Dubbo 的服务调用过程是什么样的?
面试考察点
- 整体架构认知:面试官不仅仅是想知道调用流程,更是想看你是否理解 Dubbo 的分层架构(Business、RPC、Remoting 三层),以及各层之间的职责边界。
- 核心组件理解:考察你是否清楚
Proxy、Invoker、Protocol、Filter、Cluster、LoadBalance、Exchange、Transport这些核心组件在调用链中各自扮演什么角色。 - 消费者端 vs 提供者端的对称性:一个加分项——能否分别从消费者发起请求和提供者处理请求两个视角,完整描述整个调用过程,而不是只说一半。
核心答案
先说结论:Dubbo 的一次完整服务调用,从消费者发起请求到提供者返回结果,经历 10 个核心步骤,涉及消费者端 5 步 + 提供者端 5 步。
| 阶段 | 步骤 | 核心组件 |
|---|---|---|
| 消费者初始化 | ① ReferenceConfig 引用服务 | ProxyFactory |
| 消费者发起调用 | ② Proxy → Invoker → Filter 链 | InvokerInvocationHandler |
| 集群容错 | ③ Cluster → Directory → Router | FailoverClusterInvoker |
| 负载均衡 | ④ LoadBalance 选出一个 Invoker | RandomLoadBalance 等 |
| 网络发送 | ⑤ Protocol → Exchanger → Transporter | DubboProtocol、NettyClient |
| 网络接收 | ⑥ Transporter → Exchanger → Protocol | NettyServer、DubboProtocol |
| 提供者处理 | ⑦ Filter 链 → Invoker → Proxy | ProxyFactory |
| 实际执行 | ⑧ 反射调用本地方法 | JavassistProxyFactory |
| 结果返回 | ⑨ 序列化结果 → 网络 | NettyServer |
| 消费者接收 | ⑩ 反序列化 → 返回给调用方 | NettyClient |
光看表格可能有点抽象,下面用一张大图把整个流程串起来。
深度解析
一、完整调用链全景图
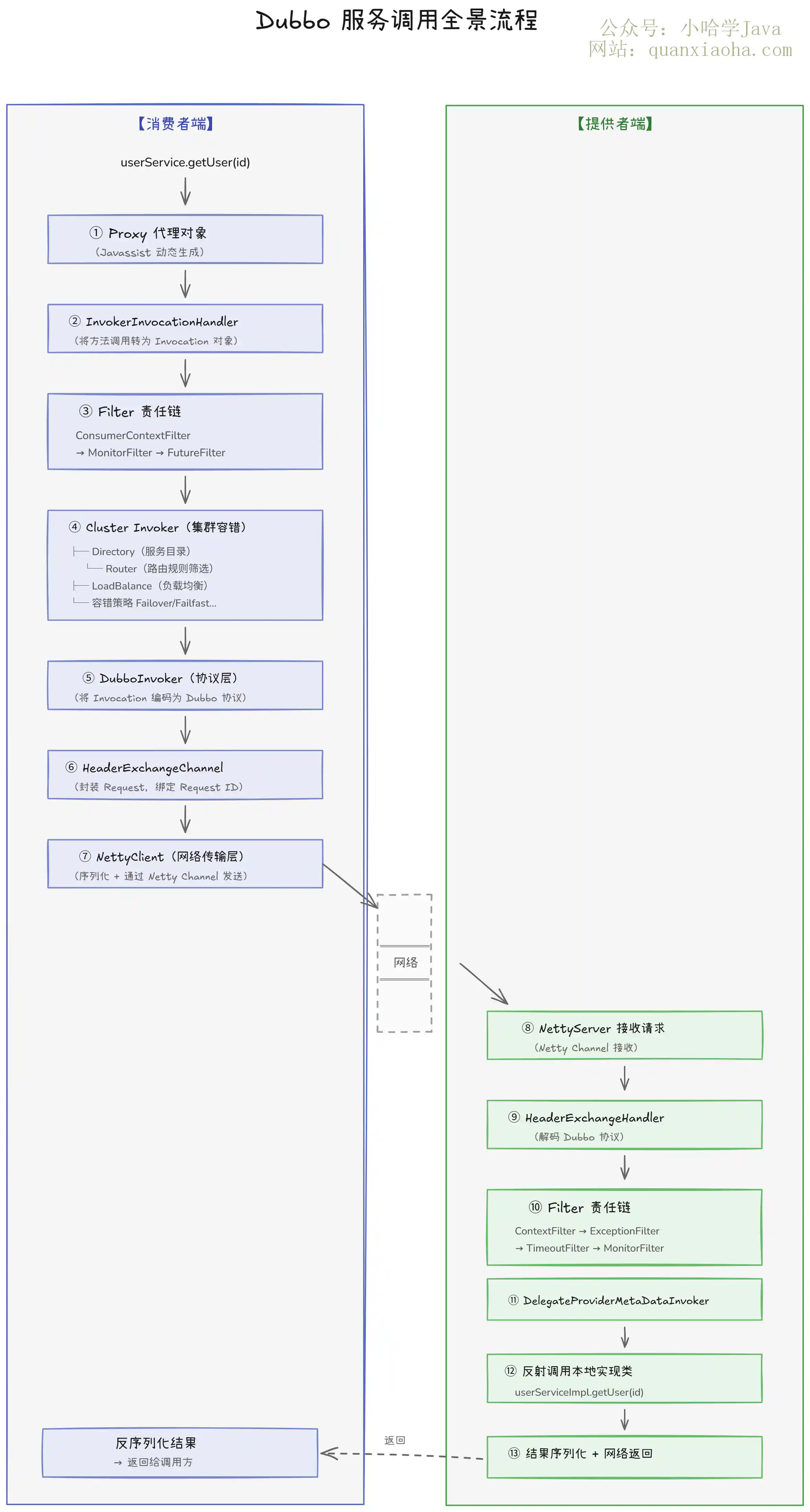
上图把 Dubbo 一次服务调用的完整链路画出来了。整体分为两大阶段:
- 消费者端(左半部分):从
Proxy代理对象开始,经过Filter链、集群容错、负载均衡、协议编码,最终通过Netty发送出去。 - 提供者端(右半部分):
NettyServer接收请求后,经过协议解码、Filter链处理,最终通过反射调用本地实现类,拿到结果后原路返回。
下面把几个关键环节单独拎出来讲。
二、消费者端详解
① Proxy 代理层——你看不到的 "中间人"
Dubbo 消费者端没有一个真正的 "UserService" 实现类,那 userService.getUser(id) 是怎么调通的呢?
答案是通过 动态代理。Dubbo 默认使用 Javassist 生成代理类(也支持 JDK 动态代理),在消费者端生成一个接口的代理对象。当你调用接口方法时,代理对象会把这个调用 "拦截" 下来,转换成一个 Invocation 对象(包含接口名、方法名、参数类型、参数值),然后丢给后续的调用链。
// 消费者代码,看起来像本地调用
@Service
public class OrderServiceImpl implements OrderService {
@DubboReference
private UserService userService; // 其实是个代理对象
public User getOrderUser(Long orderId) {
// 看着是本地调用,实际上被代理对象拦截了
return userService.getUser(orderId);
}
}
② Filter 责任链——调用链的 "安检流程"
Invocation 对象被创建后,首先经过的是消费者端的 Filter 链。Dubbo 的 Filter 机制基于责任链模式,每个 Filter 可以在调用前后插入自定义逻辑。
Dubbo 内置的消费者端 Filter 有:
ConsumerContextFilter:设置RpcContext的本地信息(如localAddress、remoteAddress)MonitorFilter:统计调用次数和耗时,上报监控中心FutureFilter:处理异步调用的回调通知
你也能自定义 Filter,比如加日志、做链路追踪、限流等。
③ Cluster——集群容错的 "大脑"
Filter 链执行完后,调用来到 Cluster 层。这一层非常关键,它负责处理 "多个提供者怎么选" 的问题。
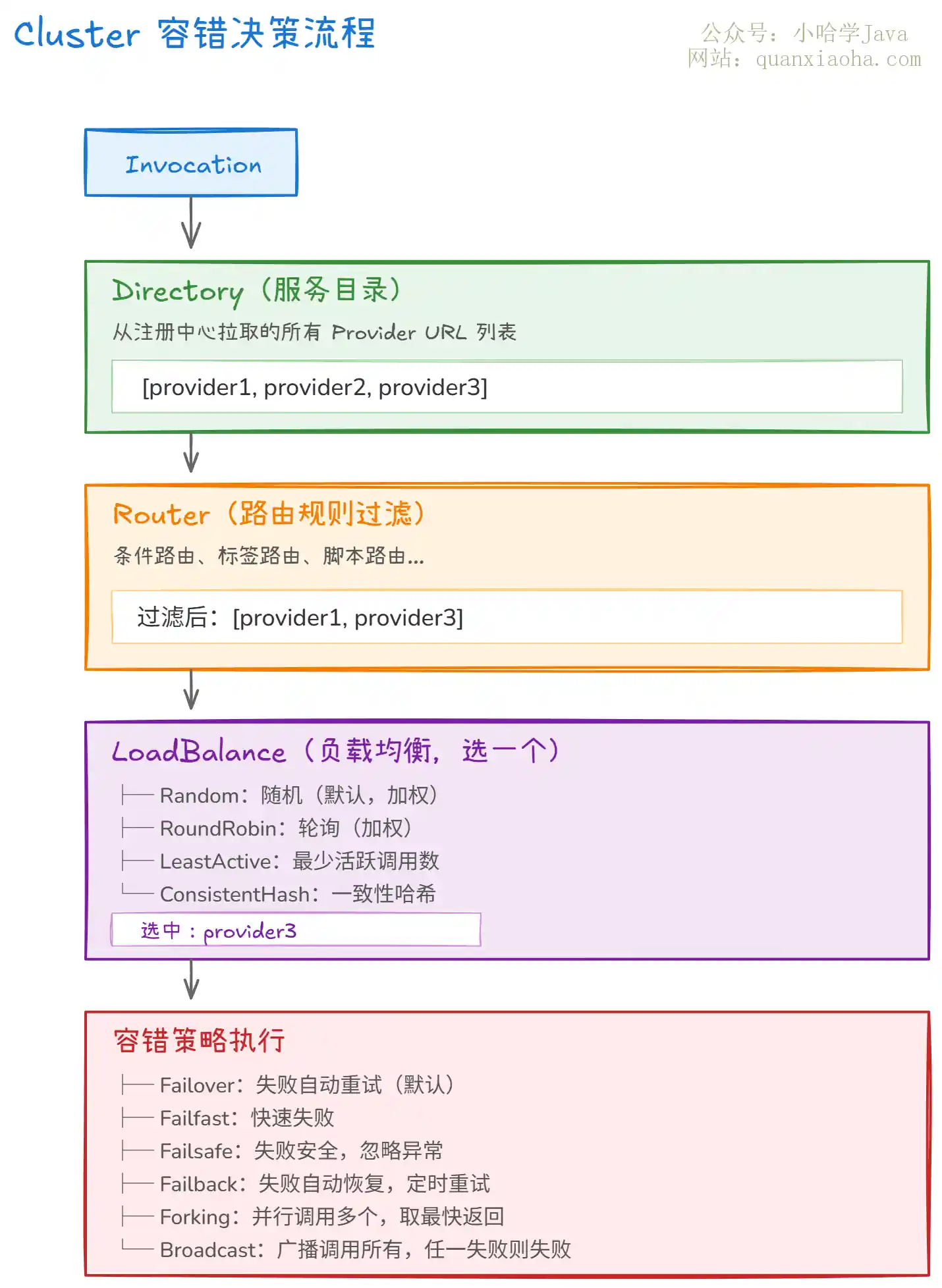
上图展示了 Cluster 层的决策过程,分三步走:
- 第一步,
Directory获取候选列表:Directory维护了从注册中心拉取的所有可用 Provider 列表。注册中心(Nacos、ZooKeeper 等)会通过长连接推送变更,Directory实时更新。 - 第二步,
Router路由过滤:如果你配置了路由规则(比如 "流量只打到同机房"、"灰度发布 10% 流量到新版本"),Router会根据规则过滤掉不符合条件的 Provider。这一步把候选列表从 N 个缩到 M 个。 - 第三步,
LoadBalance负载均衡:从过滤后的列表中,按负载均衡策略选出一个 Provider 来发起调用。Dubbo 默认用Random(加权随机),简单高效。
选好目标 Provider 后,就是实际的容错策略。默认的 FailoverClusterInvoker 在调用失败时会自动切换到其他 Provider 重试(默认重试 2 次,加上首次调用共 3 次)。
三、提供者端详解
请求经过网络到达提供者端后,处理流程大致是 "反着来" 的:
NettyServer接收字节流,经过 Dubbo 协议解码,还原成Invocation对象- 提供者端
Filter链 做一系列处理:ContextFilter:设置RpcContext的服务端信息ExceptionFilter:检查异常类型,防止自定义异常被包装成RuntimeExceptionTimeoutFilter:记录超时告警日志MonitorFilter:上报调用统计
AbstractProxyInvoker:最终的Invoker,内部通过反射调用本地实现类的方法
// 提供者端的最终执行,伪代码
public class AbstractProxyInvoker<T> implements Invoker<T> {
private final T proxy; // 本地实现类实例
private final Method method; // 要调用的方法
@Override
public Result invoke(Invocation invocation) {
// 通过反射调用实现类的方法
Object value = method.invoke(proxy, invocation.getArguments());
return new CompletableFuture<>(value);
}
}
拿到返回值后,结果经过序列化,通过 Netty Channel 原路返回给消费者端。消费者端的 NettyClient 接收响应,根据 Request ID 找到对应的挂起请求,反序列化结果,最终返回给业务代码。
整个过程,业务代码完全感知不到网络的存在,就像调用本地方法一样。这就是 RPC 的核心价值——远程调用的透明化。
四、Dubbo 分层架构速览
理解调用链之后,再看 Dubbo 的官方分层架构就清晰多了:
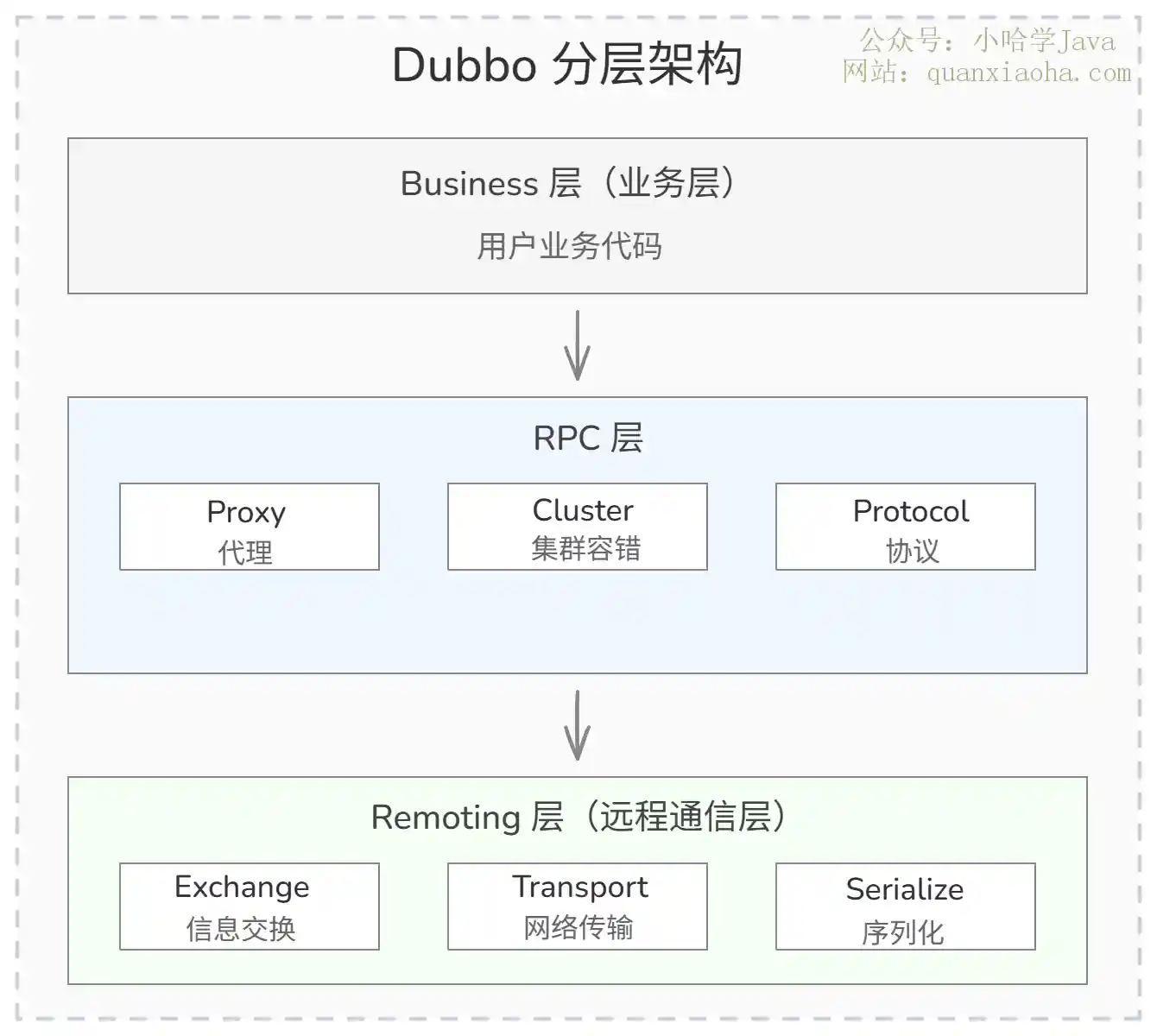
上图展示了 Dubbo 的三层架构,从上到下:
- Business 层:你的业务代码,调用接口就像调本地方法。
- RPC 层:封装了代理、集群容错、协议等 RPC 核心逻辑。消费者端的
Cluster、Filter、Proxy都在这一层。 - Remoting 层:最底层的通信基础设施,负责数据的序列化、网络传输、请求-响应的映射关系。
Netty就工作在这一层。
每一层只关注自己的职责,层与层之间通过接口解耦。这也是 Dubbo 设计得比较优雅的地方——你可以替换任意一层的实现(比如把 Netty 换成 Mina,把 Hessian 序列化换成 Protobuf),不影响其他层。
面试高频追问
-
追问一:Dubbo 默认的集群容错策略是什么?能换成别的吗?
默认是
Failover(失败自动重试,默认重试 2 次)。可以通过配置<dubbo:reference cluster="failfast"/>切换。读操作适合用Failover(重试不影响数据一致性),写操作建议用Failfast(快速失败,避免重复提交)。 -
追问二:Dubbo 的负载均衡算法有哪些?默认用哪个?
4 种:
Random(加权随机,默认)、RoundRobin(加权轮询)、LeastActive(最少活跃数)、ConsistentHash(一致性哈希)。默认Random,简单粗暴但有效。 -
追问三:Dubbo 调用是同步还是异步的?
底层基于 Netty 的 NIO,网络 IO 本身是异步的。但 Dubbo 默认给上层暴露的是同步调用语义——消费者线程发起请求后会
get()阻塞等待结果。Dubbo 2.7+ 也支持基于CompletableFuture的异步调用。 -
追问四:如果注册中心挂了,消费者还能调用提供者吗?
能。消费者本地缓存了 Provider 列表,注册中心挂了只是无法感知新的上下线变更,但已缓存的服务列表仍然可用。这也是为什么生产环境建议消费者端做本地缓存。
常见面试变体
- 变体一:"Dubbo 的调用链经过了哪些核心组件?"
- 变体二:"Dubbo 消费者发起一次 RPC 调用,中间经历了哪些步骤?"
- 变体三:"Dubbo 的 Cluster 层做了什么?"
- 变体四:"Dubbo 的 Filter 机制是怎么实现的?"
记忆口诀
Dubbo 调用链 10 步走(消费者 5 步 + 提供者 5 步):
- 消费者:
Proxy代理 →Filter链 →Cluster容错 →LoadBalance选人 →Protocol编码发送 - 提供者:
Netty接收 →Decode解码 →Filter链 →Invoker反射 → 结果返回
简记:"代、滤、群、衡、发" → "收、解、滤、调、回"
总结
一句话:Dubbo 的服务调用过程就是一条 "Proxy → Filter → Cluster → LoadBalance → Protocol → Transport" 的责任链,消费者端和提供者端各跑一半,中间通过网络传输连接。面试时把分层架构说清楚,再配上 Cluster 容错和 LoadBalance 负载均衡的细节,基本就稳了。