Dubbo 的 SPI 和 JDK 的 SPI 有什么区别?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
SPI 概念理解:面试官首先想确认你是否知道 SPI 是什么、解决什么问题。如果你连 "Service Provider Interface" 的全称都说不出来,那基本就凉了。
-
JDK SPI 的局限性:面试官想看你是否踩过 JDK SPI 的坑——全量加载导致资源浪费、没有 IOC 和 AOP 支持、配置方式原始。如果你能说出 "JDK SPI 会一次性加载所有实现类,即使你只需要其中一个",面试官会眼前一亮。
-
Dubbo SPI 的增强设计:这道题的终极考察点——你是否理解 Dubbo 为什么不用 JDK 原生 SPI,而是自己造了一套。能说出按需加载、依赖注入、自适应扩展、自动激活这几个增强点,说明你是真的读过源码。
核心答案
先说结论:Dubbo SPI 是对 JDK SPI 的增强版,核心区别可以一张表说清楚:
| 特性 | JDK SPI | Dubbo SPI |
|---|---|---|
| 配置文件路径 | META-INF/services/ |
META-INF/dubbo/ |
| 配置格式 | 全限定类名,每行一个 | key=value 格式,如 dubbo=org.apache.dubbo... |
| 加载方式 | 全量加载所有实现类 | 按需加载,通过 key 获取指定实现 |
| 依赖注入(IOC) | 不支持 | 支持,自动注入依赖组件 |
| AOP 增强 | 不支持 | 支持 Wrapper 包装机制 |
| 自适应扩展 | 不支持 | @Adaptive 注解,运行时动态选择实现 |
| 自动激活 | 不支持 | @Activate 注解,条件自动加载 |
| 获取扩展点 | ServiceLoader.load() |
ExtensionLoader.getExtensionLoader() |
一句话概括:JDK SPI 是 "一把梭全加载",Dubbo SPI 是 "要啥加载啥,还能自动装配"。
深度解析
一、JDK SPI 的工作方式
先回顾一下 JDK SPI 怎么用的,后面对比才更清晰。
SPI 的全称是 Service Provider Interface,是 JDK 提供的一种服务发现机制。本质就是:接口定义在 A 模块,实现在 B 模块,运行时通过配置文件找到实现类。
// 1. 定义接口
public interface Serialization {
byte[] serialize(Object obj);
Object deserialize(byte[] data);
}
// 2. 提供实现类
public class JsonSerialization implements Serialization {
@Override
public byte[] serialize(Object obj) {
// JSON 序列化实现
}
@Override
public Object deserialize(byte[] data) {
// JSON 反序列化实现
}
}
public class HessianSerialization implements Serialization {
@Override
public byte[] serialize(Object obj) {
// Hessian 序列化实现
}
@Override
public Object deserialize(byte[] data) {
// Hessian 反序列化实现
}
}
// 3. 在 META-INF/services/ 下创建配置文件
// 文件名:com.example.Serialization
// 文件内容(全限定类名,每行一个):
// com.example.JsonSerialization
// com.example.HessianSerialization
// 4. 使用 ServiceLoader 加载
ServiceLoader<Serialization> loader = ServiceLoader.load(Serialization.class);
for (Serialization ser : loader) {
// 问题是:所有实现类都会被实例化,即使你只想用 JsonSerialization
System.out.println(ser.getClass().getName());
}
JDK SPI 的问题很明显:
-
全量加载:遍历
ServiceLoader的时候,所有实现类都会被实例化。假设你有 20 个序列化实现,只想用其中一个,不好意思,20 个全给你 new 出来了。如果某个实现类初始化很重(比如连接数据库),这就是纯纯的资源浪费。 -
没有 IOC:实现类里如果依赖了其他组件,JDK SPI 不会帮你注入,你得自己处理依赖关系。
-
没有 AOP:你没法在不修改实现类的前提下给它加功能(比如加个日志、加个监控),不支持装饰器模式。
二、Dubbo SPI 的按需加载
Dubbo SPI 把配置文件改成了 key=value 格式,支持按 key 精确加载:
// 配置文件路径:META-INF/dubbo/com.example.Serialization
// 内容格式(key=value):
// json=com.example.JsonSerialization
// hessian=com.example.HessianSerialization
// fastjson=com.example.FastJsonSerialization
// 使用 Dubbo SPI 按需加载
Serialization jsonSer = ExtensionLoader
.getExtensionLoader(Serialization.class)
.getExtension("json"); // 只加载 json 对应的实现类
看到了吧?传一个 "json" 进去,只实例化 JsonSerialization,其他两个实现类根本不会被加载。这就是按需加载。
Dubbo SPI 的核心 API 是 ExtensionLoader,常用的方法有这几个:
| 方法 | 作用 | 示例 |
|---|---|---|
getExtension("key") |
按 key 获取指定扩展实现 | getExtension("json") |
getDefaultExtension() |
获取 @SPI 注解指定的默认实现 |
获取 @SPI("hessian") 的默认值 |
getAdaptiveExtension() |
获取自适应扩展实现 | 运行时根据 URL 参数动态选择 |
getActivateExtension() |
获取满足条件的自动激活扩展 | 根据 group、value 条件筛选 |
getSupportedExtensions() |
获取所有已注册的扩展 key | 返回 [json, hessian, fastjson] |
三、Dubbo SPI 的依赖注入
Dubbo SPI 支持在扩展实现类中注入其他扩展点,类似 Spring 的 @Autowired:
// Dubbo 自带的 Protocol 扩展示例
public class DubboProtocol implements Protocol {
// ExtensionLoader 会自动注入这个依赖
private ExchangeHandler handler;
// 通过 setter 方法注入,不是通过字段注入
public void setHandler(ExchangeHandler handler) {
this.handler = handler;
}
}
ExtensionLoader 在实例化扩展类之后,会扫描它的 setter 方法,如果参数类型是另一个扩展点接口,就自动把对应的扩展实现注入进来。这个设计思路和 Spring 的依赖注入一模一样,只不过 Dubbo 自己实现了一套轻量版本。
四、自适应扩展 @Adaptive
这个是 Dubbo SPI 最强大的特性之一,也是面试官最爱追问的。
啥叫 "自适应"?就是 在运行时根据参数动态决定用哪个实现类,而不是在编译期写死。
// SPI 接口上标注 @Adaptive
@SPI("dubbo")
public interface Protocol {
@Adaptive
void export(URL url);
@Adaptive
<T> T refer(Class<T> type, URL url);
}
// 运行时 Dubbo 会根据 URL 中的 protocol 参数动态选择实现
// 如果 URL 是 dubbo://192.168.1.1:20880/...,就用 DubboProtocol
// 如果 URL 是 rest://192.168.1.1:8080/...,就用 RestProtocol
Dubbo 会为带有 @Adaptive 注解的接口方法自动生成一个代理类(或者手动指定代理类)。这个代理类会读取 URL 中的参数值,然后动态选择对应的扩展实现。
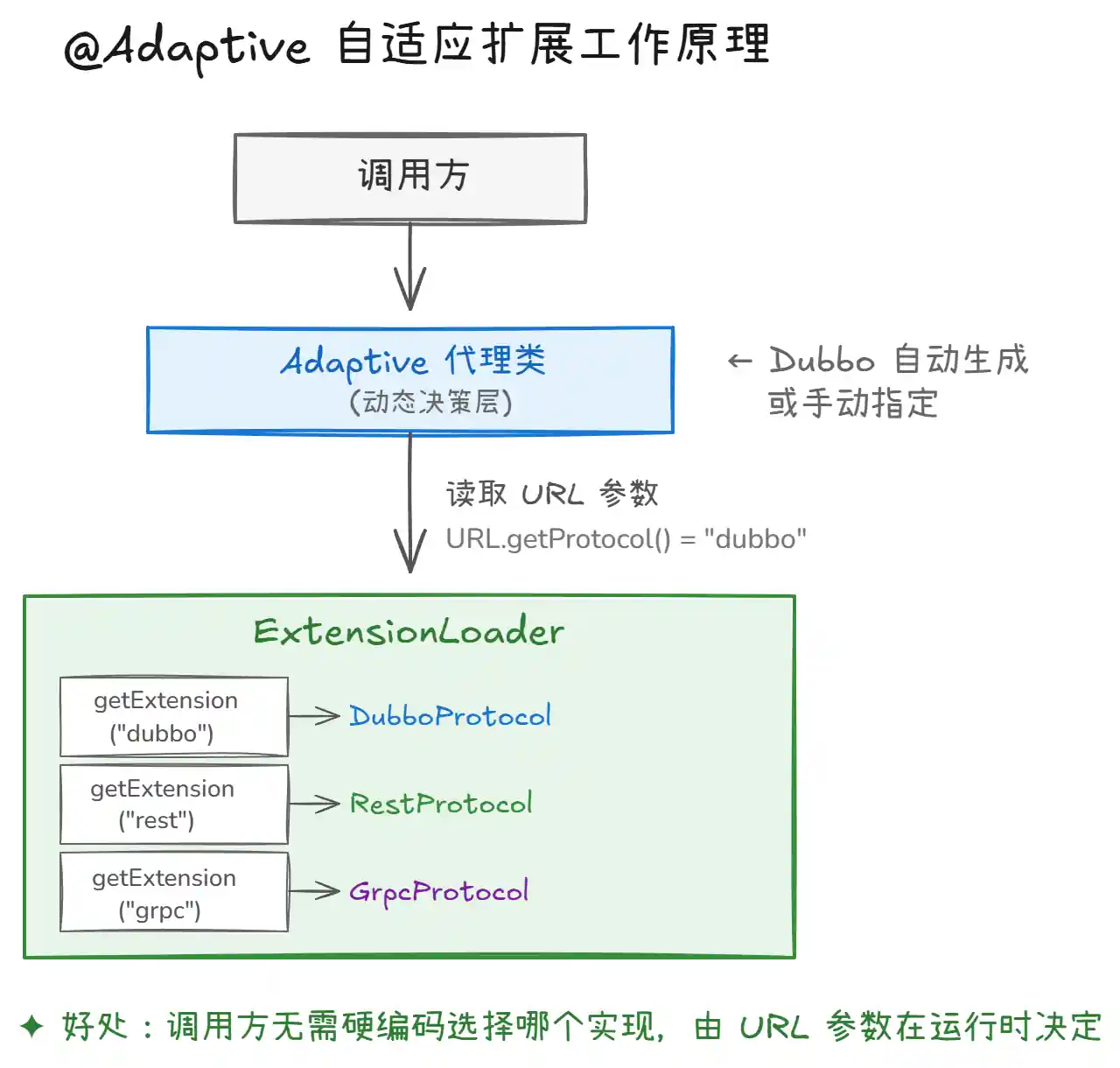
上图展示了 @Adaptive 的工作原理:
-
调用方发起调用时,不会直接和某个具体的
Protocol实现类打交道,而是调用Adaptive代理类。 -
代理类从
URL参数中提取协议类型(比如dubbo、rest、grpc),然后通过ExtensionLoader.getExtension()按需获取对应的实现类。 -
最终执行的是真正实现类的逻辑,整个过程对调用方完全透明。
这个设计的好处是什么?你写一个通用逻辑,不用 if-else 去判断 "如果协议是 dubbo 就用 DubboProtocol,如果是 rest 就用 RestProtocol"——全都由自适应扩展在运行时自动搞定。说实话,这个设计确实优雅。
五、自动激活 @Activate
@Activate 注解用于标记那些需要 "条件触发" 的扩展,最典型的场景就是 Filter 链。
// Dubbo 内置的消费者端日志 Filter
@Activate(group = CommonConstants.CONSUMER)
public class ConsumerTraceFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) {
// 自动记录调用链路日志
return invoker.invoke(invocation);
}
}
// 当你是 Consumer 端时,这个 Filter 会自动被加载到 Filter 链中
// 不需要你手动配置,@Activate(group = "consumer") 帮你搞定了
@Activate 支持多种条件匹配:
| 属性 | 作用 |
|---|---|
group |
匹配 Consumer 或 Provider 端 |
value |
匹配 URL 中的 key |
order |
控制多个激活扩展的执行顺序 |
before |
在指定扩展之前执行 |
after |
在指定扩展之后执行 |
六、Wrapper 机制(AOP 增强)
Dubbo SPI 还支持 Wrapper 包装,可以在不修改原始实现类的前提下给它加功能:
// 原始 Protocol 实现
public class DubboProtocol implements Protocol {
public void export(URL url) {
// 真正的服务暴露逻辑
}
}
// Wrapper 包装类(实现相同接口 + 构造函数接收原始实例)
public class ProtocolListenerWrapper implements Protocol {
private Protocol protocol; // 持有原始实例
public ProtocolListenerWrapper(Protocol protocol) {
this.protocol = protocol;
}
public void export(URL url) {
// 前置增强:记录日志、添加监听器等
protocol.export(url);
// 后置增强:通知监听器
}
}
ExtensionLoader 发现构造函数只有一个参数且为接口类型时,会自动把它当成 Wrapper,在原始实例外面套一层。可以套多层,形成装饰器链。
这就是 Dubbo SPI 的 AOP 能力,和 Spring 的 AOP 思路一样,但实现更轻量。
面试高频追问
-
Dubbo SPI 为什么要自己造一套,不用 JDK 的?
就是因为 JDK SPI 全量加载太浪费资源,而且不支持 IOC 和 AOP。Dubbo 作为一个高性能 RPC 框架,对扩展点的加载效率和控制粒度要求很高,JDK SPI 满足不了,所以自己搞了一套。
-
@Adaptive注解加在类上和加在方法上有什么区别?加在方法上:Dubbo 会自动生成一个代理类(代码是拼接字符串生成的
.java文件然后编译),在代理类里根据 URL 参数动态选择实现。加在类上:直接用这个类作为自适应实现,不再生成代理类。Dubbo 里只有AdaptiveCompiler和AdaptiveExtensionFactory是加在类上的,其余都加在方法上。 -
Dubbo SPI 的配置文件除了
META-INF/dubbo/,还会扫描哪些目录?Dubbo 3.x 会依次扫描三个目录:
META-INF/dubbo/、META-INF/services/、META-INF/dubbo/internal/。其中internal目录放的是 Dubbo 内置的扩展实现,services目录是为了兼容 JDK SPI 的配置格式。 -
Dubbo 里有哪些核心扩展点是通过 SPI 实现的?
Protocol(协议)、Serialization(序列化)、Transport(网络传输)、Registry(注册中心)、LoadBalance(负载均衡)、Cluster(集群容错)、Filter(过滤器)、Monitor(监控)——基本你能想到的组件全是通过 SPI 扩展的。
常见面试变体
- "Dubbo 为什么不用 JDK 原生的 SPI?"
- "Dubbo SPI 的
@Adaptive注解是做什么的?" - "Dubbo 的扩展点机制是怎么实现的?"
- "说一下 Dubbo SPI 的加载流程"
记忆口诀
Dubbo SPI 六大增强:按需加载省资源,依赖注入解耦合,自适应选实现,自动激活上 Filter,Wrapper 做 AOP,key=value 好配置。
总结
Dubbo SPI 相比 JDK SPI,核心优势就三件事:按需加载避免资源浪费、IOC + AOP 让扩展点具备完整的依赖注入和装饰器能力、@Adaptive 自适应扩展让运行时动态选择实现变得优雅。把这几条说清楚,面试官就知道你不是只停留在 "用过 Dubbo" 的层面,而是真的理解它的设计精髓。