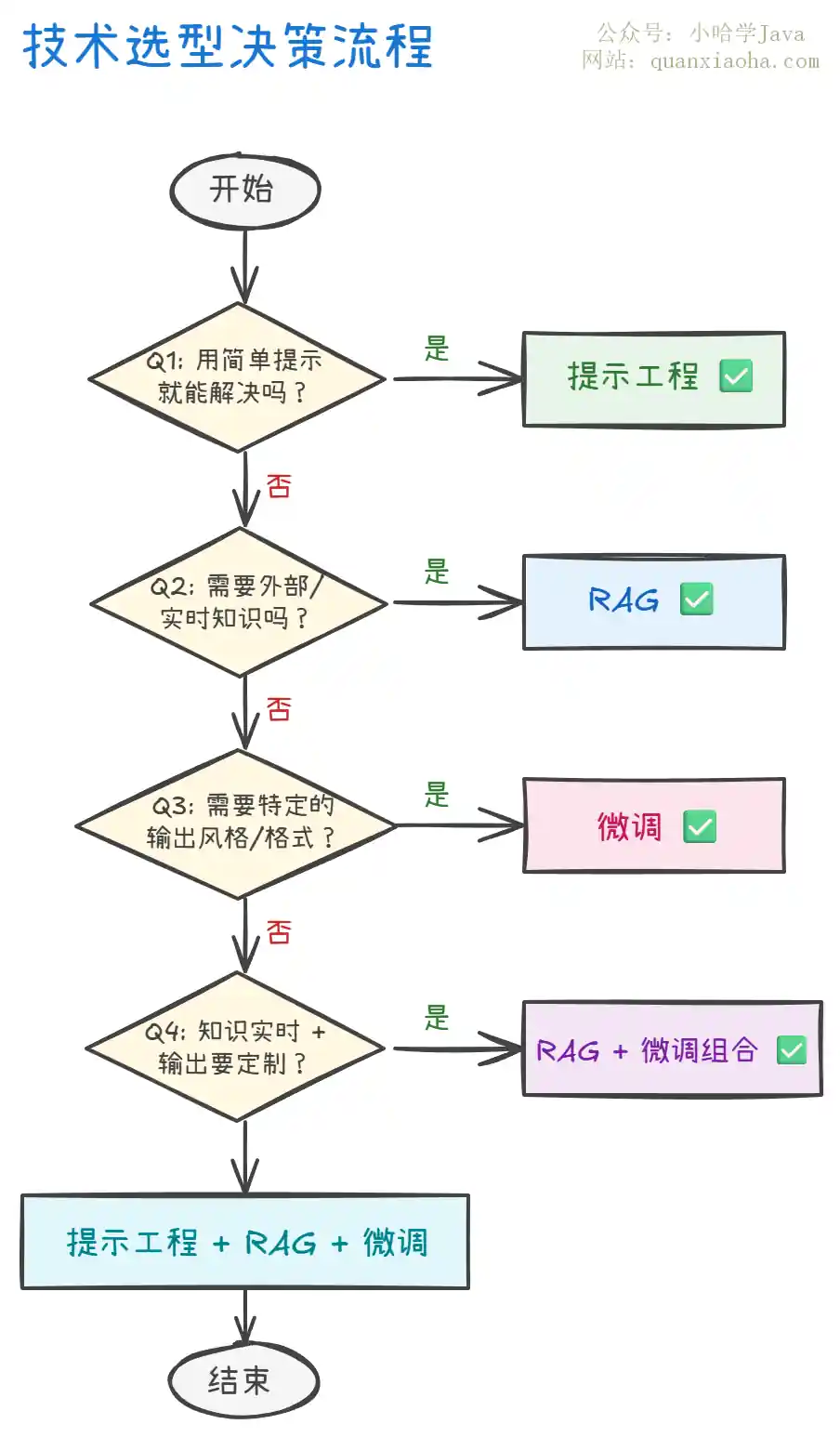
下面逐层展开:
第一层:提示工程——先试它,成本最低
提示工程是所有 AI 项目的起点。在考虑 RAG 或微调之前,先看看优化提示词能不能解决问题。
适合的场景:
- 通用问答、文案生成、翻译、总结
- 结构化输出(如让模型输出 JSON)
- Few-shot 学习(给几个示例让模型照着做)
- 快速原型验证——不确定项目方向时,先用提示工程跑通 MVP
什么时候该 "升级" 了?
- 模型的训练数据截止了,答不了最新问题 → 上 RAG
- 有大量企业私有数据,模型根本不知道 → 上 RAG
- 不管怎么改提示词,输出的风格/格式就是不达标 → 考虑微调
来个 Spring AI 的提示工程示例,感受一下:
// Spring AI 提示工程示例 —— 用 System Message 引导模型输出风格
@Autowired
private ChatClient chatClient;
public String generateProductDescription(String productName, String features) {
return chatClient.prompt()
.system("""
你是一位专业的电商文案撰写专家。
请根据提供的产品名称和特性,生成一段吸引人的产品描述。
要求:
1. 突出产品核心卖点
2. 语言生动有感染力
3. 控制在 200 字以内
4. 不要使用夸张的营销用语
""")
.user("产品名称:" + productName + "\n产品特性:" + features)
.call()
.content();
}
这就是纯提示工程——不改模型,不加知识库,只靠精心设计的提示词来控制输出。
第二层:RAG——需要 "带着资料考试" 的时候
RAG 的核心优势是 知识的实时性和可控性。你的知识库更新了,模型立马就能用上新知识,不需要重新训练。
适合的场景:
- 企业知识库问答(内部文档、产品手册、规章制度)
- 客服系统(产品 FAQ、售后政策)
- 法律/医疗/金融等专业领域的知识问答
- 任何需要 "引用来源" 的场景——RAG 能告诉你答案来自哪份文档
来个 Spring AI 的 RAG 示例,用的是最新的 RetrievalAugmentationAdvisor API:
<!-- pom.xml 添加依赖 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>
// Spring AI 最新 RAG API —— RetrievalAugmentationAdvisor
@Configuration
public class RagConfig {
@Bean
public Advisor retrievalAugmentationAdvisor(VectorStore vectorStore,
ChatClient.Builder chatClientBuilder) {
return RetrievalAugmentationAdvisor.builder()
// 可选:Query 改写,提高检索召回率
.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder.build().mutate())
.build())
// 文档检索器:从向量库检索相似文档
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
}
}
@Service
public class KnowledgeQAService {
@Autowired
private ChatClient chatClient;
@Autowired
private Advisor ragAdvisor;
public String ask(String question) {
return chatClient.prompt()
.advisors(ragAdvisor)
.user(question)
.call()
.content();
}
}
注意 Spring AI 最新的 RAG 模块化架构——RetrievalAugmentationAdvisor 支持 Query 改写、文档检索、上下文增强等各个环节独立配置,比之前的 QuestionAnswerAdvisor 灵活很多。
第三层:微调——需要模型 "内化" 能力的时候
微调是成本最高的方案,但有些场景确实只有微调能搞定。
适合的场景:
- 风格/语气定制:让模型用特定的品牌语气、行业术语回答
- 特定格式输出:模型需要稳定输出某种复杂格式(如法律合同、医学报告)
- 领域推理能力:需要模型在特定领域具备更强的推理能力(不只是知识,而是 "思维模式")
- 降低推理成本:微调后的小模型在某些任务上可以达到甚至超过未微调的大模型,推理成本大幅降低
- 延迟敏感场景:微调后的模型不需要检索步骤,推理更快
// 提示工程 vs 微调的典型对比:
// 场景 —— 让模型输出特定格式的法律文书
// ====== 方案 A:纯提示工程(能做,但不稳定)======
String prompt = """
请根据以下案件信息,生成一份民事起诉状。
严格按照以下格式输出:{格式模板}
案件信息:{caseInfo}
""";
// 问题:格式可能偶尔出错,复杂案件推理不够专业
// ====== 方案 B:微调后(稳定且专业)======
// 在大量法律文书数据上微调后的模型,直接调用即可
String prompt = "请根据以下案件信息生成民事起诉状:\n" + caseInfo;
// 微调后的模型已经 "内化" 了法律文书的格式和专业推理能力
// 输出稳定,格式准确,推理专业
第四层:组合使用——实际项目的常态
在真实项目中,三者的关系从来不是 "三选一",而是 层层叠加。
一个典型的企业 AI 客服系统:
- 提示工程:定义客服的角色、语气、回答规范
- RAG:检索产品手册、FAQ、售后政策
- 微调:让模型掌握专业的客服话术和行业术语
// 组合示例:提示工程 + RAG + 微调模型
@Service
public class CustomerServiceBot {
@Autowired
private ChatClient chatClient;
@Autowired
private Advisor ragAdvisor;
// 使用微调后的模型(通过 Spring AI 配置指向微调模型端点)
public String answer(String userQuestion) {
return chatClient.prompt()
// 提示工程:定义角色和规则
.system("""
你是 XX 公司的专业客服。
回答要求:
1. 语气亲切专业,使用敬语
2. 基于检索到的产品资料回答
3. 不确定的问题如实告知,不编造
4. 涉及退换货政策时,引用具体条款
""")
// RAG:检索知识库
.advisors(ragAdvisor)
.user(userQuestion)
.call()
.content();
}
}
三、2025-2026 年的新趋势
这块面试时提一嘴,绝对是加分项。
1. CAG(Cache-Augmented Generation)兴起
随着 Gemini 等模型支持 100 万+ Token 的上下文窗口,一种新的思路出现了——CAG(上下文缓存增强生成)。如果你的知识库足够小(能塞进上下文窗口),直接把全部知识预加载到上下文里,省掉向量检索环节,延迟更低。
但注意,CAG 目前只适合 知识库较小且相对稳定 的场景,大规模企业级应用还是 RAG 的天下。
2. Agentic RAG
RAG 不再只是 "检索→生成" 的单轮流程,而是演变成 Agent 驱动的多轮检索——模型可以自主决定要不要检索、检索什么、检索结果够不够、要不要换策略重新检索。Spring AI 的 RetrievalAugmentationAdvisor 已经支持这种模块化的高级 RAG 流程。
3. LoRA/QLoRA 让微调门槛大幅降低
2025 年 LoRA、QLoRA 等参数高效微调方法已经非常成熟。以前微调一张 A100 都不够用,现在消费级显卡就能搞定 7B 模型的 LoRA 微调。这意味着 "微调成本高" 这个劣势正在被快速缩小。
四、常见误区
- 误区一:"知识量大就一定要微调" —— 错!知识量大更应该用 RAG,微调不适合记忆大量具体事实。
- 误区二:"RAG 可以解决一切" —— 错!RAG 管的是知识,不是能力。如果模型本身的推理能力不够,检索再多资料也没用。
- 误区三:"微调后的模型不需要 RAG" —— 不一定。微调提升的是模型的能力和风格,但知识可能仍然过时。很多场景下 "微调模型 + RAG" 才是最优解。
面试高频追问
-
追问一:你们的 RAG 效果不好,你会怎么排查和优化?
先定位问题环节——是检索召回率低(检索不到相关文档),还是生成质量差(检索到了但回答不好)。检索问题:优化 Chunk 策略、换更好的 Embedding 模型、加 Rerank、用 Hybrid Search。生成问题:优化 Prompt 模板、换更强的 LLM、调整 Top-K 参数。
-
追问二:微调需要多少数据?数据质量怎么看?
LoRA 微调通常几百到几千条高质量数据就能看到效果。数据质量比数量重要——脏数据微调出来的模型反而更差。关键是数据要覆盖目标场景的多样性,格式要统一。
-
追问三:RAG 的延迟怎么优化?
向量索引优化(HNSW 参数调优)、Embedding 结果缓存、流式输出、减少 Top-K 数量、用更轻量的 Rerank 模型、异步预加载等。
常见面试变体
- 变体一:"在你们的项目中,为什么选择 RAG 而不是微调?"
- 变体二:"RAG 和微调可以同时使用吗?什么场景下需要组合?"
- 变体三:"如果预算有限,只能选一种方案,你会选哪个?"
- 变体四:"提示工程的局限性是什么?什么时候必须上 RAG?"
记忆口诀
选型三步曲:先 Prompt 再 RAG 最后微调。一句话定位:提示工程管 "指令",RAG 管 "知识",微调管 "能力"。
总结
RAG、微调、提示工程不是 "三选一" 的关系,而是层层递进的工具箱——从最轻量的提示工程开始尝试,需要外部知识上 RAG,需要深度定制能力加微调,实际项目中三者组合使用才是常态。面试时重点讲清楚决策逻辑和项目实战经验,不要干巴巴背概念。