什么是 TCP 的粘包、拆包问题?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
-
TCP 基础理解:面试官不仅仅想知道你听过 "粘包" 这个词,更想知道你是否理解 TCP 是面向字节流的协议,以及这个特性带来的影响。
-
问题解决能力:考察你是否知道如何在应用层设计协议来解决这个问题,比如消息定长、分隔符、Header-Body 模式等。
-
实践意识:如果你用过 Netty 或自研 RPC 框架,面试官想知道你是否在实战中处理过这个问题。
核心答案
TCP 是面向字节流的协议,不保证消息边界。发送方发送的多个数据包,在接收方可能被 "粘" 在一起读出来(粘包),也可能一个包被 "拆" 成多个部分读取(拆包)。
本质上,这不是 TCP 的 Bug,而是 TCP 的设计特性。 因为 TCP 只管可靠地传输字节流,它根本不知道你的 "消息边界" 在哪。
先来看一张图,直观理解粘包和拆包:
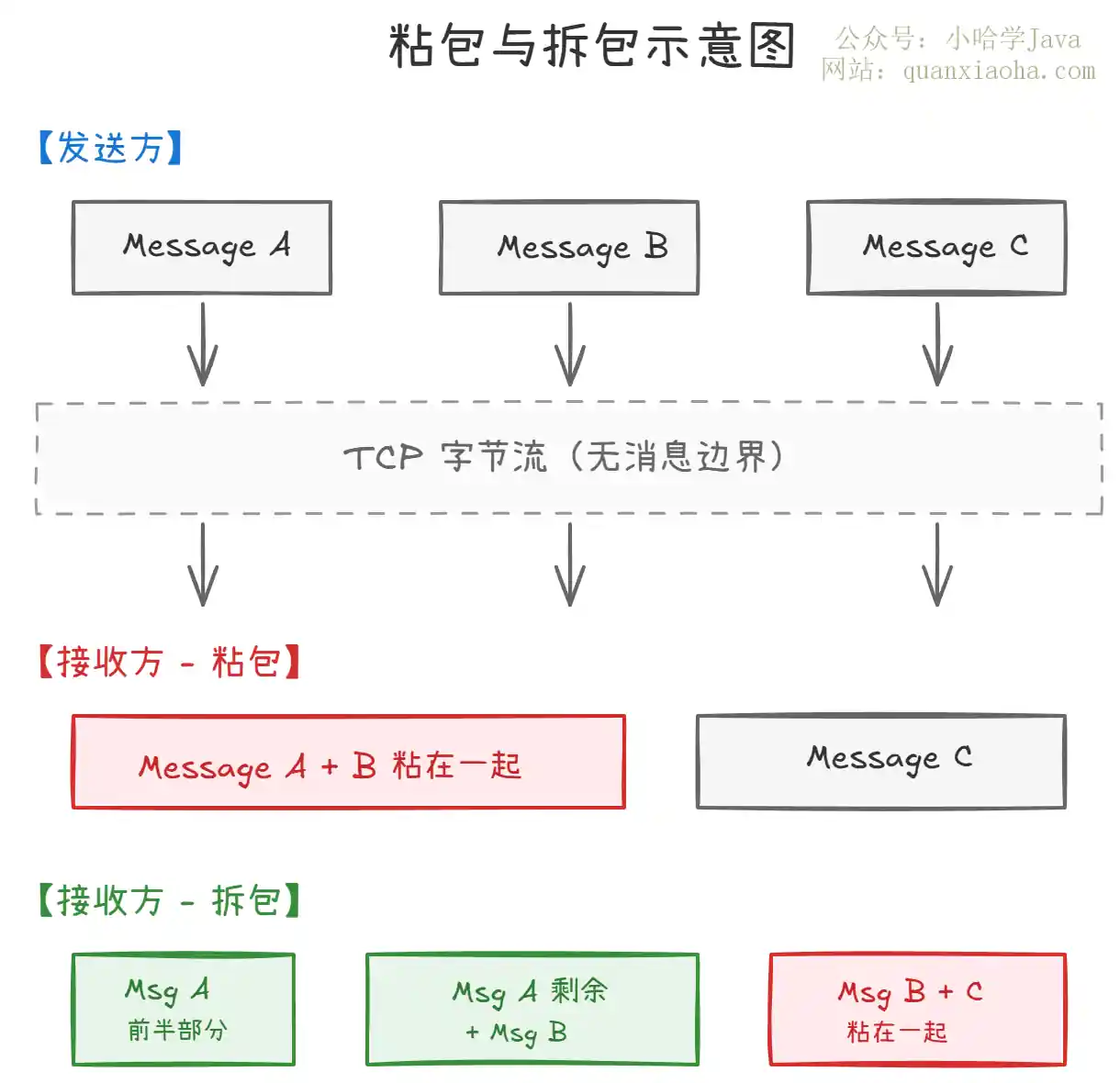
上图展示了粘包和拆包的两种情况:
- 粘包(上方):发送方发送了 Message A、B、C 三条独立消息,但接收方第一次
read()读到了 A+B 粘在一起的数据,第二次才读到 C。接收方无法区分 A 和 B 的边界。 - 拆包(下方):同样是三条消息,接收方第一次只读到了 Message A 的前半部分,第二次读到了 A 的后半部分和 B 粘在一起,第三次读到 C。一条完整的消息被拆成了多次读取。
深度解析
一、为什么会发生粘包、拆包?
根本原因就一句话:TCP 是面向字节流的,不是面向消息的。
TCP 发送数据时,会把应用层数据放入发送缓冲区,然后由操作系统内核决定什么时候发、发多少。同样,接收方也是从接收缓冲区里读数据。这两端都存在一个缓冲区,数据在其中的合并和拆分完全由 TCP 协议栈控制。
具体触发条件:
- Nagle 算法:TCP 默认开启了 Nagle 算法,它会把多个小数据包攒成一个大包一起发,以提高网络利用率。这直接导致粘包。
- 接收方读取不及时:发送方连续发了多个包,接收方没有及时
read(),数据在缓冲区堆积,一次读取就粘在一起了。 - MSS/MTU 限制:如果发送的数据超过最大报文段长度(MSS),TCP 会分片传输,导致拆包。
- 缓冲区大小:接收方的
recv()指定的 buffer 大小小于实际数据量,也会导致拆包。
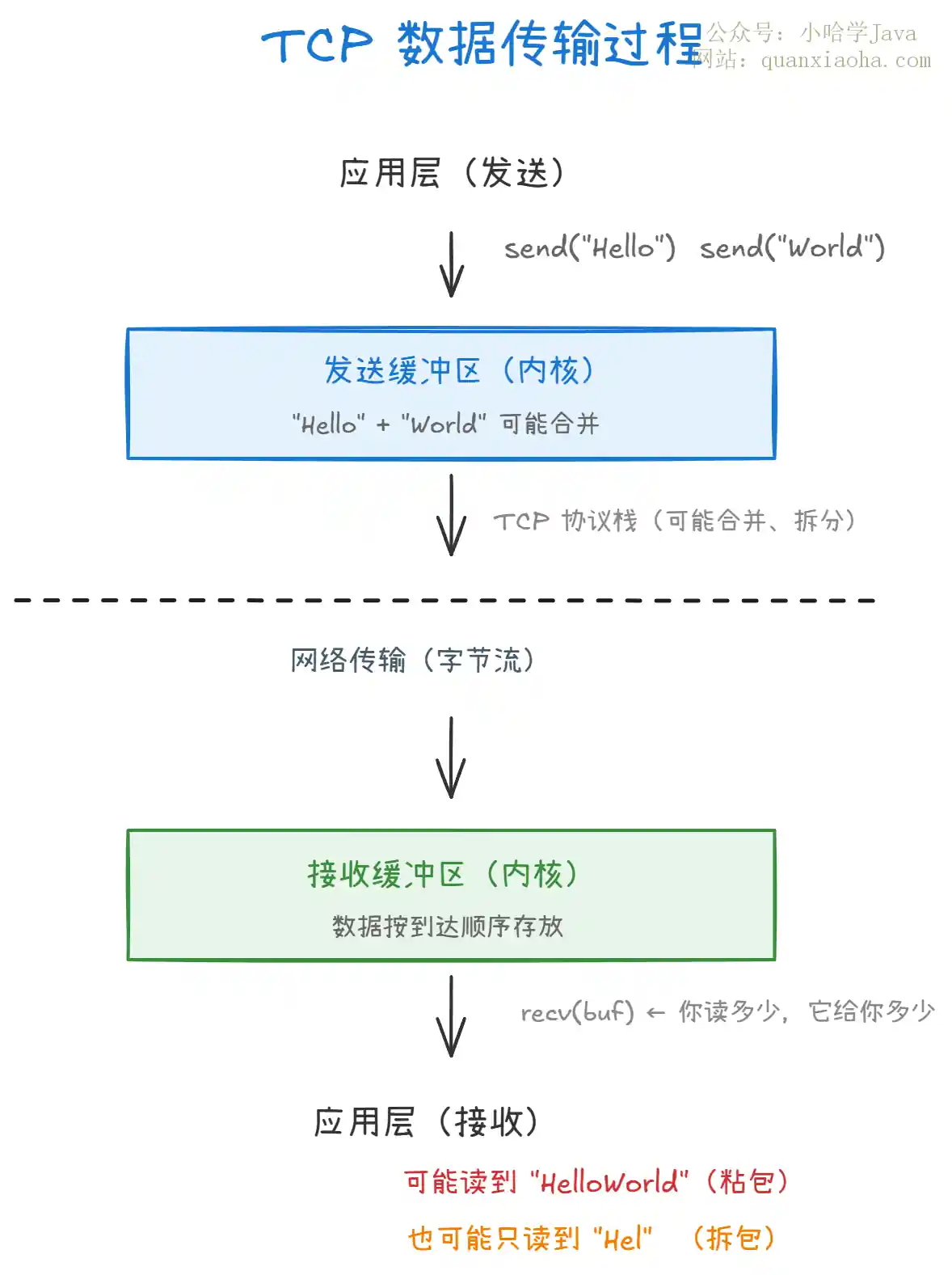
上图展示了 TCP 数据传输的完整过程。关键在于中间的缓冲区环节:
- 发送缓冲区:应用层调用
send()两次,数据先进入发送缓冲区。TCP 协议栈可能将这两份数据合并成一个 TCP 段发出,也可能因为 Nagle 算法攒了一批再发。 - 网络传输:TCP 只保证字节流的可靠、有序传输,不维护消息边界。
- 接收缓冲区:数据到达后按顺序存入接收缓冲区,应用层调
recv()时,缓冲区里有什么就给什么,给多少取决于你传的 buffer 大小和当前缓冲区的数据量。
一句话总结:从 TCP 的视角看,它只负责可靠地传输一堆字节,至于这些字节代表几条消息、每条消息有多长,TCP 根本不关心。
二、UDP 会有粘包问题吗?
不会。
UDP 是面向数据报的协议,每个 sendto() 对应一个完整的 UDP 数据报,接收方的 recvfrom() 也是一次读一个完整的数据报。数据报之间有天然的边界。
所以如果你面试时能主动提到 "UDP 没有这个问题,因为它是面向数据报的",面试官会眼前一亮。
三、怎么解决粘包、拆包?
核心思路:在应用层定义消息边界,让接收方知道一条完整的消息从哪开始、到哪结束。
常见的解决方案有 4 种:
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 消息定长 | 每条消息固定长度,不够补齐 | 实现简单 | 浪费带宽,灵活性差 |
| 特殊分隔符 | 用 \n、\r\n 等分隔 |
简单直观 | 消息体不能包含分隔符 |
| Header-Body(长度字段) | 先发长度,再发内容 | 最通用、最灵活 | 实现稍复杂 |
| 自定义协议 | 结合多种方式,如魔数+版本+长度+内容 | 最完整 | 复杂度最高 |
下面重点讲最主流的 Header-Body(长度字段) 方案,这也是 Netty 和大多数 RPC 框架的做法。
四、Header-Body 方案详解

上图是一个典型的消息封装格式:
- 魔数(Magic Number):用于标识协议,快速判断数据是否合法。比如 Java 序列化用
0xaced,自定义协议可以用任意值。 - 长度字段:记录消息体的字节长度。接收方先读固定长度的 Header,从中取出长度字段,再精确读取对应长度的 Body。
- 消息体(Body):实际的业务数据,可以是 JSON、Protobuf 等任意格式。
接收方的解码逻辑:
// 伪代码:接收方解码流程
while (true) {
// 1. 先尝试读取 Header(假设固定 8 字节:4 字节魔数 + 4 字节长度)
if (readableBytes() < 8) {
return; // 数据不够一个 Header,等下次
}
// 2. 标记当前读位置,以便回退
markReaderIndex();
// 3. 读取魔数,校验合法性
int magic = readInt();
if (magic != 0xCAFE) {
throw new Exception("非法数据包");
}
// 4. 读取消息体长度
int length = readInt();
// 5. 判断消息体是否已经完整到达
if (readableBytes() < length) {
resetReaderIndex(); // 数据不完整,回退读指针
return; // 等下次数据到达再读
}
// 6. 读取完整的消息体
byte[] body = readBytes(length);
handleMsg(body);
}
五、Netty 中的解决方案
Netty 提供了开箱即用的解码器,不用手写上面那些复杂的逻辑:
| 解码器 | 类名 | 适用场景 |
|---|---|---|
| 固定长度 | FixedLengthFrameDecoder |
消息定长 |
| 分隔符 | DelimiterBasedFrameDecoder |
特殊字符分隔 |
| 长度字段 | LengthFieldBasedFrameDecoder |
Header-Body 模式 |
| 行分隔 | LineBasedFrameDecoder |
\n 或 \r\n 分隔 |
最常用的是 LengthFieldBasedFrameDecoder,一个典型配置:
// 参数说明:
// maxFrameLength = 1024 → 最大帧长度 1024 字节
// lengthFieldOffset = 0 → 长度字段从第 0 字节开始
// lengthFieldLength = 4 → 长度字段占 4 字节
// lengthAdjustment = 0 → 长度值就是 body 的长度,不需要调整
// initialBytesToStrip = 0 → 解码后不剥离 header
ch.pipeline().addLast(
new LengthFieldBasedFrameDecoder(1024, 0, 4, 0, 0)
);
说实话,LengthFieldBasedFrameDecoder 那几个参数第一次看确实有点绕,尤其是 lengthAdjustment。但原理搞明白之后就是套公式的事,面试官看到你连这个都能讲清楚,基本就觉得你确实在生产环境用过 Netty。
面试高频追问
-
追问一:TCP 为什么是面向字节流而不是面向消息的?
因为 TCP 的设计目标是提供可靠、有序的字节流传输服务。应用层可能发送任意大小的数据,TCP 需要将数据切分成合适大小的段来传输,接收端再重新组装。这种设计让上层协议可以自由定义消息格式(HTTP、FTP、自定义 RPC 协议等),灵活性最大。
-
追问二:如果接收方读取速度很慢,发送方疯狂发数据,会发生什么?
接收缓冲区会不断堆积数据,导致粘包更严重。如果缓冲区满了,TCP 会通过流量控制(滑动窗口)通知发送方降低发送速率。极端情况下还可能触发 OOM。
-
追问三:HTTP 是怎么解决粘包问题的?
HTTP/1.1 通过
Content-Length头标识消息体长度(就是 Header-Body 方案),或者用Transfer-Encoding: chunked分块传输。HTTP/2 则使用了基于帧的二进制协议,每帧都有明确的长度字段。本质上都是在应用层定义消息边界。
常见面试变体
- "Netty 是如何解决粘包拆包的?"
- "为什么 TCP 会粘包而 UDP 不会?"
- "如何设计一个自定义通信协议来解决粘包问题?"
- "
LengthFieldBasedFrameDecoder的参数分别是什么含义?"
记忆口诀
粘拆根因:字节流,无边界(TCP 只管传字节,不管消息边)
解决思路:应用层,定边界(定长、分隔符、长度字段、自定义协议)
主流方案:先发长度再发体(Header-Body,Netty 的 LengthFieldBasedFrameDecoder 就是这个套路)
总结
TCP 粘包、拆包不是 Bug,而是 TCP 面向字节流设计的必然结果。解决思路就是在应用层自己定义消息边界——业界最主流的做法是 Header-Body 模式(长度字段),Netty 提供了 LengthFieldBasedFrameDecoder 开箱即用。面试时把 "为什么发生" 和 "怎么解决" 两条线讲清楚,基本就稳了。