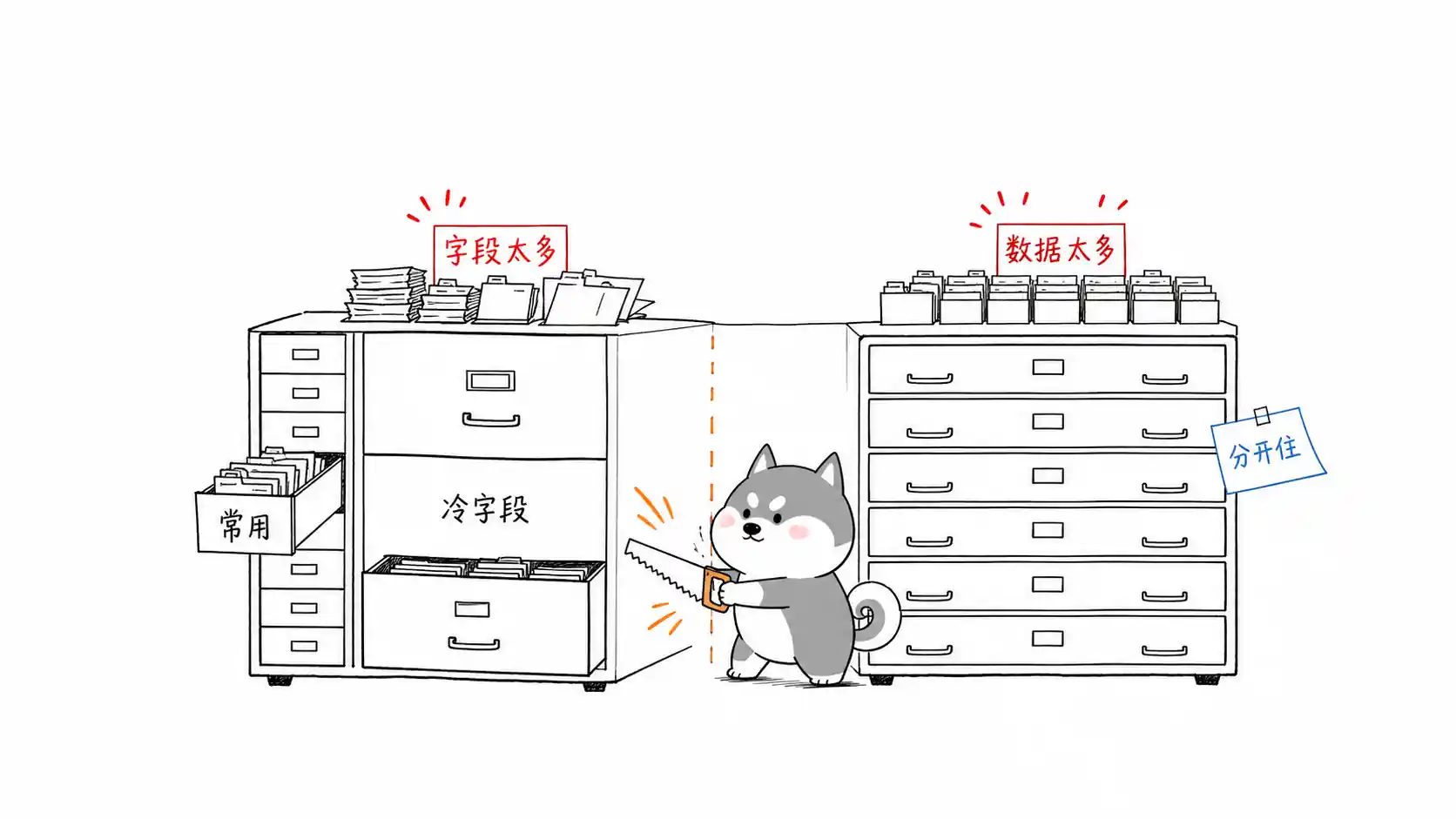
什么是分库?分表?分库分表?
面试常问:什么是分库、分表、分库分表?一句话总结:分表解决数据量过大,分库解决并发压力,分库分表解决海量数据与高并发。本文结合MySQL性能瓶颈,深度解析垂直与水平拆分区别、ShardingSphere落地实践及跨库Join、分布式ID等高频追问,帮你轻松拿下后端架构面试!
2026/7/21Java面试八股文
面试常问:什么是分库、分表、分库分表?一句话总结:分表解决数据量过大,分库解决并发压力,分库分表解决海量数据与高并发。本文结合MySQL性能瓶颈,深度解析垂直与水平拆分区别、ShardingSphere落地实践及跨库Join、分布式ID等高频追问,帮你轻松拿下后端架构面试!

Netty 是 Java 圈把设计模式用得最透的框架。本文深度剖析 Netty 源码中的 Reactor 模式与责任链模式核心架构,并结合具体类名解析建造者、策略、装饰器等高频面试考点。助你彻底搞懂 Netty 设计精髓,轻松拿下 Java 面试!
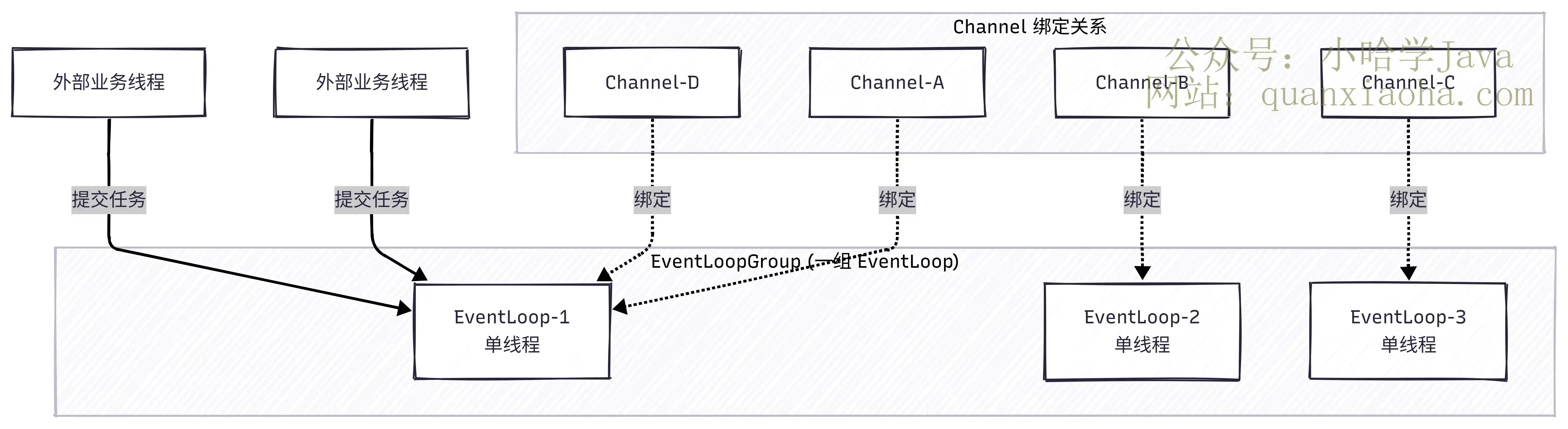
本文深度解析Netty无锁化设计原理。Netty并非完全无锁,其核心是通过Channel与EventLoop绑定实现单线程串行化,避免锁竞争。结合inEventLoop()判断与MpscQueue无锁队列,高效处理跨线程任务。掌握这套线程模型与面试核心考点,助你轻松应对大厂面试追问。
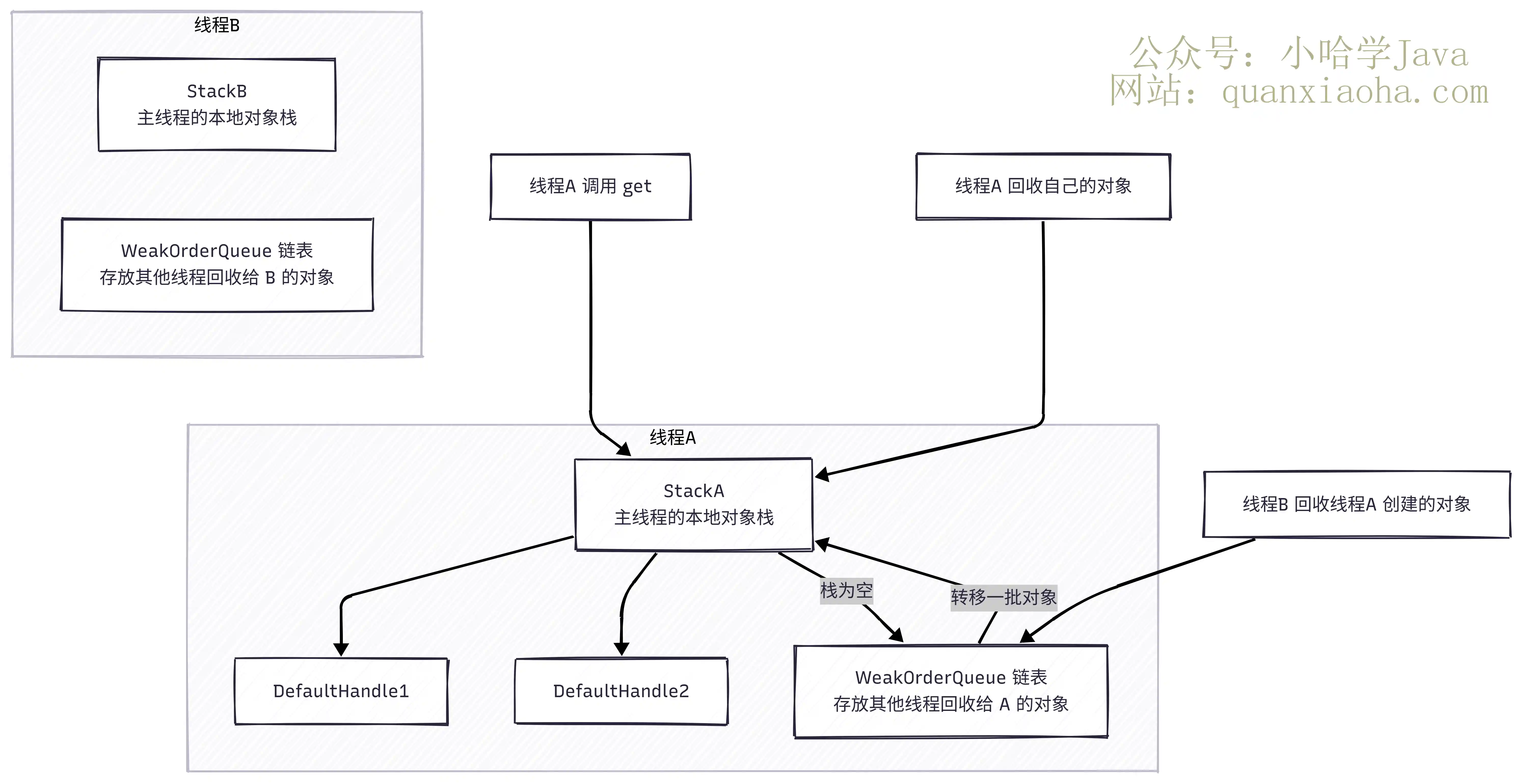
深入解析 Netty 的对象池技术,探讨如何通过 Recycler 机制有效降低高频网络 IO 场景下的 GC 压力。本文详细拆解了 ThreadLocal、Stack、WeakOrderQueue 等核心组件的协作原理,并对比了 FastThreadLocal 与 MPSC 队列的性能优化点,助你从容应对相关 Java 面试题。

Netty 面试高频考点:为什么 Netty 放弃 NIO 的 ByteBuffer 而重新设计 ByteBuf?本文深度解析 ByteBuf 好用的核心原理:通过读写双指针分离告别 flip() 操作,采用 jemalloc 思想的内存池与引用计数机制大幅降低 GC 压力,并支持堆外内存与多种零拷贝实现,全面揭秘 Netty 高性能网络编程的底层设计,助你轻松拿下后端开发 Offer。
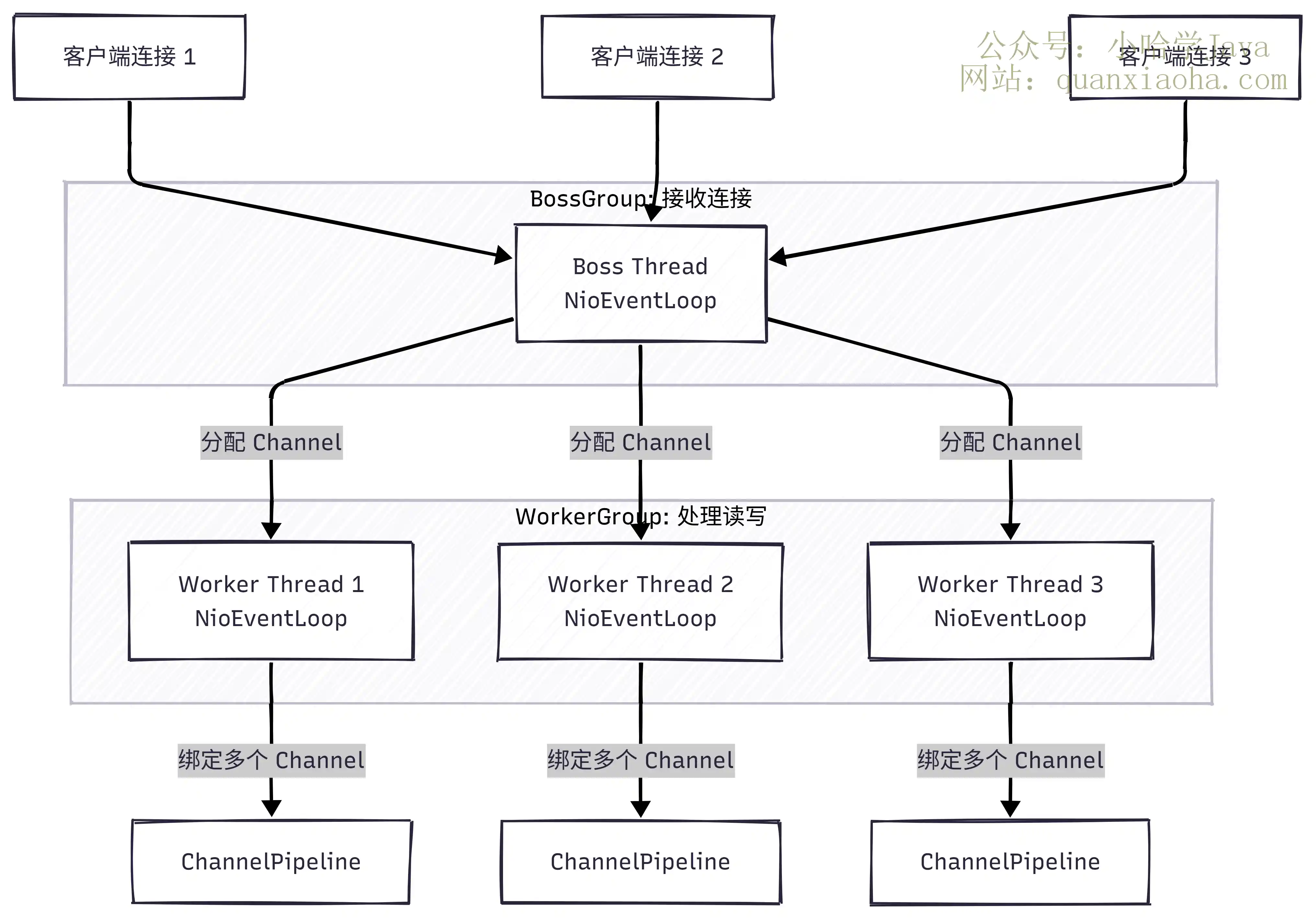
Netty的线程模型是怎么样的?本文深度解析Netty主从Reactor多线程模型的设计原理。详解BossGroup与WorkerGroup的分工,剖析NioEventLoop的底层运行机制,并带你彻底搞懂Netty如何通过Channel绑定EventLoop实现串行化无锁设计以提升高并发性能。涵盖生产配置与面试高频追问,干货满满,助你轻松拿下Offer。

本教程提供 Clion 2026.2 最新激活码与破解版安装教程,图文详解 Windows/Mac 系统破解补丁安装步骤,亲测可成功激活至 2099 年。内附激活脚本获取方式及常见问题解决方法,快来获取你的 Clion 破解补丁吧!

想获取 GoLand 2026.2 最新激活码?本文为您提供亲测有效的 GoLand 破解版安装教程,附带详细图文步骤与破解补丁脚本下载,支持 Win 与 Mac 系统,轻松将软件激活至 2099 年!立即查看如何安全破解,开启高效的开发之旅。

本教程提供 PhpStorm 2026.2 最新破解版安装与激活方法,内含亲测至2099年的有效激活码及补丁下载。详细图文指导Windows与Mac系统安装破解脚本、获取激活码,助您快速成功激活,仅供个人学习参考。

本文深入解析 Netty 零拷贝的实现原理,带你分清 OS 层零拷贝(FileRegion、sendfile、mmap)与应用层零拷贝(CompositeByteBuf、slice、DirectByteBuffer)的区别。剖析传统 IO 的性能瓶颈,掌握 ByteBuf 逻辑合并等核心机制,助你轻松应对面试高频追问,彻底搞懂 Netty 高吞吐底层逻辑。