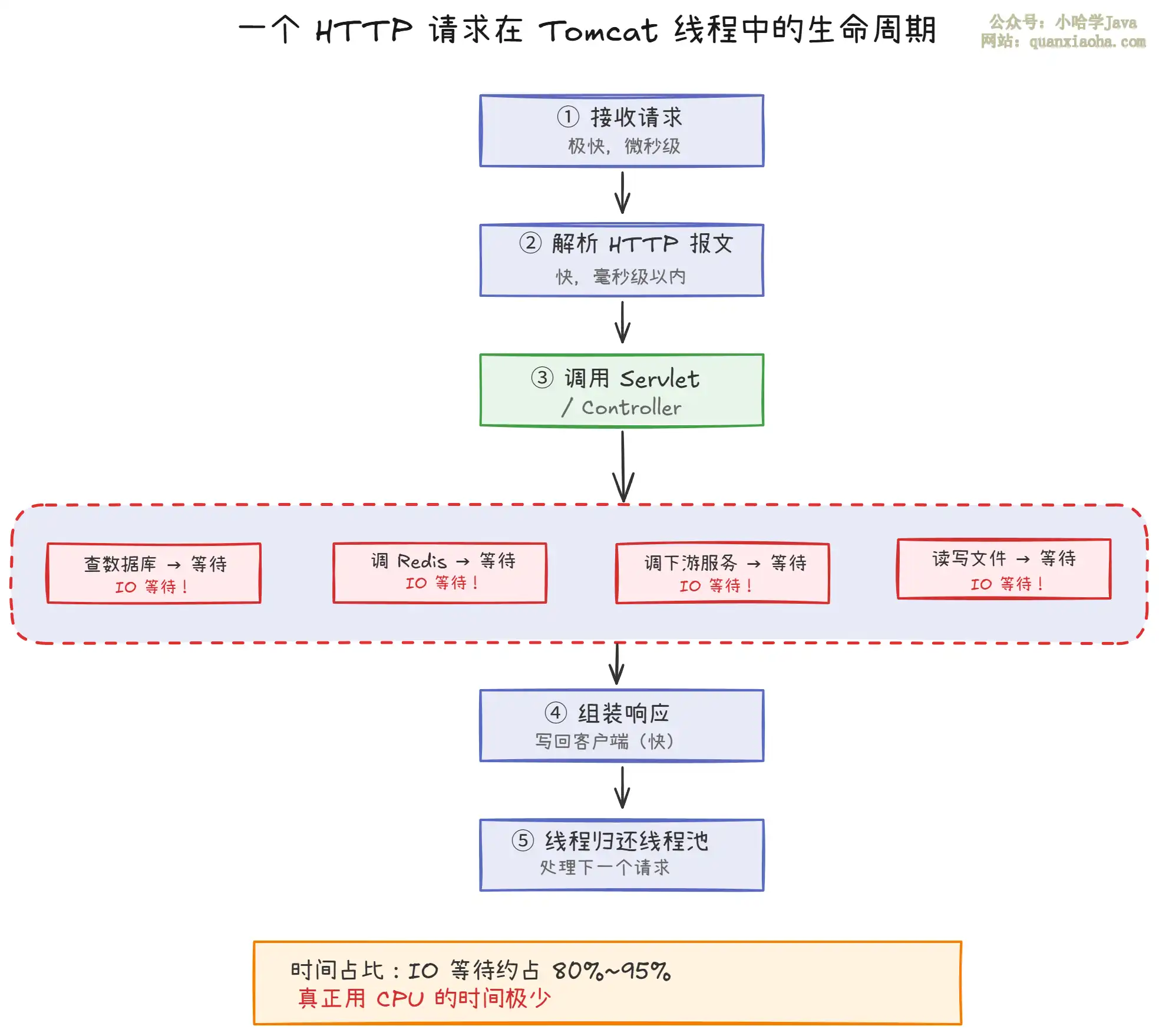
为什么 Tomcat 默认最大线程数是 200,而不是 N+1?
深度解析Tomcat默认最大线程数为什么是200而不是N+1。从I/O密集型原理、历史背景、内存与调度开销切入,阐明其作为保守安全值的缘由,并给出生产环境基于压测寻找性能拐点的科学调优方法与最佳实践。
2026/2/6Java面试八股文
深度解析Tomcat默认最大线程数为什么是200而不是N+1。从I/O密集型原理、历史背景、内存与调度开销切入,阐明其作为保守安全值的缘由,并给出生产环境基于压测寻找性能拐点的科学调优方法与最佳实践。
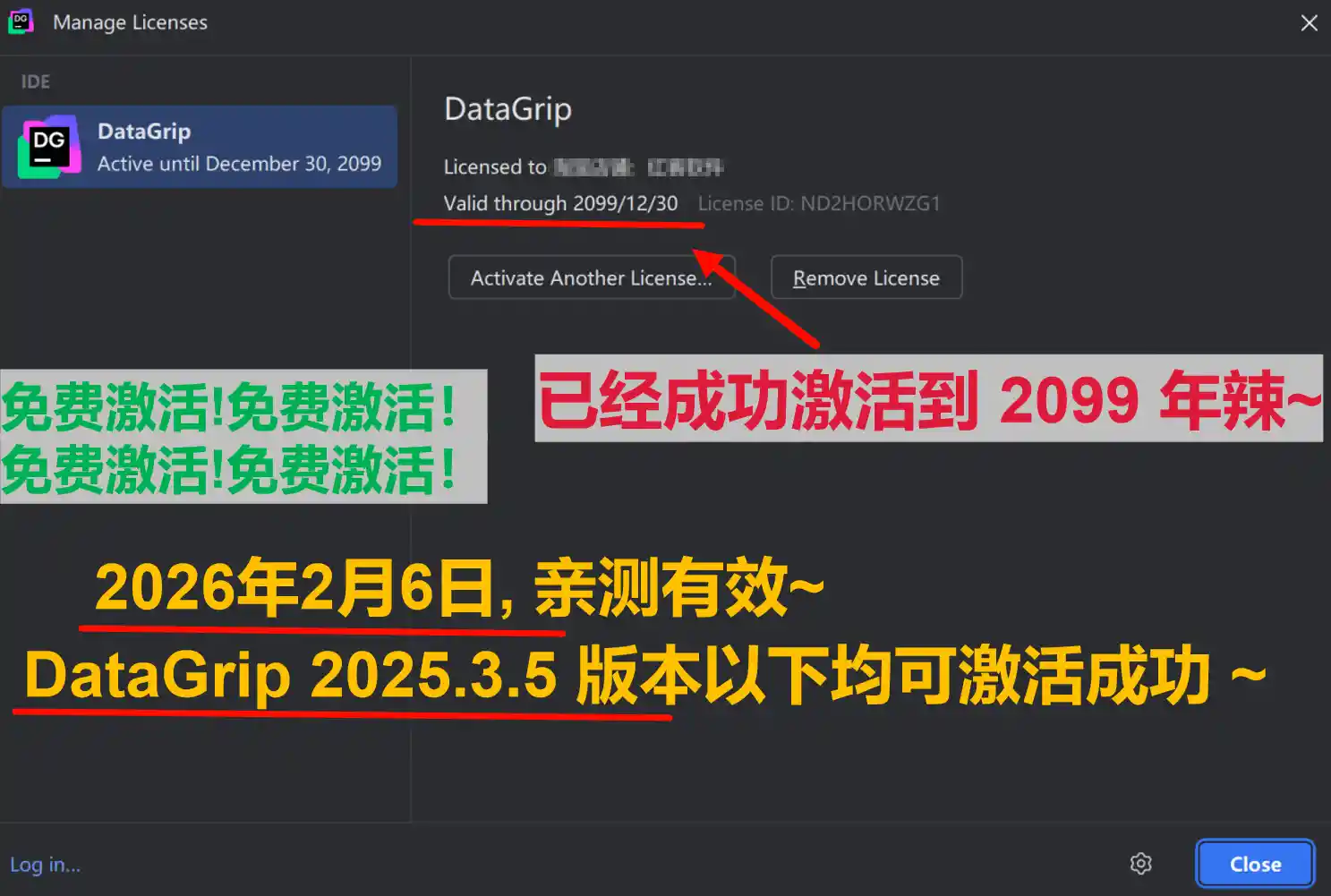
废话不多说,先上 DataGrip 2025.3.5 版本破解成功的截图,如下图,可以看到已经成功破解到 2099 年辣,舒服的很!
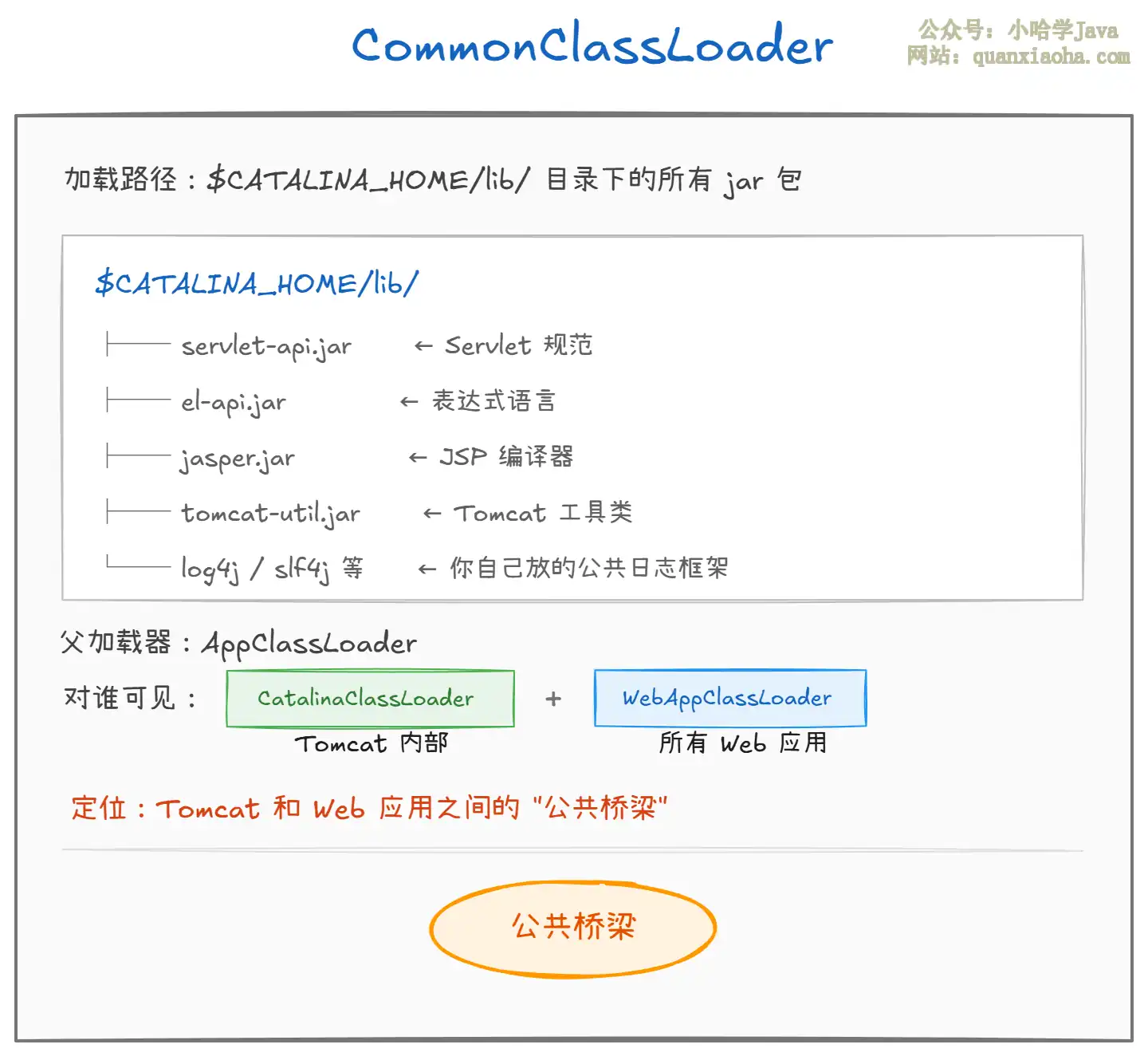
本文深度解析Tomcat类加载器体系:Common、Catalina、Shared及WebappClassLoader。详解其如何通过独特的“反向双亲委派”机制实现Web应用隔离,避免类冲突,并深入原理、代码示例与配置实践。帮你彻底理解Tomcat多应用托管的设计基石与类加载机制。
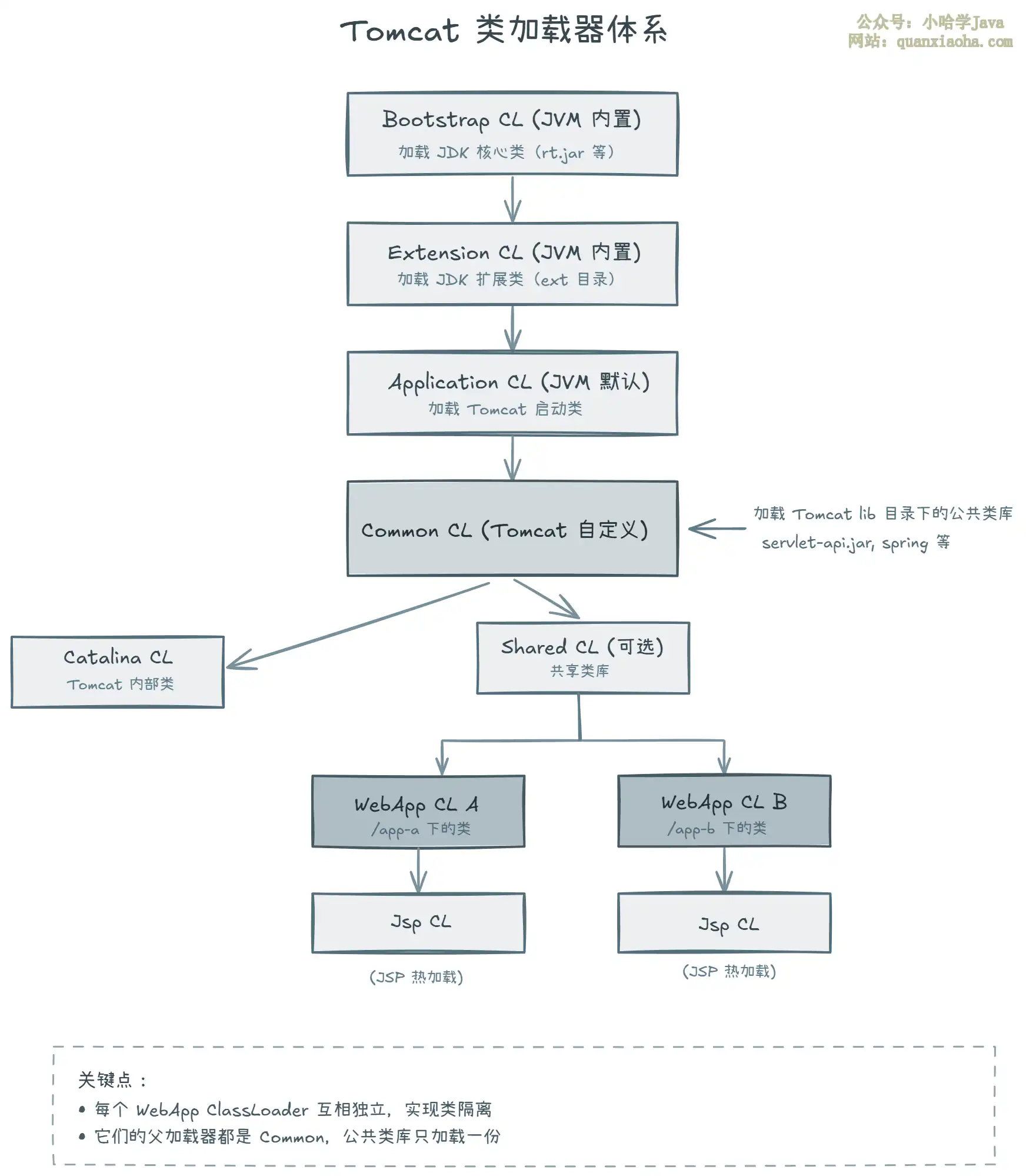
深度解析Tomcat独特的类加载机制。详解Bootstrap、Common、WebAppClassLoader等核心加载器的层次与职责,重点剖析WebAppClassLoader如何通过“打破双亲委派”实现应用隔离与热部署,并提供类库放置最佳实践与常见类冲突解决方案。
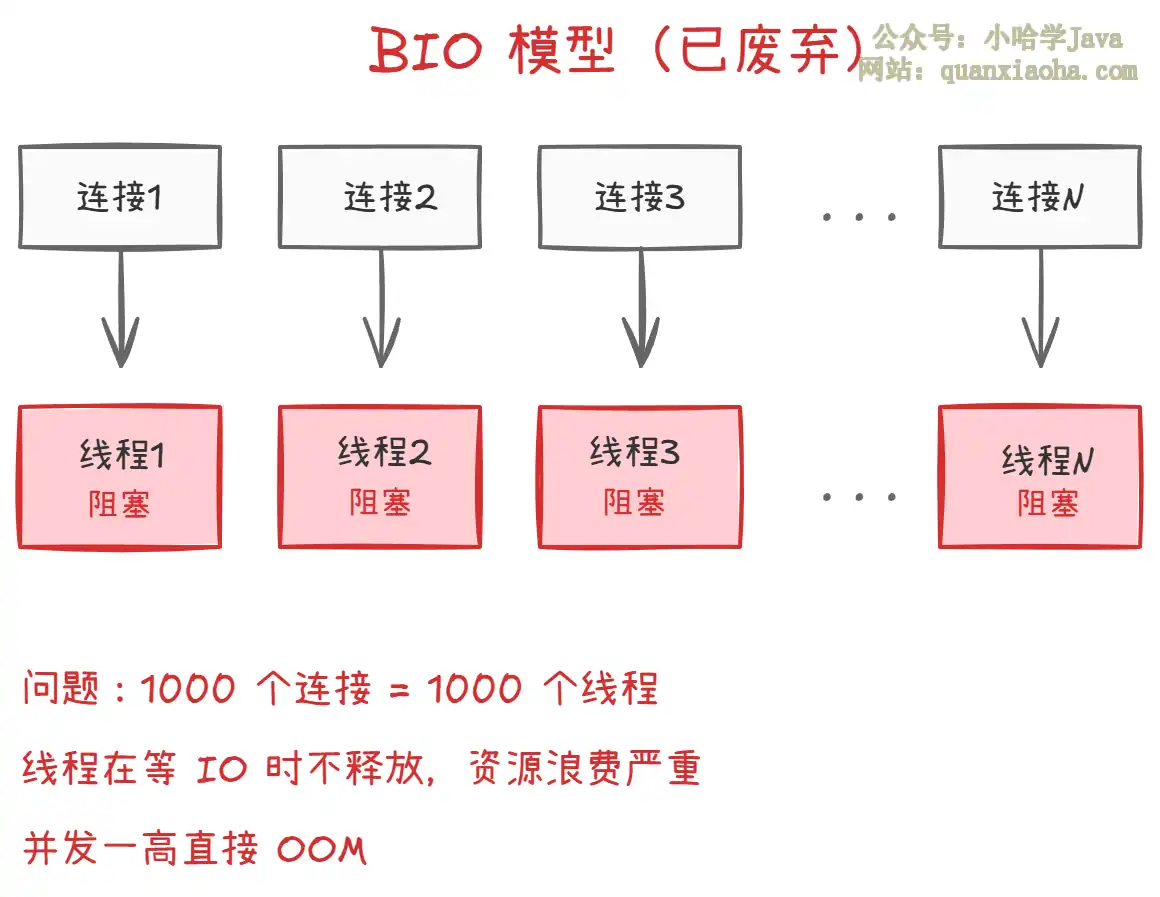
本文深入解析Tomcat支持的核心IO模型:BIO、NIO、NIO2与APR。详解其阻塞/非阻塞、多路复用原理,对比性能差异与适用场景,并提供Connector配置示例。帮助你理解Tomcat如何通过IO模型演进应对高并发,并做出正确的性能调优与技术选型。
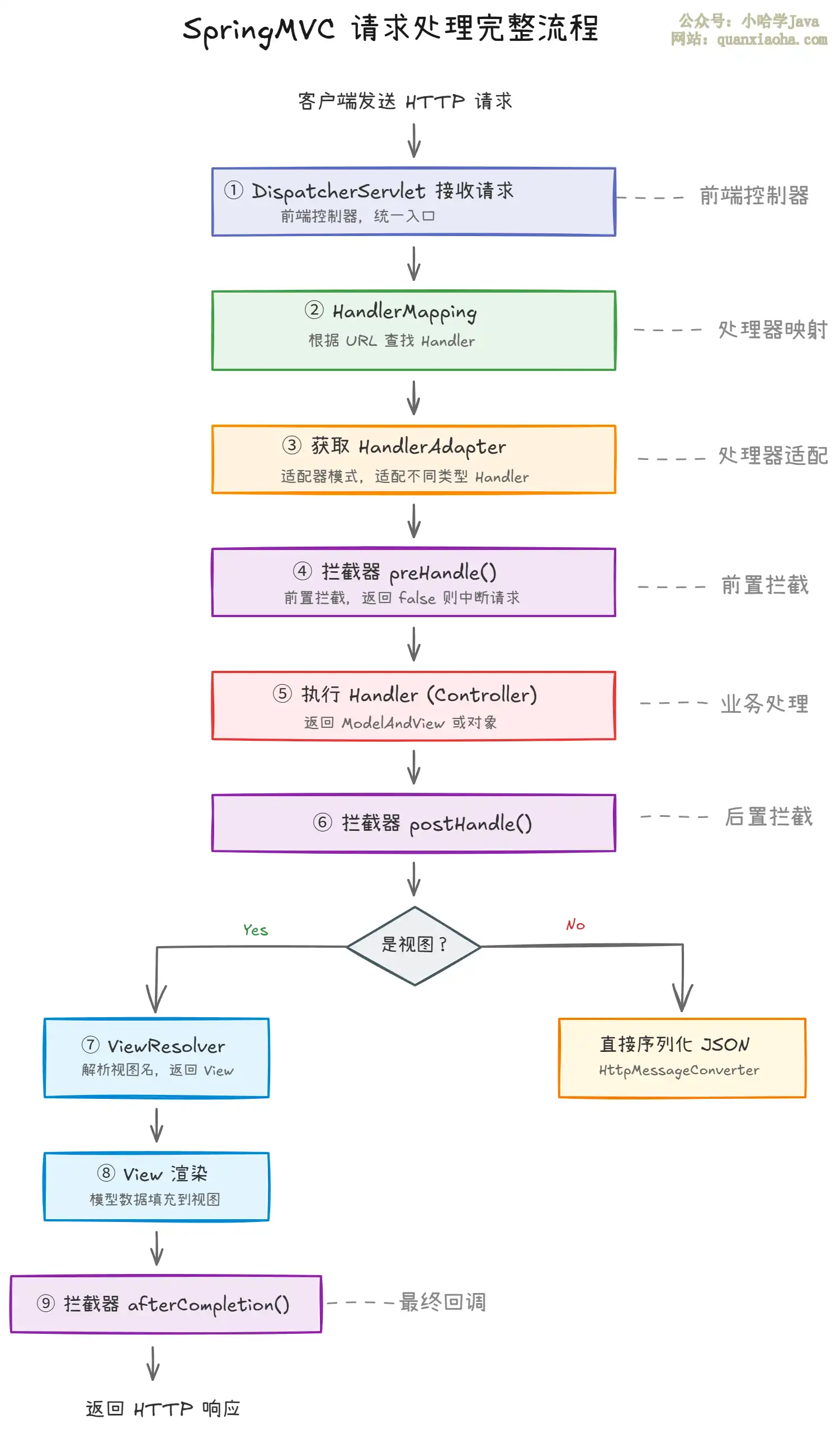
本文深度剖析SpringMVC处理HTTP请求的完整流程与核心原理。详解DispatcherServlet如何协同HandlerMapping、HandlerAdapter、ViewResolver等组件,逐步完成请求映射、方法调用、视图渲染。涵盖设计模式、代码级执行顺序、异步处理及对比最佳实践,并附核心流程图,助你彻底掌握SpringMVC工作机制与面试要点。
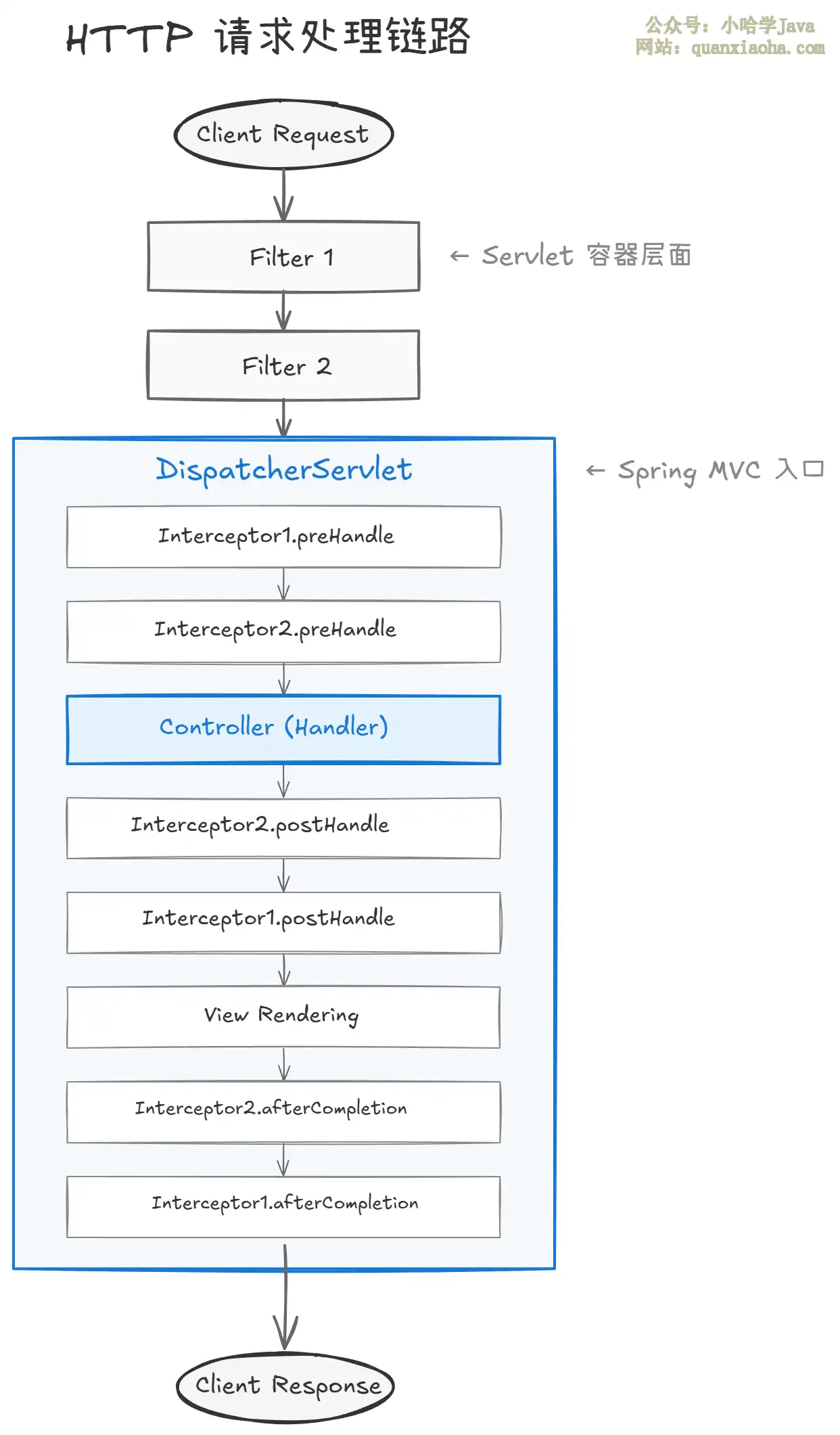
本文深度解析Java Web开发中过滤器(Filter)与拦截器(Interceptor)的核心区别。从Servlet规范与Spring框架的底层原理、执行时机、代码示例,到最佳实践选择指南(如全局编码用Filter,权限校验用Interceptor),并澄清常见误区。附详细对比表格与执行流程图,助你彻底掌握这一经典面试考点与架构设计要点。
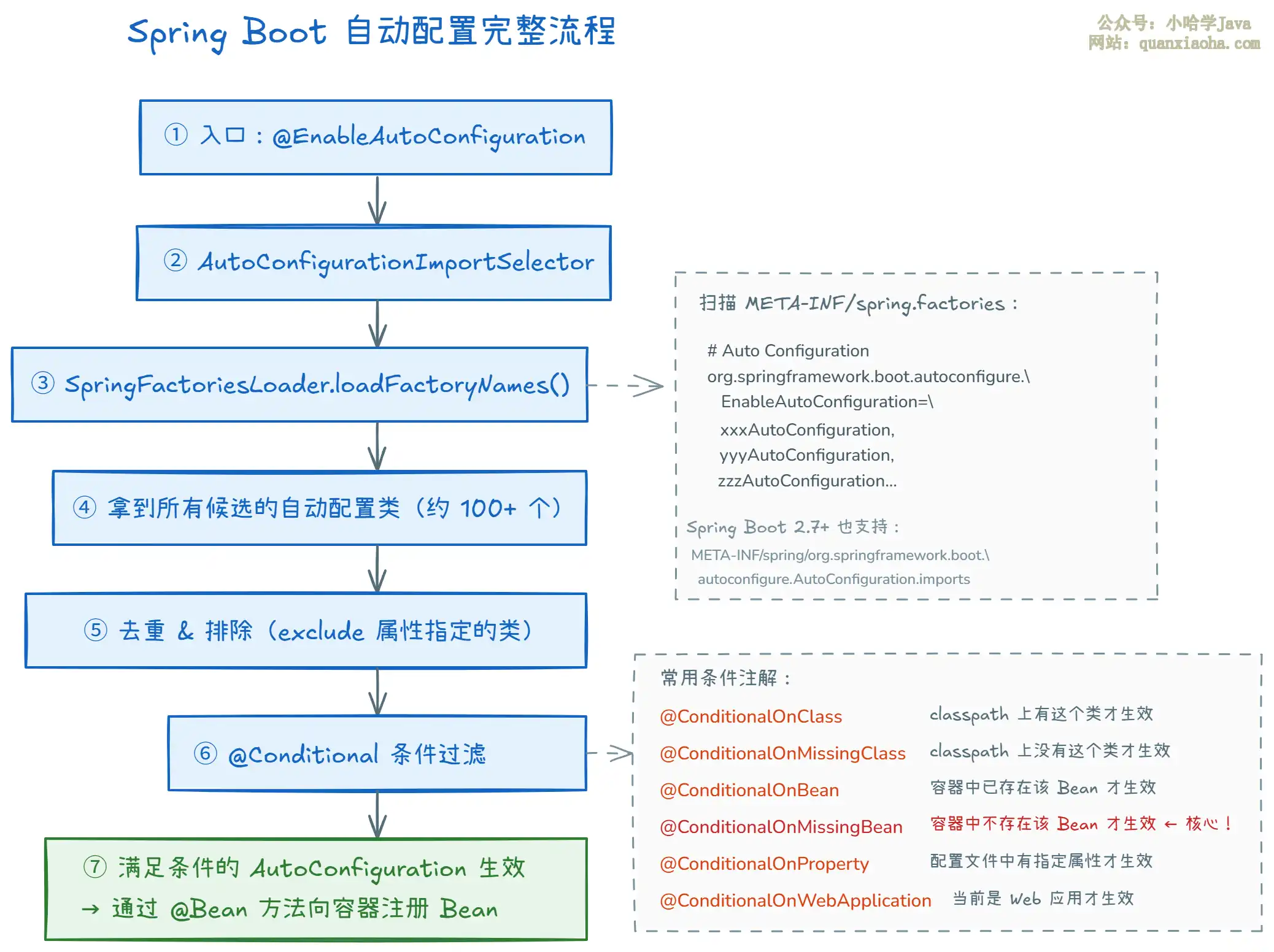
本文深入解析SpringBoot自动配置的实现原理,从@EnableAutoConfiguration触发、SpringFactoriesLoader加载、@Conditional条件过滤到最终Bean装配的全过程,并通过自定义自动配置示例详解,是理解SpringBoot“约定优于配置”核心思想的必备指南。
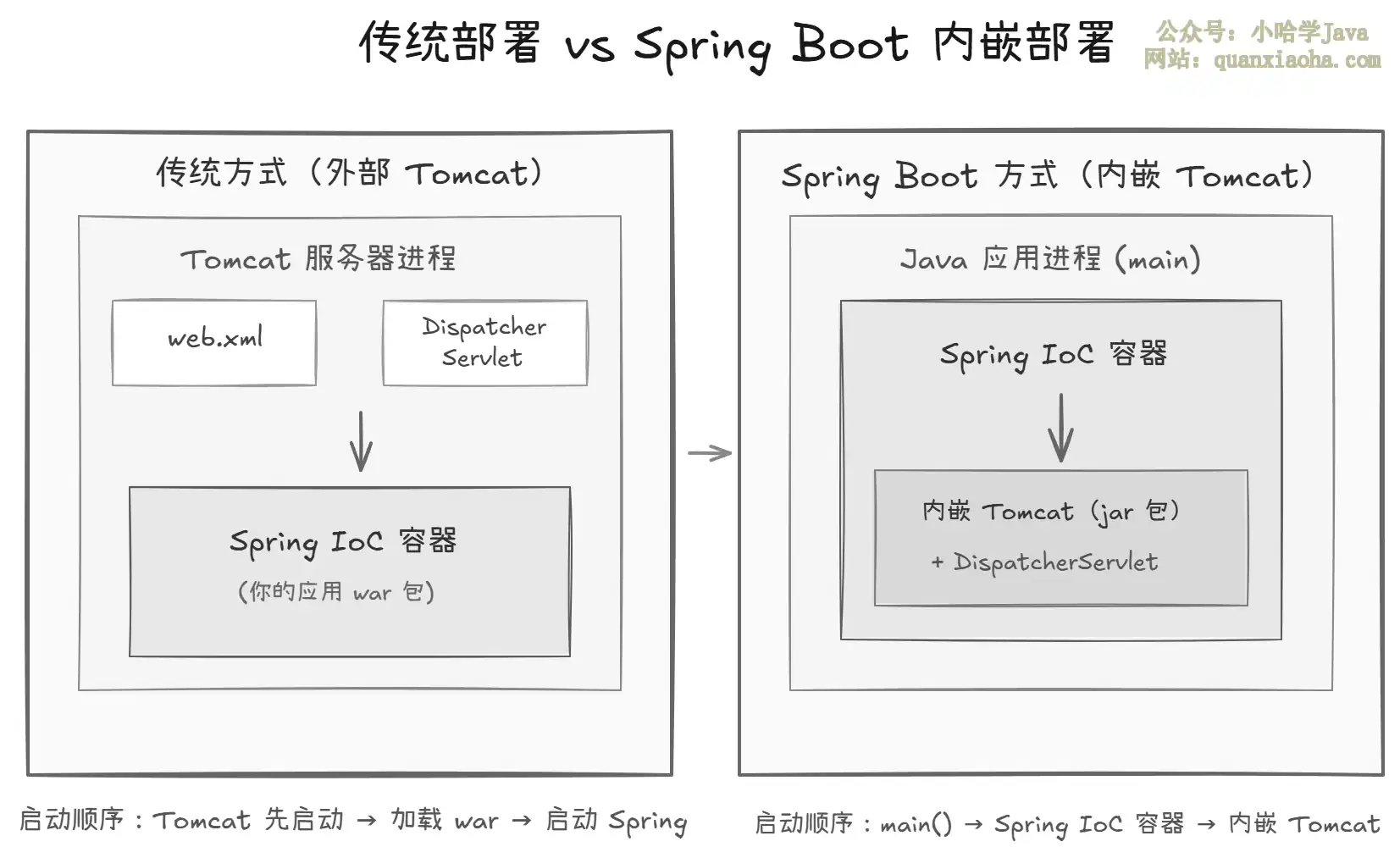
本文深入解析SpringBoot如何通过main方法一键启动Web应用的完整原理,详细阐述内嵌容器(Tomcat/Jetty)的自动装配机制、SpringApplication.run()的核心启动流程及ServletWebServerApplicationContext的关键作用,是理解SpringBoot简化部署设计思想的权威指南。
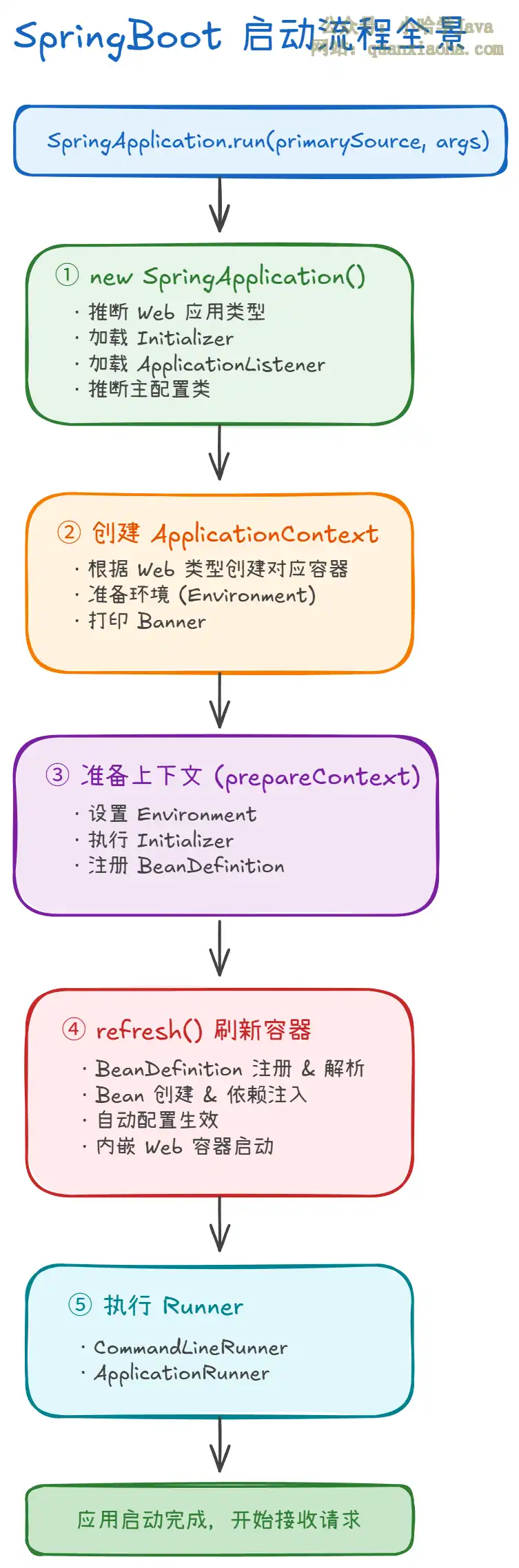
本文深入解析SpringBoot应用的完整启动流程,从SpringApplication初始化、环境准备、应用上下文创建与刷新,到自动配置加载、内嵌Web服务器启动及Runner执行,详解每个步骤的原理与机制,是理解SpringBoot核心原理和面试准备的权威指南。