Agent 记忆压缩通常有哪些方法?
一则或许对你有用的小广告
欢迎加入小哈的星球,你将获得:专属的实战项目(4个项目都能学) / 1v1 提问 / 简历修改 / Java 学习路线 / 社群讨论 / 学习打卡 / 每月赠书
《Spring AI 项目实战(问答机器人、RAG 智能客服、联网搜索)》已完结,基于
Spring AI + Spring Boot 3.x + JDK 21...,查看介绍《从零手撸:仿小红书(微服务架构)》 已完结,基于
Spring Cloud Alibaba + Spring Boot 3.x + JDK 17...,查看介绍;演示链接:http://116.62.199.48:7070/《从零手撸:前后端分离博客项目(全栈开发)》 2 期已完结,演示链接:http://116.62.199.48/
新开坑项目:《从零手撸:秒杀系统高并发优化实战》 正在更新中...,查看介绍
截止目前,星球内专栏累计输出 150w+ 字,讲解图 5110+ 张,还在持续爆肝中.. 后续还会上新更多项目,已有 4700+ 小伙伴加入学习,欢迎点击围观
面试考察点
- 本质理解:面试官想确认你是不是真理解 "记忆压缩"。它不是单纯缩文本那么简单,得在 Token 成本、信息保真度、任务延续性之间找平衡。另外得知道,业界已经把它归到 "Context Engineering(上下文工程)" 这个更大的框架里去了。
- 方法体系:你能不能把主流的压缩方法分类讲清楚?摘要、剪枝、外部化、隔离……每类方法的适用场景和代价你了解吗?还是只会说一句 "用 LLM 总结一下"?
- 工程落地:生产环境里你实际用过哪种方案?踩过哪些坑?比如结构化摘要为啥比自由摘要靠谱?压缩后 Agent 忘了改过哪些文件怎么办?
核心答案
Agent 记忆压缩说白了就一件事:在有限的上下文窗口里,尽量留住对完成当前任务最关键的信息。
业界主流方法可以归为 5 大类:
| 方法类别 | 核心思路 | 典型代表 | 代价 |
|---|---|---|---|
| 摘要压缩 Summarization | 用 LLM 把历史对话蒸馏成摘要 | 滚动摘要、结构化摘要、锚定迭代摘要 | 摘要本身丢细节,有信息漂移 |
| 剪枝过滤 Trimming/Pruning | 直接删掉不重要的消息或 Token | 滑动窗口、智能剪枝(Provence) | 硬删除可能丢失关键线索 |
| 外部化 Externalization | 把记忆搬出上下文,存到向量库/文件 | Scratchpad、向量记忆、知识图谱 | 需要额外检索,引入召回误差 |
| 上下文隔离 Isolation | 把上下文拆给多个子 Agent / 沙箱 | 多 Agent 协作、Code Agent 沙箱 | 协调成本高,Token 总量可能反增 |
| 表示压缩 Representation | 训练层面的 KV-Cache / 表示压缩 | NVIDIA DMC、OpenAI /responses/compact |
黑盒不可读,需训练或闭源 API |
还有个反常识的点:压缩比高低不代表好坏,真正该看的是完成整个任务一共烧了多少 Token。这是 Factory.ai 在 2025 年 12 月那份压缩评估报告里的核心结论。OpenAI 的 compact 压缩率能干到 99.3%,质量得分却是最低的,原因就是压掉的关键细节,后面又得花 Token 重新检索回来。
深度解析
一、为什么必须做记忆压缩?
长会话 Agent 的上下文会越攒越多,连带出一堆问题。Drew Breunig 整理过四种典型的上下文退化模式,现在基本成了行业共识:
- Context Poisoning(上下文污染):幻觉内容混进上下文,被后续轮次反复引用
- Context Distraction(上下文分心):上下文太长,模型注意力被稀释,找不到关键信息
- Context Confusion(上下文混淆):无关内容干扰响应
- Context Clash(上下文冲突):上下文不同部分相互矛盾
所以说压缩这事,省 Token、省钱还在其次,真正要紧的是别让 Agent 变蠢。

上面这张图就是长会话 Agent 的典型循环。每轮工具调用都会往上下文里塞东西,搜索类工具尤其夸张,一次返回几千 Token 很正常。上下文一旦逼近窗口上限,就触发压缩,把历史蒸馏成精简版本,再继续推理。Claude Code 的 auto-compact 就是这个路子,上下文用到 95% 时自动触发。
二、五大方法详解
1. 摘要压缩(Summarization)—— 工程上用得最多
这是目前生产环境用得最多的方案,说白了就是用 LLM 把一长串历史对话浓缩成一段摘要。不过同样是摘要,做法不同,效果能差出十万八千里。
a. 滚动摘要(Rolling Summary)
最朴素的版本:把旧消息用 LLM 总结成一段话,新消息正常保留。每次压缩时,把新被截断的部分再总结一次,跟旧摘要合并。
问题也很明显,自由格式的摘要会越压越偏,重要细节(比如某个文件路径、错误码)可能在某次合并时被当成 "低信息量内容" 给扔了。
b. 结构化摘要(Structured Summarization)
Anthropic Claude SDK 和 Factory.ai 都在用同一个思路:让摘要必须按固定章节来写,比如:
- Session Intent(会话意图)
- Files Modified(改过哪些文件)
- Decisions Made(做过哪些决策)
- Current State(当前进展)
- Next Steps(下一步)
这里头有个挺巧的点,结构本身就是一种保护机制。每个章节相当于一个 checklist,摘要模型要么填内容,要么显式留空,没法偷偷跳过。文件路径、关键决策这些,就不容易被默默丢了。
c. 锚定迭代摘要(Anchored Iterative Summarization)
Factory.ai 在 2025 年提出的这套方法,目前工业界质量得分名列前茅。它跟前面方案的区别,主要在更新机制上:
- Anthropic 的做法:每次压缩都全量重新生成摘要
- Factory 的做法:只总结新被截断的那段,然后增量合并到持久化的旧摘要里(锚定)
全量重生成的麻烦在于,压的次数多了,早期信息会一点点 "蒸发" 掉。锚定方式相当于给摘要下了个稳定的 "锚",新信息往上叠加,老信息不容易丢。
下面这张时序图对比了两种更新策略:
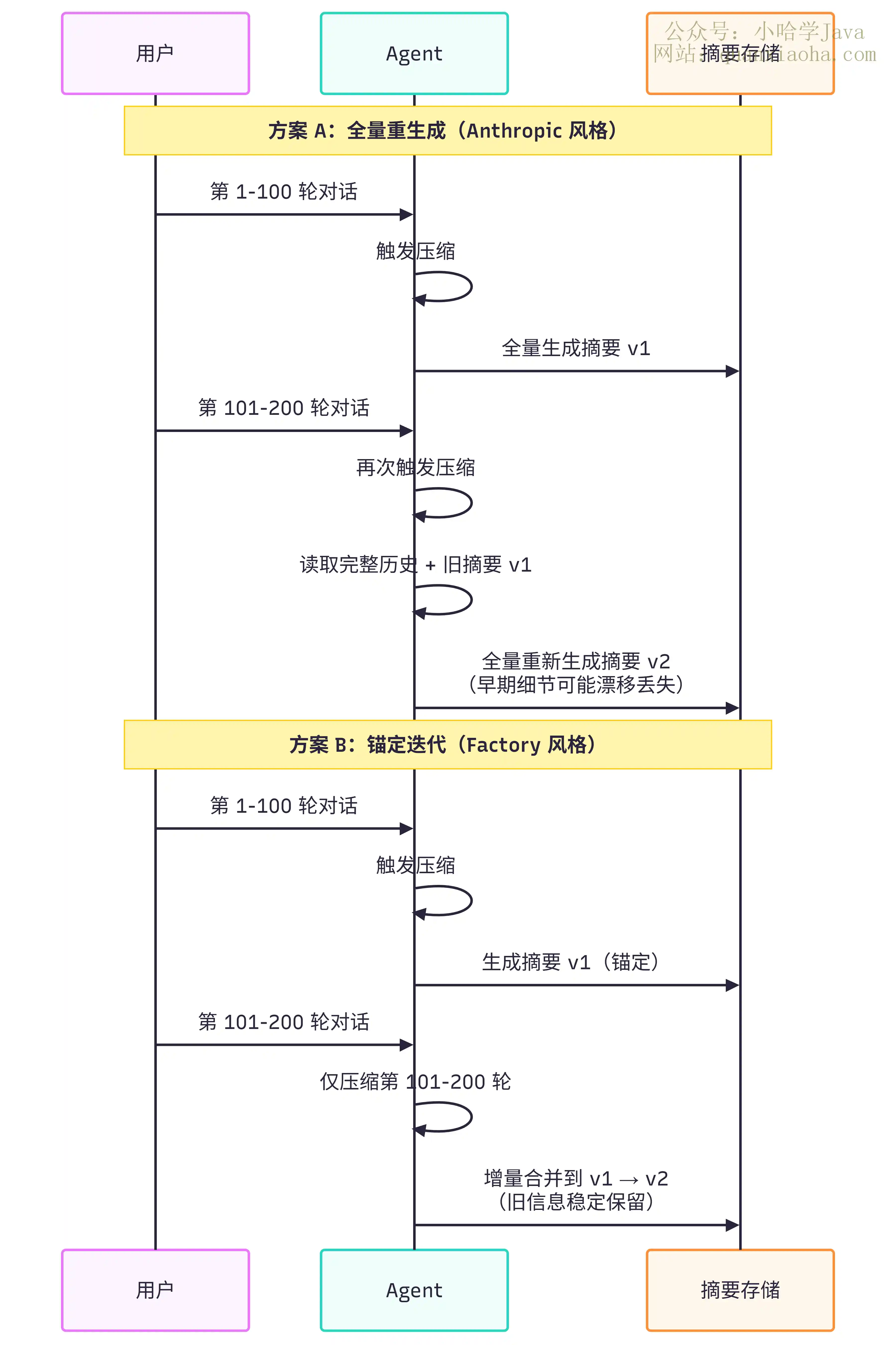
方案 B 的核心就一句话:别每次都从头重写历史,只处理新增的那段,老摘要当 "锚" 保持稳定。Factory 在 3.6 万条真实会话上跑过评估,这种方式比 OpenAI 和 Anthropic 的方案分别高出 0.35 和 0.26 个质量分(满分 5 分)。
2. 剪枝过滤(Trimming / Pruning)—— 简单粗暴但快
摘要要调 LLM,慢且贵。剪枝则是直接按规则删除,不调用模型。
a. 滑动窗口(Sliding Window)
最简单的策略:只保留最近 N 条消息,或者最近 N 个 Token。老消息直接丢。LangChain4j 的 MessageWindowChatMemory 和 TokenWindowChatMemory 就是这种实现。
优点是快、好控制。缺点也明显,假设第 3 轮提到的一个关键文件路径,到第 50 轮还在用,滑动窗口直接就把它删了,Agent 当场就懵。
b. 智能剪枝(Smart Pruning)
比硬规则聪明一点:用一个小模型或训练过的剪枝器判断哪些消息可以删。比如 Provence 这个专门为 QA 场景训练的剪枝器,能识别冗余信息。
实际工程中,剪枝通常跟摘要配合使用:重要的消息保留原文,不重要的直接剪掉,中间地带用摘要带过。
3. 外部化(Externalization)—— 把记忆搬出窗口
思路很简单,别把所有东西都往上下文窗口里塞,长期记忆搬到外部存储(向量库、文件、数据库),要用的时候再检索回来。
也就是 LangChain 说的 "Write + Select" 策略,先写出去,要用的时候再选回来。
- Scratchpad(草稿本):Agent 执行任务过程中,把计划、中间结论写到外部文件或状态字段里。Anthropic 的多 Agent 研究员就是这么干的——LeadResearcher 把计划写到 Memory 里,因为上下文超过 200K 就会被截断
- 向量记忆:把历史对话总结后向量化,存到向量库。下次需要时用 RAG 的方式检索回来。Mem0、LangMem 都是这条路子
- 知识图谱:把结构化的实体关系存到图数据库,适合需要复杂关联推理的场景
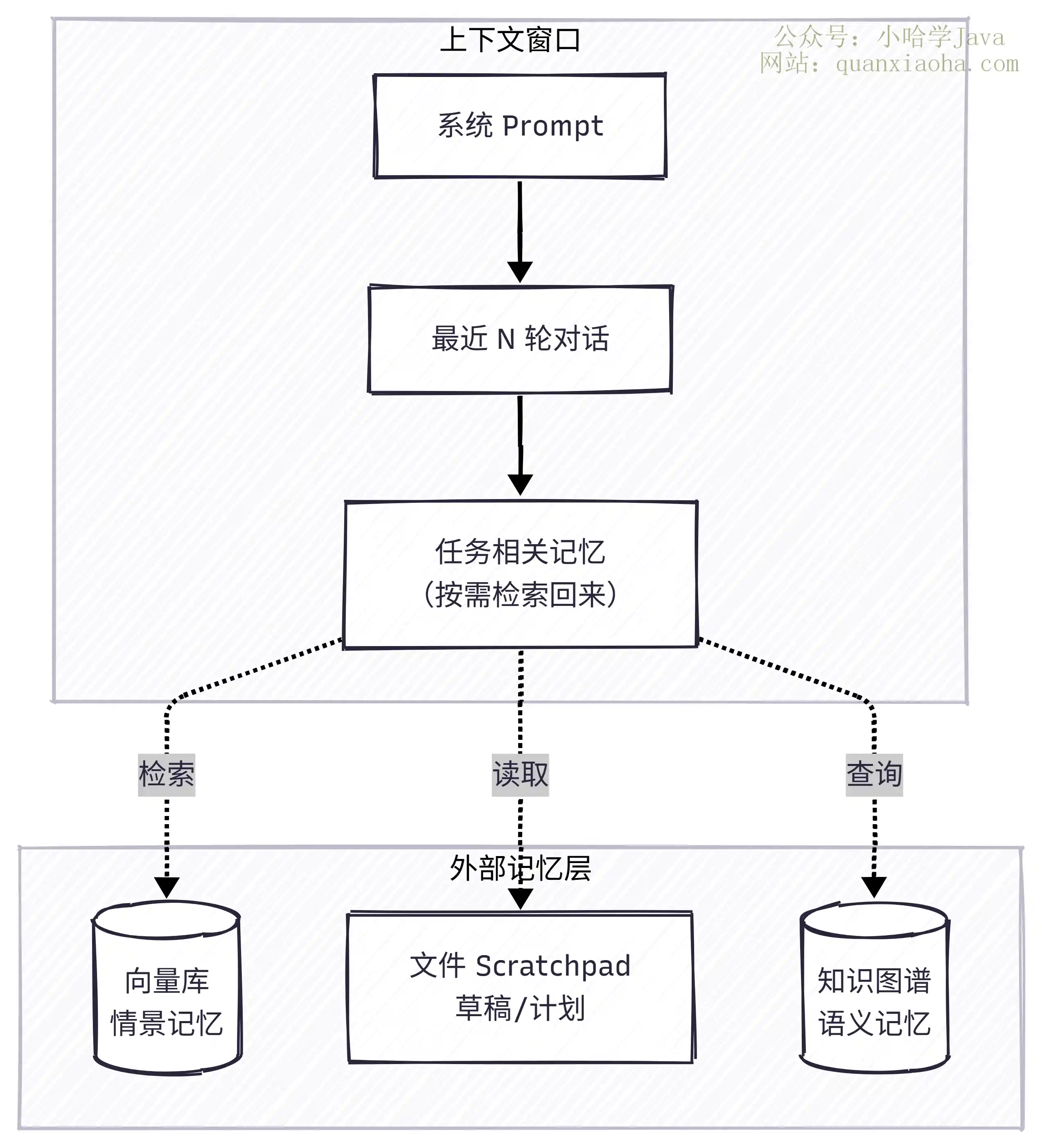
外部化的好处是记忆容量几乎没上限,跨会话也能接着用。坏处是多了检索这一环,召回不准就等于没记住,而且每检索一次都得额外走一轮 LLM 交互。
4. 上下文隔离(Isolation)—— 拆开各管各的
如果一个 Agent 的上下文实在太满,那就拆成多个 Agent,每个管一个子任务,各自揣着独立上下文。
- 多 Agent 协作:Anthropic 的多 Agent 研究员证明,多个子 Agent 并行(各自独立上下文)效果比单 Agent 好,因为每个上下文能专注于更窄的子任务。代价是 Token 总用量可能暴涨(最多到对话的 15 倍)
- 沙箱隔离:HuggingFace 的 CodeAgent 把工具调用放在沙箱里执行,工具返回的大对象(图片、音频、大数据)存沙箱变量里,只把必要的结果传回 LLM 上下文
- 状态对象隔离:在 Agent 的 runtime state 里设计多个字段,只把
messages字段暴露给 LLM,其他字段(文件句柄、中间数据)按需读取
5. 表示压缩(Representation)—— 训练层面的硬核方案
前面四种都是应用层的招数,这一类是模型层的方案,普通工程师不太会自己搞,但面试提一句能加分。
- NVIDIA DMC(Dynamic Memory Compression):训练阶段就教模型学会动态压缩 KV-Cache,推理时直接省内存、提吞吐,不损失精度
- OpenAI
/responses/compact:把对话压成不透明的紧凑表示,压缩率高达 99.3%,但人读不了,也没法验证保留了啥 - LLMLingua / LongLLMLingua:基于困惑度(PPL)的 Prompt 级压缩,删除低信息量的 Token
三、Java 代码示例:用 LangChain4j 实现滑动窗口 + 摘要
光说不练假把式,下面演示在 Java 里怎么落地。LangChain4j 提供了 ChatMemory 接口,内置滑动窗口实现;再叠加一个摘要 Advisor,就是最基础的 "剪枝 + 摘要" 组合。
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.memory.ChatMemory;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import dev.langchain4j.memory.chat.TokenWindowChatMemory;
import dev.langchain4j.model.chat.ChatModel;
import dev.langchain4j.model.openai.OpenAiChatModel;
import dev.langchain4j.model.chat.request.Response;
import java.util.List;
public class AgentMemoryCompressionDemo {
public static void main(String[] args) {
ChatModel llm = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName("gpt-4o")
.build();
// 方案 1:基于消息条数的滑动窗口(简单粗暴)
ChatMemory messageWindow = MessageWindowChatMemory.builder()
.maxMessages(20) // 只保留最近 20 条消息
.build();
// 方案 2:基于 Token 的滑动窗口(更精准)
ChatMemory tokenWindow = TokenWindowChatMemory.builder()
.maxTokens(8000, new OpenAiTokenCountEstimator("gpt-4o"))
.build();
// 模拟一段长对话
for (int i = 0; i < 30; i++) {
tokenWindow.add(dev.langchain4j.data.message.UserMessage.from(
"第 " + i + " 轮:帮我查一下订单 " + (1000 + i) + " 的状态"));
// ... 调用 LLM、工具等
}
// 关键:当窗口快满时,触发摘要压缩
List<ChatMessage> current = tokenWindow.messages();
if (estimateTokens(current) > 6000) {
// 1) 取出将被截断的旧消息
int summaryBoundary = current.size() / 2;
List<ChatMessage> toSummarize = current.subList(0, summaryBoundary);
// 2) 用 LLM 把它们总结成结构化摘要
String summaryPrompt = """
请把以下对话历史压缩成结构化摘要,必须包含以下章节:
1. 会话意图
2. 已涉及的文件 / 订单 / 关键实体
3. 已做出的决策
4. 当前进展
5. 下一步计划
没有的章节显式标注 "无",不要省略。
对话历史:
%s
""".formatted(renderMessages(toSummarize));
AiMessage summary = llm.chat(summaryPrompt).aiMessage();
// 3) 重置窗口:先放摘要,再保留近期消息
tokenWindow = TokenWindowChatMemory.builder()
.maxTokens(8000, new OpenAiTokenCountEstimator("gpt-4o"))
.build();
tokenWindow.add(dev.langchain4j.data.message.SystemMessage.from(
"历史会话摘要:\n" + summary.text()));
// 重新加入近期消息
current.subList(summaryBoundary, current.size())
.forEach(tokenWindow::add);
}
}
/** 粗略估算 Token 数(生产环境建议用官方 tokenizer) */
private static int estimateTokens(List<ChatMessage> msgs) {
return msgs.stream()
.mapToInt(m -> m.text().length() / 4)
.sum();
}
private static String renderMessages(List<ChatMessage> msgs) {
StringBuilder sb = new StringBuilder();
msgs.forEach(m -> sb.append("- ").append(m.text()).append("\n"));
return sb.toString();
}
}
留心下代码里那个摘要 Prompt,它要求 LLM 必须按 5 个固定章节输出,缺失的章节也得显式标注 "无"。这就是前面说的结构化摘要的核心招数,拿结构当 checklist,逼着模型不能偷懒跳过关键信息。
如果你用 Spring AI,可以这样配一个摘要 Advisor:
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.*;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.memory.MessageWindowChatMemory;
import org.springframework.ai.chat.messages.MessageType;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.messages.SystemMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.chat.model.Response;
import org.springframework.stereotype.Service;
@Service
public class AgentWithCompression {
private final ChatClient client;
private final ChatModel chatModel;
public AgentWithCompression(ChatModel chatModel) {
this.chatModel = chatModel;
// Spring AI 内置的滑动窗口记忆
ChatMemory memory = MessageWindowChatMemory.builder()
.maxMessages(20)
.build();
this.client = ChatClient.builder(chatModel)
.defaultAdvisors(
// 对话记忆 Advisor:自动维护上下文
new MessageChatMemoryAdvisor(memory),
// 自定义摘要 Advisor:超过阈值触发压缩
new SummarizationAdvisor(chatModel, 6000)
)
.build();
}
public String chat(String sessionId, String userMsg) {
return client.prompt()
.user(userMsg)
.advisors(a -> a.param(ChatMemory.CONVERSATION_ID, sessionId))
.call()
.content();
}
}
import org.springframework.ai.chat.client.advisor.*;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.messages.*;
import org.springframework.ai.chat.client.RequestResponseSpec;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.model.ChatResponse;
import java.util.*;
import java.util.stream.Collectors;
/**
* 自定义摘要 Advisor:当上下文 Token 超过阈值时触发摘要压缩。
* 采用 "结构化摘要 + 增量合并" 思路,模拟 Factory.ai 的锚定迭代方案。
*/
public class SummarizationAdvisor implements BaseAdvisor {
private final ChatModel chatModel;
private final int tokenThreshold;
// 持久化的锚定摘要(跨多轮压缩保留)
private String anchoredSummary = "";
private static final String SUMMARY_TEMPLATE = """
你是 Agent 的记忆压缩器。请把下面这段历史对话合并到现有摘要中,
输出更新后的结构化摘要,必须包含以下章节(缺失章节标注 "无"):
## 会话意图
## 涉及的关键实体(文件 / 订单 / 接口等)
## 已做出的决策
## 当前进展
## 下一步
现有摘要:
{existing}
新增对话:
{new}
""";
public SummarizationAdvisor(ChatModel chatModel, int tokenThreshold) {
this.chatModel = chatModel;
this.tokenThreshold = tokenThreshold;
}
@Override
public AdvisedRequest before(AdvisedRequest request) {
List<Message> messages = request.messages();
int estTokens = messages.stream()
.mapToInt(m -> m.getText().length() / 4)
.sum();
if (estTokens <= tokenThreshold) {
return request;
}
// 1) 拆分:旧消息待摘要,近 6 条消息原样保留
int keepRecent = 6;
int splitIdx = messages.size() - keepRecent;
List<Message> toSummarize = messages.subList(0, splitIdx);
List<Message> toKeep = messages.subList(splitIdx, messages.size());
// 2) 调用 LLM 做增量摘要(锚定到旧摘要)
PromptTemplate pt = new PromptTemplate(SUMMARY_TEMPLATE);
String newContent = toSummarize.stream()
.map(m -> "[" + m.getMessageType() + "] " + m.getText())
.collect(Collectors.joining("\n"));
String updated = chatModel.call(pt.createMessage(Map.of(
"existing", anchoredSummary.isEmpty() ? "(空)" : anchoredSummary,
"new", newContent
)));
this.anchoredSummary = updated; // 更新锚
// 3) 重组上下文:系统摘要 + 近期消息
List<Message> compressed = new ArrayList<>();
compressed.add(new SystemMessage("历史会话摘要:\n" + anchoredSummary));
compressed.addAll(toKeep);
return AdvisedRequest.from(request).withMessages(compressed).build();
}
}
这个 SummarizationAdvisor 就是把前面讲的锚定迭代摘要和结构化章节,落到了 Spring AI 的 Advisor 机制里。生产环境还能再加一层,把 anchoredSummary 持久化到 Redis 或数据库,跨会话也能用起来。
四、方法对比与选型建议
实际项目中怎么选?给一份经验对比:
| 维度 | 摘要压缩 | 剪枝过滤 | 外部化 | 隔离 |
|---|---|---|---|---|
| 实现难度 | 中 | 低 | 中高 | 高 |
| 信息保真度 | 中(结构化高) | 低 | 高(可检索) | 高 |
| 延迟开销 | 高(要调 LLM) | 极低 | 中(检索耗时) | 低(但 Token 多) |
| 适用场景 | 长会话客服、编码 Agent | 短会话、低延迟场景 | 跨会话长期记忆 | 复杂任务拆解 |
生产环境推荐组合拳:
- 短期记忆用滑动窗口 + Token 阈值触发
- 中期记忆用结构化摘要(强制章节)+ 增量合并(锚定迭代)
- 长期记忆外部化到向量库,按需检索回来
- 复杂任务考虑多 Agent 隔离上下文
别指望单一方案解决所有问题。
五、一个关键但容易被忽视的坑
Factory.ai 的报告里有个反常识的结论:所有压缩方法在 "Artifact Trail(文件追踪)" 这个维度得分都很低(2.19 - 2.45 / 5)。
啥意思呢,Agent 压缩之后特别容易忘了自己改过哪些文件,结果就是重新读已经看过的文件,甚至做出冲突的修改。解决办法是别把文件追踪交给通用摘要,单独维护一个结构化的 "文件状态索引",每次压缩时原样保留,不走 LLM 摘要那条路。这点面试里要是能说出来,挺能体现工程深度。
面试高频追问
-
追问一:压缩后 Agent 忘了关键信息怎么办?
- 用结构化摘要强制保留关键章节
- 重要信息(文件路径、决策点)单独维护索引,不进 LLM 摘要
- 引入 Rerank + 探针式评估,定期检查压缩质量
-
追问二:什么时候触发压缩?
- 基于 Token 阈值(如用到 80%-95% 窗口时触发,Claude Code 是 95%)
- 基于轮次(每 N 轮强制压缩一次)
- 基于任务阶段(一个子任务结束后压缩这一阶段)
-
追问三:摘要用大模型还是小模型?
- 摘要任务相对简单,可以用便宜的小模型(如
gpt-4o-mini、Haiku) - 但结构化摘要、需要保留技术细节的场景,建议用能力更强的模型
- Cognition 据说还专门 fine-tune 了一个模型来做摘要,可见这步值得花心思
- 摘要任务相对简单,可以用便宜的小模型(如
-
追问四:怎么评估压缩效果?
- 不要用 ROUGE、BLEU 这类文本相似度指标,它们测不出 "能不能继续任务"
- 用 Probe-based 评估:压缩后问 Agent 具体问题(Recall / Artifact / Continuation / Decision),看能不能答对
- 关注 "完成整个任务用了多少 Token",而不是 "单次请求压了多少 Token"
常见面试变体
- "长会话 Agent 怎么管理上下文?"(本质同题,扩展到整个 Context Engineering)
- "Claude Code 的 auto-compact 原理是什么?"(结构化摘要 + 全量重生成)
- "Agent 的记忆系统怎么设计?"(短期窗口 + 中期摘要 + 长期向量库,三级架构)
- "RAG 和 Agent 记忆有什么区别?"(RAG 检索外部知识,Agent 记忆管理自身会话历史,但技术栈有重叠)
记忆口诀
五字诀:摘、剪、外、隔、表
- 摘 要压缩(Summarization):LLM 蒸馏,结构化 + 锚定迭代最稳
- 剪 枝过滤(Trimming):滑动窗口,快但粗暴
- 外 部化(Externalization):搬出窗口进向量库
- 隔 离(Isolation):多 Agent / 沙箱各管各的
- 表 示压缩(Representation):DMC、compact,模型层硬核方案
还有句反常识的,压出来多紧不算数,完成整个任务烧了多少 Token 才是真指标。
总结
Agent 记忆压缩是个系统工程,核心方法就五大类,摘要、剪枝、外部化、隔离、表示压缩。生产环境真正能打的组合是,滑动窗口管短期,结构化锚定摘要管中期,向量库管长期。面试的时候把这两个点讲透就行,一是结构化摘要为啥比自由摘要靠谱,二是锚定迭代为啥比全量重生成稳。再配上 Java 代码示例和 Probe-based 评估的思路,这道题基本就稳了。