Dubbo 支持哪些序列化方式?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
基础掌握度:面试官不仅仅想知道你能列举几种序列化方式,更想知道你是否理解每种方式的优缺点和适用场景,能否在项目中做出合理选型。
-
性能意识:序列化是 RPC 调用链路上最耗时的环节之一。面试官想看你是否具备性能优化的思维,是否知道不同序列化方式在速度、体积、兼容性上的差异。
-
架构视野:优秀的候选人应该能从 Dubbo 的 SPI 扩展机制角度理解序列化的可插拔设计,而不是死记硬背几个名字。
核心答案
Dubbo 支持多种序列化方式,通过 SPI 机制实现可插拔扩展。以下是主流的几种:
| 序列化方式 | 实现类 | 速度 | 体积 | 跨语言 | 推荐场景 |
|---|---|---|---|---|---|
| Hessian2 | Hessian2Serialization |
中等 | 较小 | 支持 | Dubbo 默认,通用场景 |
| FastJson | FastJsonSerialization |
中等 | 中等 | 支持 | 需要可读性的场景 |
| Kryo | KryoSerialization |
快 | 小 | 不支持 | Java 纯内网高性能场景 |
| FST | FstSerialization |
快 | 小 | 不支持 | Java 纯内网高性能场景 |
| Protobuf | ProtobufSerialization |
快 | 最小 | 支持 | 跨语言、对体积敏感 |
| MessagePack | — | 较快 | 较小 | 支持 | 跨语言轻量场景 |
| JDK | JavaSerialization |
慢 | 大 | 不支持 | 兼容性兜底(不推荐) |
Dubbo 2.x 默认使用 Hessian2,Dubbo 3.x 开始推荐使用 Triple 协议 + Protobuf。
深度解析
一、为什么序列化这么重要?
RPC 调用的核心流程中,序列化和反序列化是必经环节,而且往往是性能瓶颈:
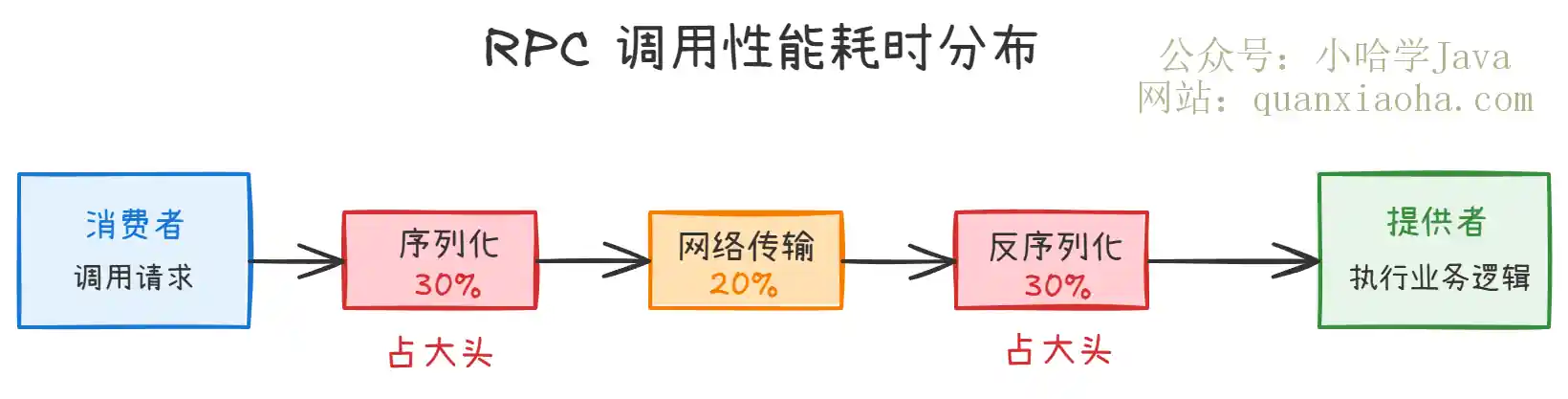
上图展示了 RPC 调用中各环节的耗时分布。可以看到:
- 序列化 + 反序列化加起来能占到一次 RPC 调用耗时的 60% 左右,远超网络传输本身
- 这也是为什么选择合适的序列化方式对系统性能影响巨大
- 同样的业务逻辑,换一种序列化方式,吞吐量可能差出好几倍
二、主流序列化方式对比详解
1. Hessian2(默认)
Dubbo 默认的序列化方式,也是经过生产环境大规模验证的。
<!-- 默认就是 hessian2,可以不配 -->
<dubbo:protocol serialization="hessian2" />
优点:
- 跨语言支持:Hessian 协议本身设计就支持多语言
- 成熟稳定:在 Dubbo 生态里用了这么多年,坑基本踩平了
- 体积适中:二进制格式,比 JDK 序列化小很多
缺点:
- 性能比 Kryo、FST 这类要慢
- 对复杂对象的支持偶尔会有坑(比如泛型擦除问题)
2. Kryo / FST(高性能之选)
如果你的服务是纯 Java 技术栈,不需要跨语言,Kryo 和 FST 是性能最优的选择。
<!-- 使用 Kryo 序列化 -->
<dubbo:protocol serialization="kryo" />
<!-- 使用 FST 序列化 -->
<dubbo:protocol serialization="fst" />
使用 Kryo 时有个细节需要注意——需要注册类:
// 注册类以获得更好的性能
public class KryoSerializationOptimizer implements SerializationOptimizer {
@Override
public Collection<Class> getSerializableClasses() {
List<Class> classes = new ArrayList<>();
classes.add(User.class);
classes.add(Order.class);
// 把你业务中常用的 DTO 都注册进来
return classes;
}
}
注册类之后,Kryo 会用整数 ID 代替完整的类名,序列化体积更小、速度更快。这个优化点很多同学不知道,面试的时候提一嘴,加分。
3. Protobuf(Dubbo 3.x 的推荐方案)
Dubbo 3.x 推出了 Triple 协议(基于 HTTP/2,兼容 gRPC),默认使用 Protobuf 序列化。
// 定义 proto 文件
syntax = "proto3";
package com.example;
message UserRequest {
int64 id = 1;
}
message UserResponse {
int64 id = 1;
string name = 2;
string email = 3;
}
// Dubbo 3.x 使用 Protobuf 的方式
@DubboService
public class UserServiceImpl implements UserService {
@Override
public UserResponse getUser(UserRequest request) {
// 业务逻辑
}
}
为什么 Dubbo 3.x 要转向 Protobuf?
- 跨语言:gRPC 生态天然支持多语言,Dubbo 要融入云原生时代,跨语言是刚需
- 高性能:Protobuf 的编解码速度和压缩率都是顶级的
- IDL 定义:通过
.proto文件明确定义接口,比 Java 接口更规范,天然支持版本演进 - 云原生友好:Triple 协议兼容 gRPC,可以和 Kubernetes、Service Mesh 等基础设施更好地集成
4. JDK 序列化(别用)
<!-- 不推荐 -->
<dubbo:protocol serialization="java" />
面试的时候如果提一嘴 "JDK 序列化性能差、体积大、还有安全风险",面试官会认为你有实际经验。JDK 序列化的主要问题:
- 性能非常慢,比 Hessian2 慢好几倍
- 序列化后的体积很大
- 存在反序列化安全漏洞风险
- 无法跨语言
三、如何选型?
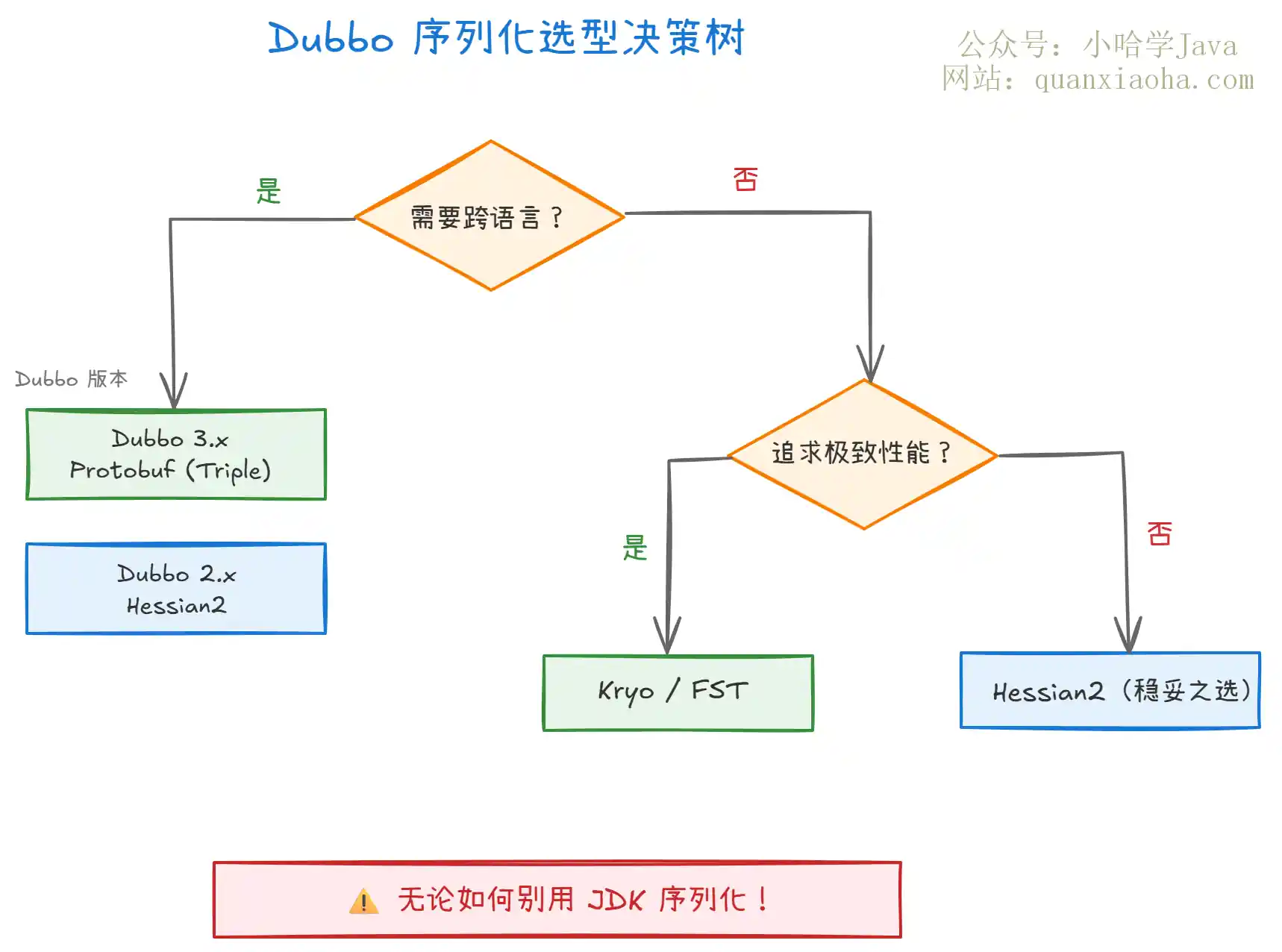
上图是选型决策树,简单总结一下就是:
- 跨语言需求:Dubbo 3.x 首选 Protobuf + Triple 协议;Dubbo 2.x 用 Hessian2
- 纯 Java 高性能:选 Kryo 或 FST,记得注册类优化
- 通用稳妥:Hessian2,不折腾
- JDK 序列化:永远别用
四、Dubbo SPI 扩展机制
Dubbo 的序列化之所以能做到可插拔,核心在于 SPI(Service Provider Interface)机制:
// Dubbo 的 Serialization SPI 接口
@SPI("hessian2") // 默认使用 hessian2
public interface Serialization {
byte getContentTypeId();
ObjectOutput serialize(URL url, OutputStream output) throws IOException;
ObjectInput deserialize(URL url, InputStream input) throws IOException;
}
这意味着你也可以实现自己的序列化方式:
// 自定义序列化实现
public class MySerialization implements Serialization {
@Override
public byte getContentTypeId() {
return 20; // 自定义 ID,避免冲突
}
@Override
public ObjectOutput serialize(URL url, OutputStream output) {
return new MyObjectOutput(output);
}
@Override
public ObjectInput deserialize(URL url, InputStream input) {
return new MyObjectInput(input);
}
}
然后在 META-INF/dubbo/ 目录下配置 SPI:
com.alibaba.dubbo.common.serialize.Serialization
my=com.example.MySerialization
使用时指定即可:
<dubbo:protocol serialization="my" />
这块面试的时候可以顺带提一下 SPI 机制,体现你对 Dubbo 架构设计的理解。
面试高频追问
-
Dubbo 3.x 为什么推荐 Protobuf?
因为 Triple 协议基于 HTTP/2 且兼容 gRPC,Protobuf 是 gRPC 的标配序列化方案,性能好、跨语言、IDL 规范,适合云原生场景。
-
序列化对接口性能影响有多大?
实测中,把 Hessian2 换成 Kryo,吞吐量能提升 30%~50%,延迟降低 20%~30%(数据跟对象复杂度有关)。对于高并发场景,这个提升非常可观。
-
Kryo 的类注册有什么作用?
不注册类时,Kryo 用完整类名做标识,体积大、速度慢。注册后用整数 ID 代替类名,体积更小,序列化/反序列化速度也更快。
-
Dubbo 的序列化能动态切换吗?
可以。通过
<dubbo:protocol>或<dubbo:service>级别配置serialization参数,不同服务可以用不同的序列化方式。Dubbo 通过 SPI 机制运行时动态加载。
常见面试变体
- "Dubbo 默认的序列化方式是什么?为什么选它?"
- "Dubbo 3.x 的 Triple 协议用的什么序列化?和 Dubbo 协议有什么区别?"
- "如何提升 Dubbo 的序列化性能?"
- "Dubbo 的 SPI 机制是怎么实现的?"
记忆口诀
默认 Hessian2,跨语言上 Protobuf,纯 Java 选 Kryo,JDK 序列化千万别用。
总结
Dubbo 通过 SPI 机制支持多种序列化方式,2.x 默认 Hessian2,3.x 推荐 Protobuf + Triple。选型看三个维度:是否跨语言、性能要求、生态兼容。面试的时候把选型逻辑讲清楚,再顺带提一嘴 SPI 扩展机制和 Kryo 类注册优化,基本就够了。